概述#
在了解 B-Tree 的基本語義之後,本章深入探討 B-Tree 及其他結構在磁碟上的實際實作方式。存取磁碟與存取主記憶體的方式截然不同:
- 主記憶體:應用程式開發者透過虛擬記憶體(virtual memory)存取,不需手動管理偏移量(offset)
- 磁碟:需要透過系統呼叫(system call)存取,必須指定目標檔案中的偏移量,再將磁碟上的二進位表示法轉換成適合記憶體使用的格式
因此,高效的磁碟資料結構必須考量這種差異,設計出易於建構、修改和解讀的檔案格式。本章討論的通用原則不僅適用於 B-Tree,也適用於各種磁碟資料結構的設計。
可以把磁碟上的 B-Tree 視為一種頁面管理機制(page management mechanism):演算法必須組合與巡覽頁面,頁面及其指標必須被正確計算與放置。
動機(Motivation)#
設計檔案格式類似於在非自動記憶體管理語言(unmanaged memory model)中建立資料結構。核心差異在於:
- 記憶體中:可以隨時分配記憶體,不需擔心連續區段、碎片化或釋放問題;可使用
malloc和free - 磁碟上:必須自行處理垃圾回收(garbage collection)與碎片化(fragmentation)
- 記憶體中:處理可變長度欄位與超大資料相對簡單,可直接使用指標
- 磁碟上:需要設計二進位資料格式,考慮持久性儲存媒體的特性,並找到高效的序列化與反序列化方法
雖然作業系統和檔案系統承擔了部分責任,但實作磁碟資料結構仍需關注更多細節,且有更多潛在陷阱。
二進位編碼(Binary Encoding)#
為了在磁碟上高效儲存資料,需要使用緊湊且易於序列化/反序列化的編碼格式。由於我們無法使用 malloc 和 free,只能依賴 read 和 write,必須以不同的思維來準備和存取資料。
基本型別(Primitive Types)#
鍵(key)和值(value)具有型別(如 integer、date、string),可以序列化為原始二進位形式。
數值型別與位元組順序(Endianness):
多位元組數值需要統一使用相同的位元組順序(byte order)進行編碼和解碼:
- 大端序(Big-endian):從最高有效位元組(MSB)開始,地址由低到高依序排列
- 小端序(Little-endian):從最低有效位元組(LSB)開始,地址由低到高依序排列

Figure 3.1: Big- and little-endian byte order
例如,十六進位 32 位元整數 0xAABBCCDD,在大端序和小端序中的排列方式完全不同。RocksDB 透過平台特定的定義來識別目標平台的位元組順序,如果不匹配則會反轉位元組。
常見數值型別大小:
byte:8 bitsshort:2 bytes(16 bits)int:4 bytes(32 bits)long:8 bytes(64 bits)
浮點數(如 float 和 double)由符號位元(sign)、分數(fraction)和指數(exponent)組成,遵循 IEEE 754 標準。32 位元的 float 代表單精度值,64 位元的 double 代表雙精度值。

Figure 3.2: Binary representation of single-precision float number
序列化(serialize):將記錄轉換為可解讀的位元組序列,以便在網路傳輸或磁碟儲存時使用。反序列化(deserialize):將位元組序列轉回原始記錄。
字串與可變長度資料(Strings and Variable-Size Data)#
所有基本數值型別都是固定大小。字串和其他可變長度資料型別可以用以下方式序列化:
- Pascal 字串(UCSD String):先儲存一個表示長度的數值,後接實際資料位元組
String { size uint_16 data byte[size] } - Null 結尾字串:逐位元組讀取直到遇到結束符號
Pascal 字串的優勢:
- 可以在 O(1) 時間內取得字串長度,無需遍歷整個字串
- 可以直接切片
size個位元組並傳給字串建構子
位元打包資料(Bit-Packed Data)#
布林值(Booleans):
- 可用單一位元組表示,但這很浪費空間
- 更好的做法:將多個布林值每 8 個一組打包,每個布林只佔 1 bit
列舉型別(Enums):
- 表示為整數,常用於二進位格式和通訊協定
- 適合表示低基數(low-cardinality)的重複值
- 範例:B-Tree 節點類型
ROOT(0x00)、INTERNAL(0x01)、LEAF(0x02)
旗標(Flags):
- 打包布林與列舉的組合,表示非互斥的具名布林參數
- 只能使用 2 的冪次方值作為遮罩(mask),因為二進位中 2 的冪次方只有一個位元被設定
- 使用位元運算操作旗標:
- 設定位元:
flags |= HAS_OVERFLOW_PAGES - 取消位元:
flags &= ~HAS_OVERFLOW_PAGES - 檢查位元:
(flags & HAS_OVERFLOW_PAGES) != 0
- 設定位元:
通用原則(General Principles)#
設計檔案格式時,首先決定定址方式(addressing):
- 檔案是否要切分成相同大小的頁面
- 每個頁面由單一區塊或多個連續區塊組成
- 原地更新(in-place update)儲存結構通常使用相同大小的頁面,簡化讀寫存取
- 僅追加(append-only)儲存結構也常以頁面為單位寫入
檔案結構:
- 通常以固定大小的標頭(header)開始,可能以固定大小的尾部(trailer)結束
- 標頭和尾部存放輔助資訊,便於快速存取或用於解碼檔案其餘部分
- 檔案剩餘部分被切分成頁面
