本章探討 B-Tree 在磁碟上的具體實作細節,涵蓋三大主題:
- 組織結構:鍵與指標的關係、頁面標頭、頁面間的連結方式
- 從根到葉的遍歷:二元搜尋、麵包屑(breadcrumbs)機制與父節點追蹤
- 最佳化與維護:再平衡、右端附加、批次載入、垃圾回收
頁面標頭(Page Header)#
頁面標頭儲存用於導航、維護與最佳化的元資料,通常包含:
- 描述頁面內容與佈局的旗標(flags)
- 頁面中的 cell 數量
- 標記空閒空間的上下偏移量(lower/upper offsets)
- 其他實作特定的元資料
各資料庫的實作差異:
- PostgreSQL:儲存頁面大小與佈局版本
- MySQL InnoDB:儲存 heap record 數量、層級等
- SQLite:儲存 cell 數量與最右指標(rightmost pointer)
魔術數字(Magic Numbers)#
魔術數字是放在檔案或頁面標頭中的多位元組常數,用途包括:
- 標示該區塊確實代表一個頁面
- 指定頁面種類或版本
- 進行驗證與健全性檢查(sanity check)
例如,寫入時將十六進位的 50 41 47 45(即 ASCII 的 “PAGE”)放入標頭,讀取時比對這四個位元組即可驗證頁面是否正確載入與對齊。隨機偏移量恰好符合魔術數字的機率極低,因此比對成功幾乎可以確認偏移量正確。
兄弟連結(Sibling Links)#
某些實作會在頁面中儲存前向與後向連結,指向左右兄弟頁面。這讓我們不必回溯到父節點就能定位相鄰節點。
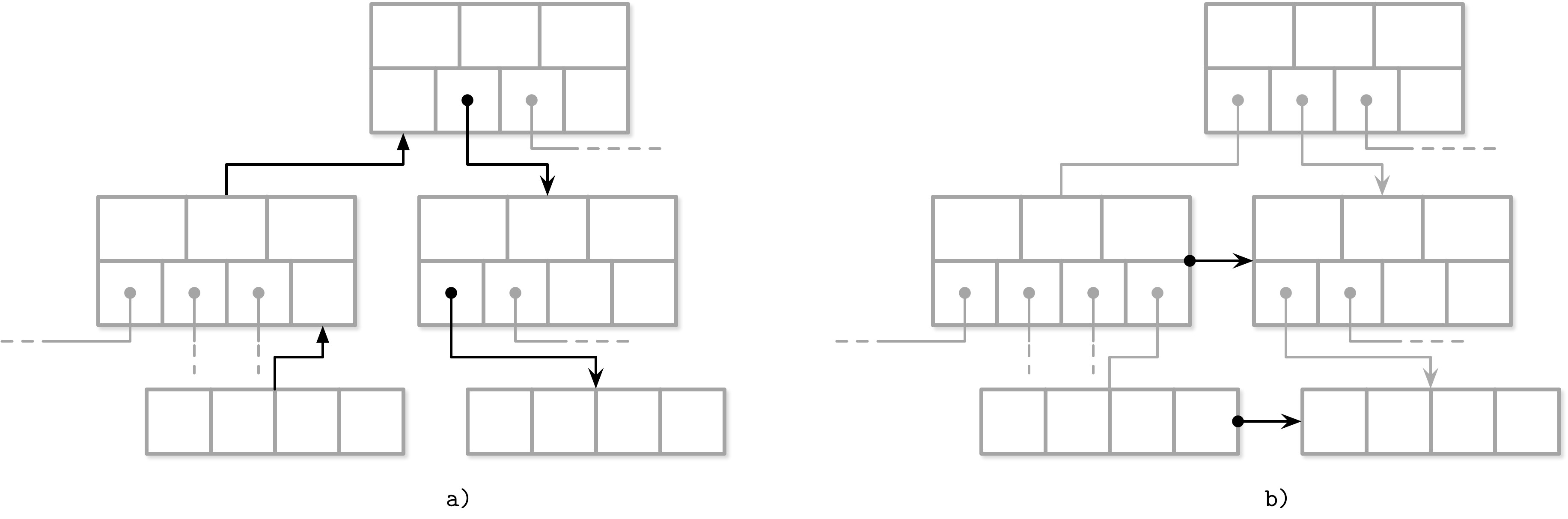
Figure 4.1: Locating a sibling by following parent links (a) versus sibling links (b)
兄弟連結的優缺點:
- 優點:可直接跟隨連結找到同層的前後節點,不需上溯到根節點
- 缺點:分裂與合併時必須額外更新兄弟節點的連結,可能需要額外的鎖定(locking)
兄弟連結在並行 B-Tree 實作中特別有用,詳見 Blink-Trees 的討論。
最右指標(Rightmost Pointers)#
B-Tree 的分隔鍵(separator key)有嚴格的不變式:子頁面指標的數量永遠比鍵的數量多一。最後一個指標沒有配對的鍵,因此需要特別處理。
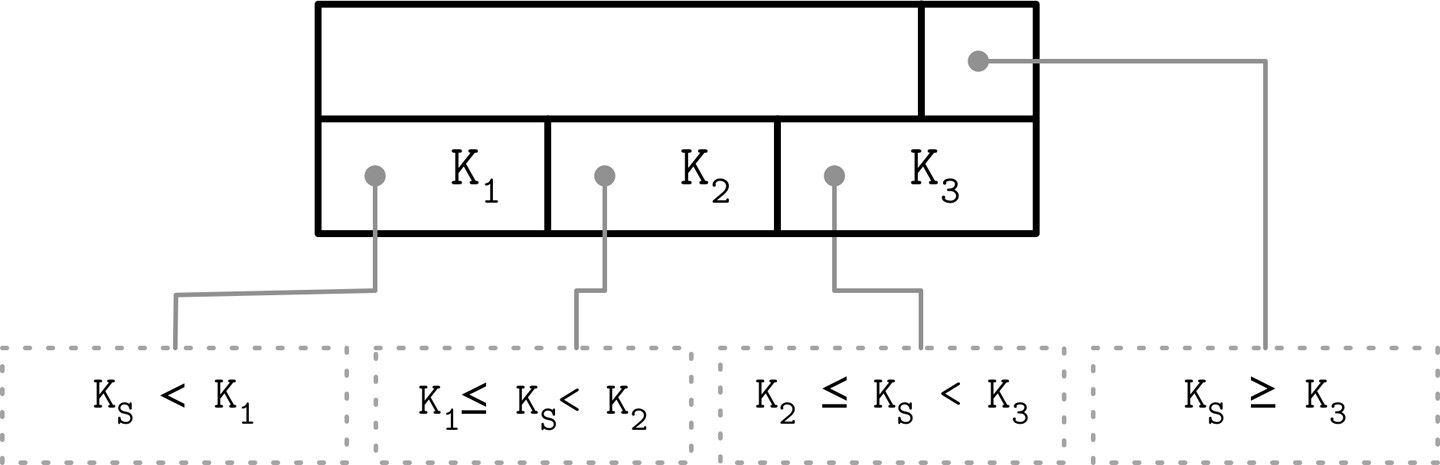
Figure 4.2: Rightmost pointer
這個多出來的指標可以儲存在標頭中(例如 SQLite 的做法)。當最右子節點被分裂時,需要重新指定最右指標:
- 被提升的鍵(promoted key)與其 cell 附加到父節點
- 指向新節點的指標取代原本的最右指標
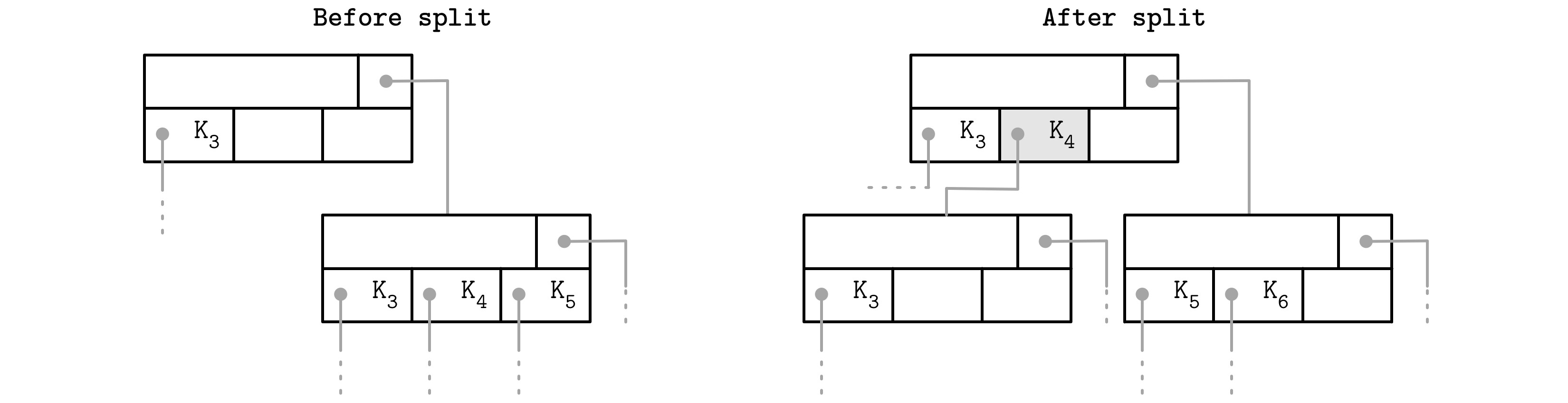
Figure 4.3: Rightmost pointer update during node split
節點上界鍵(Node High Keys)#
另一種做法是將最右指標與節點上界鍵(high key) 一起儲存在 cell 中。上界鍵代表當前節點子樹中可能存在的最大鍵值。此方法被 PostgreSQL 採用,即 Blink-Trees。
- 傳統 B-Tree:N 個鍵、N+1 個指標,K0 = -∞ 是隱含的
- Blink-Trees:額外增加一個 KN+1 鍵,指定 PN 所指子樹的鍵上界

Figure 4.4: B-Trees without (a) and with (b) a high key
這樣所有指標都能成對儲存,每個 cell 都有對應的指標,簡化了最右指標的處理,減少邊界情況。
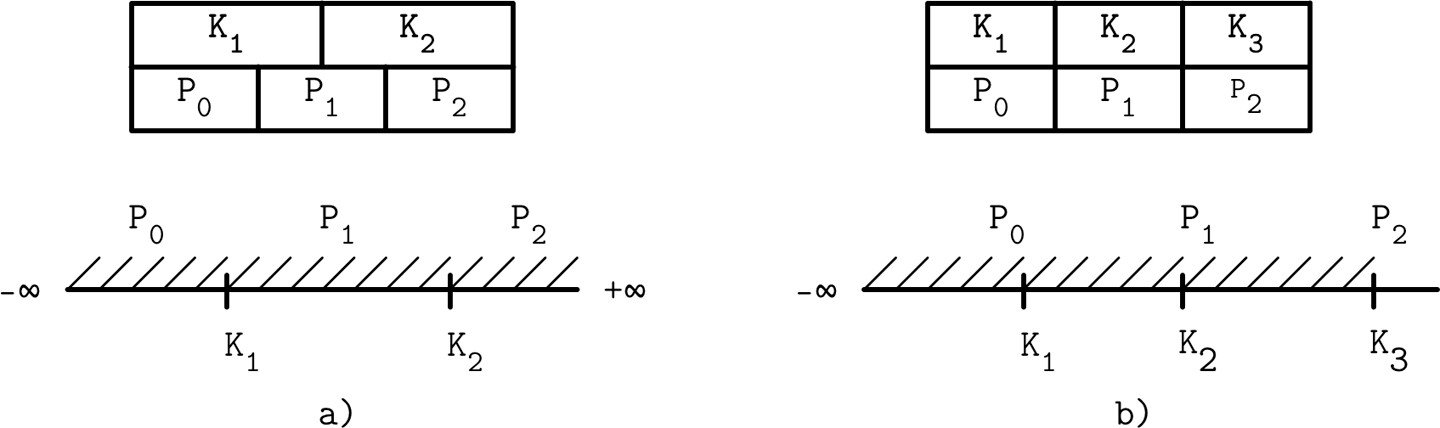
Figure 4.5: Using +∞ as a virtual key (a) versus storing the high key (b)
溢位頁面(Overflow Pages)#
節點大小與扇出值(fanout)是固定的,但變動大小的值可能導致頁面空間不足。溢位頁面的機制解決了這個問題:
- 節點以固定增量(例如 4K)擴展,分配額外的頁面並從原始頁面連結過去
- 原始頁面稱為主頁面(primary page),連結的擴展頁面稱為溢位頁面(overflow page)
運作方式:
- 大多數 B-Tree 實作限制節點內直接儲存的 payload 上限為
max_payload_size(節點大小除以扇出值) - 超過上限的部分溢出到溢位頁面
- 第一個溢位頁面的 ID 儲存在主頁面標頭中
- 需要更多溢位頁面時,以鏈結串列方式串接
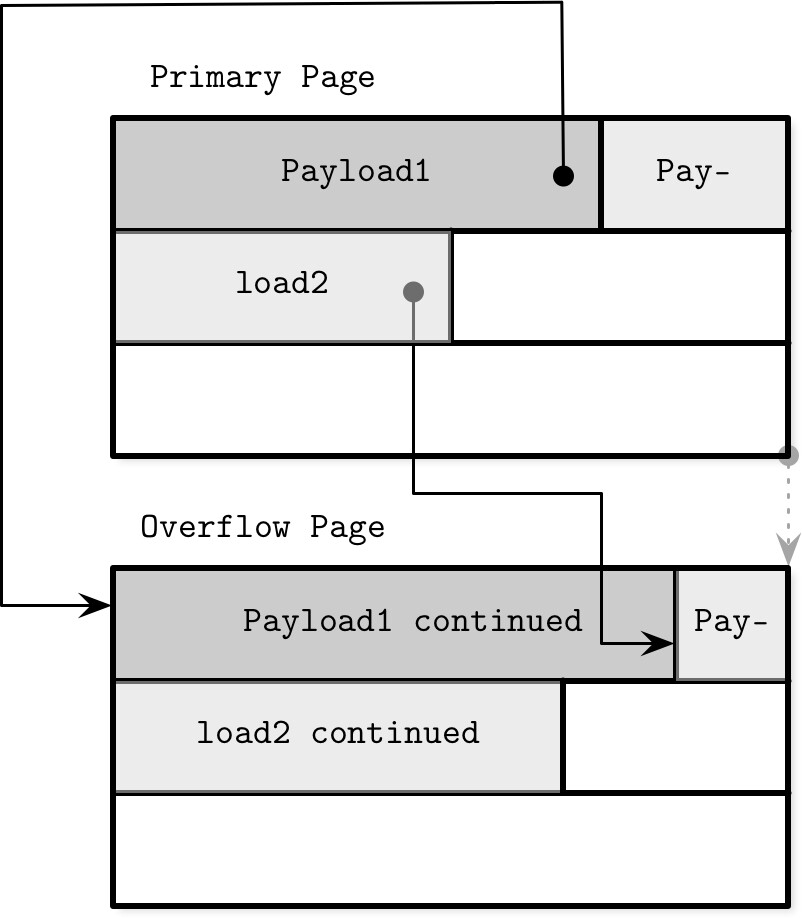
Figure 4.6: Overflow pages
溢位頁面的額外考量:
- 溢位頁面也可能產生碎片化,需要回收空間
- 鍵通常具有高基數(high cardinality),儲存部分鍵即可完成大部分比較
- 資料記錄需要定位溢位部分才能返回給使用者,但這是低頻操作
- 若所有資料記錄都超大,應考慮使用專門的 blob 儲存
二元搜尋(Binary Search)#
B-Tree 查詢時,在節點內部透過二元搜尋定位目標鍵。此演算法僅適用於已排序的資料,因此維持鍵的排序不變式至關重要。
二元搜尋的返回值:
- 正數:找到目標鍵,返回其在陣列中的位置
- 負數:目標鍵不存在,返回值的絕對值為插入點(insertion point)——第一個大於目標鍵的元素索引
在內部節點的搜尋中,多數情況不會精確匹配。我們關心的是搜尋方向:找到第一個大於目標的值,沿其子連結進入對應子樹。
使用間接指標的二元搜尋#
B-Tree 頁面中的 cell 以插入順序儲存,但邏輯順序由 cell 偏移量(cell offsets) 維護。二元搜尋的流程:
- 選取中間的 cell 偏移量
- 跟隨指標定位到對應的 cell
- 比較該 cell 的鍵與目標鍵
- 決定往左或往右繼續搜尋
- 遞迴進行直到找到目標或確定插入點
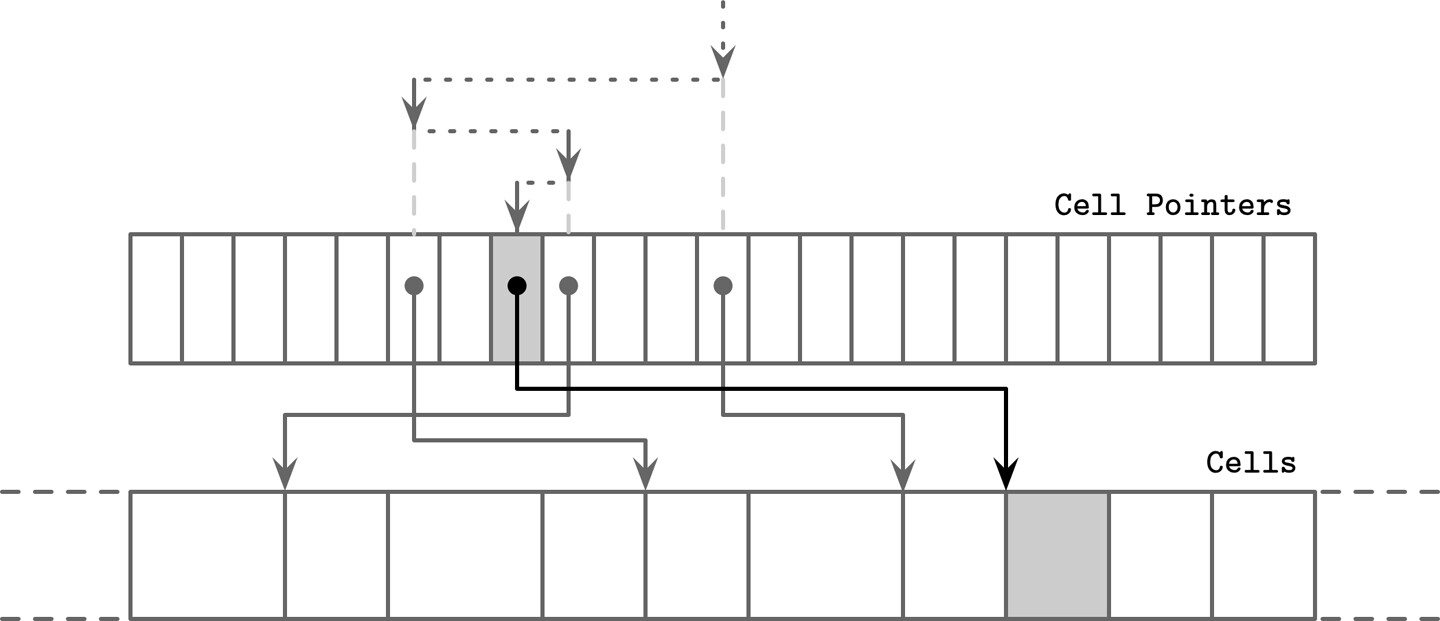
Figure 4.7: Binary search with indirection pointers
分裂與合併的傳播(Propagating Splits and Merges)#
B-Tree 的分裂與合併可能向上傳播到更高層。為此,我們需要從分裂的葉節點沿鏈路回溯到根節點。
追蹤父節點的方式:
- 父節點指標:節點中儲存指向父節點的指標。由於較低層的頁面總是從較高層引用而被載入,這些資訊甚至不需要持久化到磁碟。但分裂、合併、再平衡時都需要更新。
- 麵包屑(Breadcrumbs):記錄從根到目標葉節點路徑上經過的所有節點(見下節)。
某些實作(如 WiredTiger)使用父節點指標來進行葉節點遍歷,以避免使用兄弟指標可能導致的死鎖。
麵包屑(Breadcrumbs)#
麵包屑是一種替代父節點指標的方式,用堆疊(stack) 記錄從根到葉遍歷路徑上的節點引用。
運作流程:
- 執行可能導致結構變更的操作(插入或刪除)時,先從根遍歷到葉
- 沿途收集麵包屑(節點引用與 cell 索引)
- 若目標節點需要分裂或合併,從堆疊頂端彈出麵包屑以定位直接父節點
- 若父節點有足夠空間,附加新 cell;否則父節點也分裂
- 遞迴進行直到堆疊為空(已到達根節點)或無需更多分裂
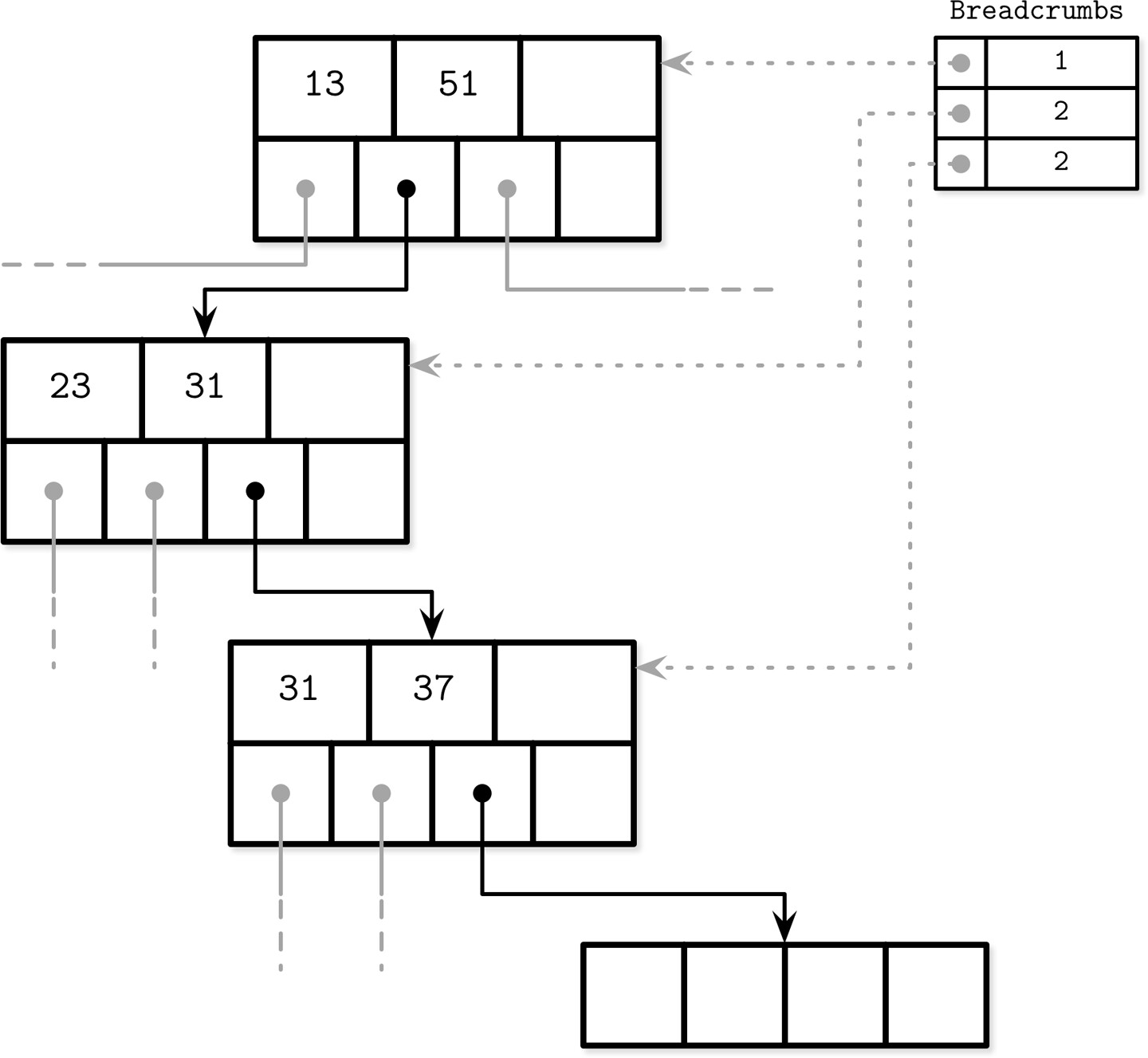
Figure 4.8: Breadcrumbs collected during lookup
PostgreSQL 將麵包屑儲存在名為
BTStack的堆疊結構中。此堆疊維護在記憶體中,不需要持久化。
再平衡(Rebalancing)#
某些 B-Tree 實作會嘗試延遲分裂與合併操作,改為在同層節點間重新分配元素,以攤提成本。
好處:
- 提高節點佔用率
- 可能減少樹的層數
- 提升搜尋效率(樹高度更小,遍歷的頁面更少)
B*-Trees 的策略:
- 持續在相鄰節點間分配資料,直到兩個兄弟都滿
- 將兩個滿節點分裂為三個節點,每個填充約 2/3
- SQLite 使用此變體
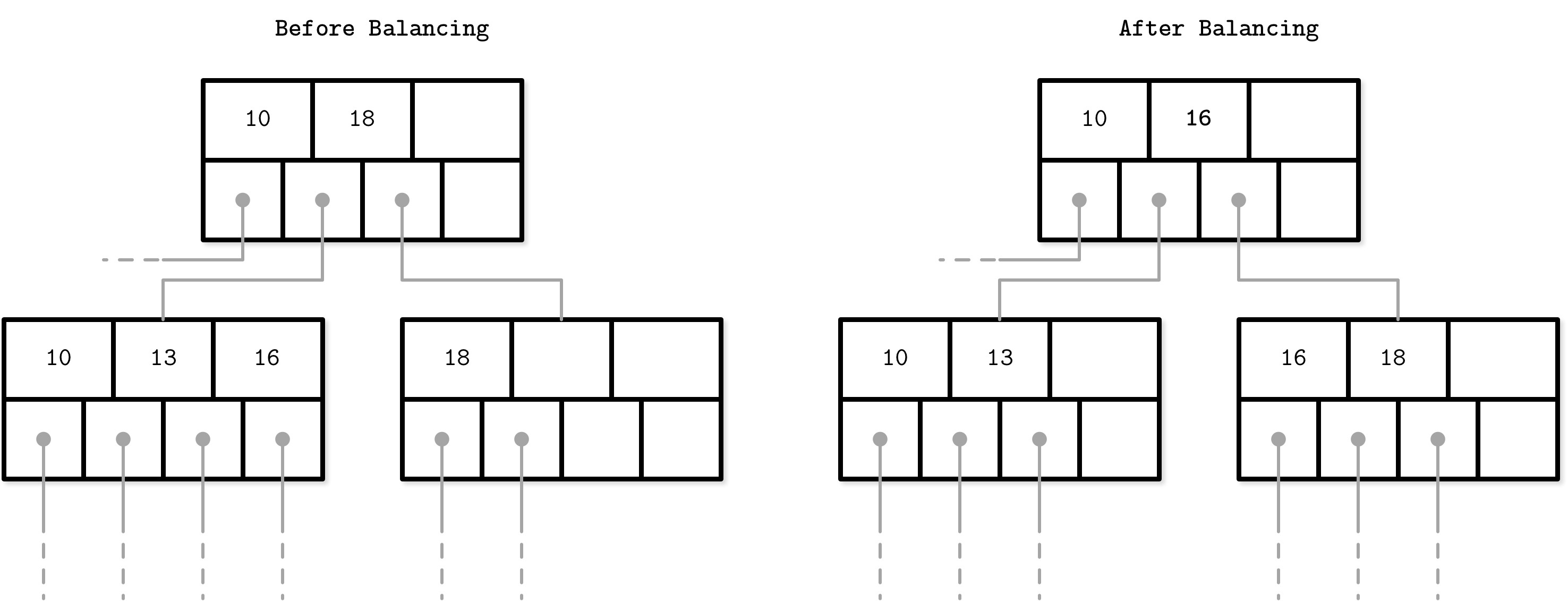
Figure 4.9: B-Tree balancing: Distributing elements between the more occupied node
再平衡的代價是修改了兄弟節點的 min/max 不變式,必須更新父節點的鍵與指標以維持正確性。SQLite 實作了 balance-siblings 演算法,其概念與此相近。
右端附加(Right-Only Appends)#
當主鍵是自動遞增的單調遞增值時,所有插入都發生在索引末端(最右葉節點),大多數分裂也發生在每層的最右節點。
各資料庫的最佳化:
- PostgreSQL(fastpath):若插入的鍵嚴格大於最右頁面的第一個鍵,且頁面有足夠空間,直接插入快取的最右葉節點,跳過整個讀取路徑
- SQLite(quickbalance):當條目插入最右端且目標節點已滿時,不做再平衡或分裂,直接分配新的最右節點並將指標加入父節點。雖然新頁面幾乎是空的,但很快就會被填滿
批次載入(Bulk Loading)#
當資料已預先排序且需要批次載入或重建樹時,可以進一步利用右端附加的概念。
批次載入的方式:
- 由下而上組建樹,逐層寫出
- 在葉層以頁面為單位寫入預排序資料(而非逐一插入元素)
- 寫完一個葉頁面後,將其第一個鍵傳播到父節點
- 所有分裂都發生在最右節點
主要優點:
- 不需要在磁碟上執行任何分裂或合併
- 建構期間只需在記憶體中保持最小的樹部分(當前填充葉節點的所有父節點)
- 不可變 B-Trees(Immutable B-Trees) 可用相同方式建立,且不需為後續修改預留空間,所有頁面可完全填滿,提升佔用率與效能
壓縮(Compression)#
儲存未壓縮的原始資料會帶來顯著的空間開銷。壓縮的核心取捨在於存取速度與壓縮比。
壓縮粒度#
- 整檔壓縮:壓縮比最佳,但更新時需重新壓縮整個檔案,不實用
- 逐頁壓縮(page-wise):頁面可獨立壓縮與解壓縮,與頁面載入/寫出耦合。但壓縮後的頁面可能只佔磁碟區塊的一部分,導致載入時讀取額外位元組
- 資料層級壓縮:按行(row-wise)或按列(column-wise)壓縮,頁面管理與壓縮解耦
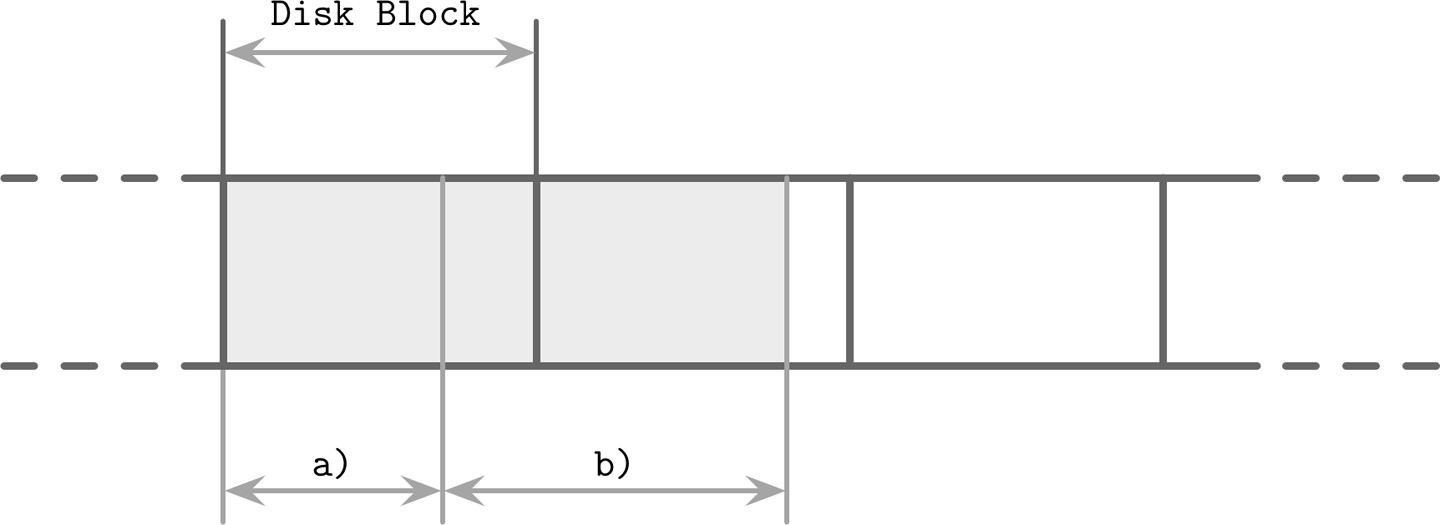
Figure 4.10: Compression and block padding
大多數開源資料庫提供可插拔的壓縮方法,常用的函式庫包括 Snappy、zLib、lz4 等。選擇壓縮演算法時需考量四個指標:
- 記憶體開銷
- 壓縮效能
- 解壓縮效能
- 壓縮比
清理與維護(Vacuum and Maintenance)#
除了使用者面對的操作,B-Tree 還需要背景程序來維護儲存完整性、回收空間、減少開銷,並保持頁面有序。
碎片化的成因#
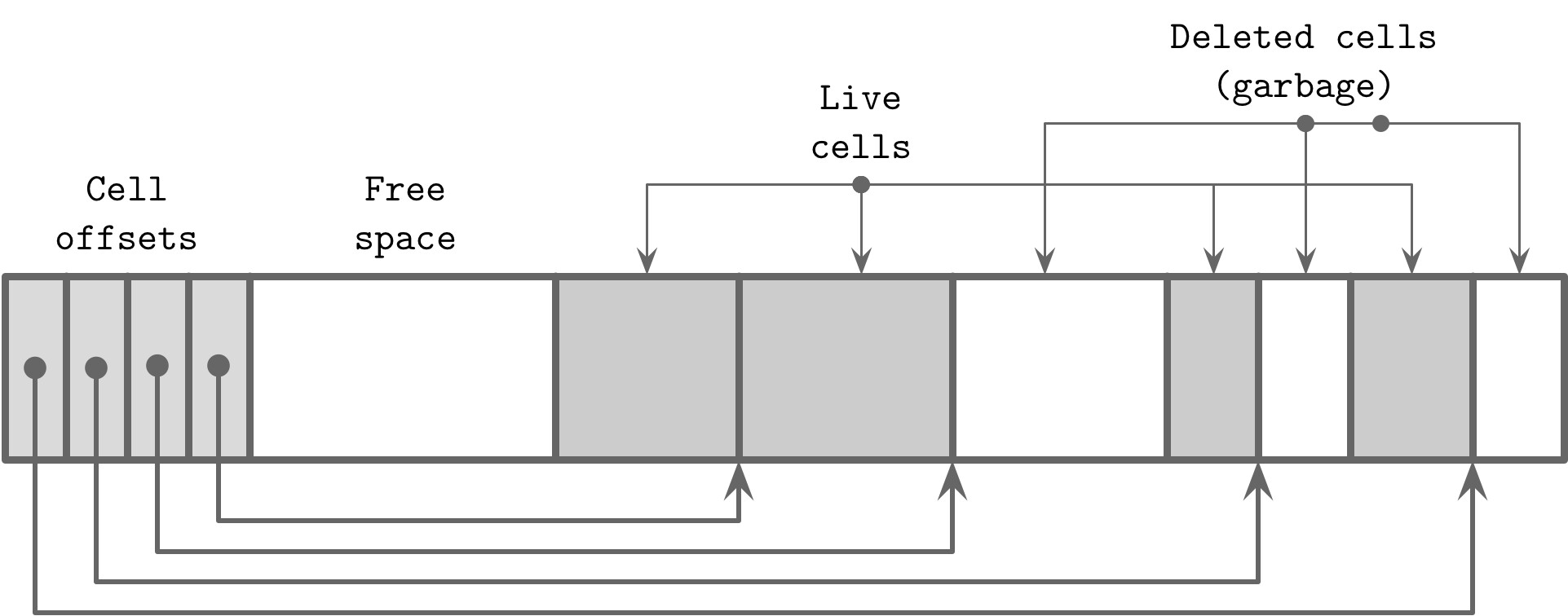
Figure 4.11: An example of a fragmented page
刪除操作:
- 僅移除標頭中的 cell 偏移量,cell 本身保持不動
- 被移除偏移量的 cell 不再可定址,內容不會出現在查詢結果中
- 釋放的位元組可能散佈在頁面各處,造成碎片化
分裂操作:
- 僅裁剪偏移量,被截斷偏移量的 cell 不再可達
- 新資料到來時會被覆寫,或由清理程序回收
更新操作:
- 主要影響葉層,不改變 cell 順序,盡量避免頁面重寫
- 可能導致同一 cell 的多個版本同時存在,只有一個是可定址的
某些資料庫依賴垃圾回收機制,將已移除和已更新的 cell 保留在原處,供多版本並行控制(MVCC) 使用。這些 cell 在並行交易完成前仍可存取,之後才被回收。某些資料庫維護追蹤幽靈記錄(ghost records) 的結構,待所有可能看到它們的交易完成後才收集。
頁面整理(Page Defragmentation)#
負責空間回收與頁面重寫的程序稱為壓實(compaction)、清理(vacuum) 或維護。
運作方式:
- 同步:寫入時若頁面沒有足夠的連續空閒空間,可同步執行以避免建立不必要的溢位頁面
- 非同步:作為獨立背景程序,走訪頁面、執行垃圾回收、重寫內容
頁面整理的具體動作:
- 回收已死 cell 佔用的空間
- 按邏輯順序重寫 cell
- 頁面可能被搬遷到檔案中的新位置
- 未使用的記憶體頁面歸還給頁面快取(page cache)
- 已可用的磁碟頁面 ID 加入空閒頁面清單(freelist)
空閒頁面清單的資訊必須持久化,以在節點當機和重啟後存活,確保空閒空間不會遺失或洩漏。例如 SQLite 維護一個未使用頁面的清單,其中 trunk pages 以鏈結串列的方式保存已釋放頁面的位址。
可定址 vs. 不可定址:
- 從根節點沿指標向下可到達的資料記錄是存活的(live / addressable)
- 不可定址的記錄是垃圾(garbage):未被任何地方引用,無法讀取或解譯
- 垃圾區域的零填充(zero-filling)通常因效能考量而被跳過,因為這些區域最終會被新資料覆寫
總結#
本章討論了磁碟上 B-Tree 實作的關鍵概念:
頁面組織:
- 頁面標頭:儲存導航、維護與最佳化所需的元資料,包括魔術數字用於驗證
- 兄弟連結:允許直接存取相鄰節點,但增加分裂/合併時的維護成本
- 最右指標與上界鍵:處理 B-Tree 中指標比鍵多一的情況,Blink-Trees 用上界鍵簡化處理
- 溢位頁面:以固定增量擴展頁面,處理變動大小與超大記錄
根到葉遍歷:
- 二元搜尋搭配間接指標:透過 cell 偏移量維護邏輯順序,在物理上以插入順序儲存的 cell 中高效搜尋
- 麵包屑機制:使用堆疊記錄遍歷路徑,支援分裂與合併的向上傳播
最佳化與維護技術:
- 再平衡:在鄰近節點間移動元素,延遲分裂與合併,提高佔用率
- 右端附加:針對單調遞增鍵的快速路徑,跳過不必要的讀取路徑
- 批次載入:從已排序資料由下而上建構樹,完全避免分裂與合併
- 壓縮:在不同粒度(檔案、頁面、資料)上壓縮以節省空間
- 垃圾回收:背景程序重寫頁面、按鍵順序排列 cell、回收不可定址 cell 的空間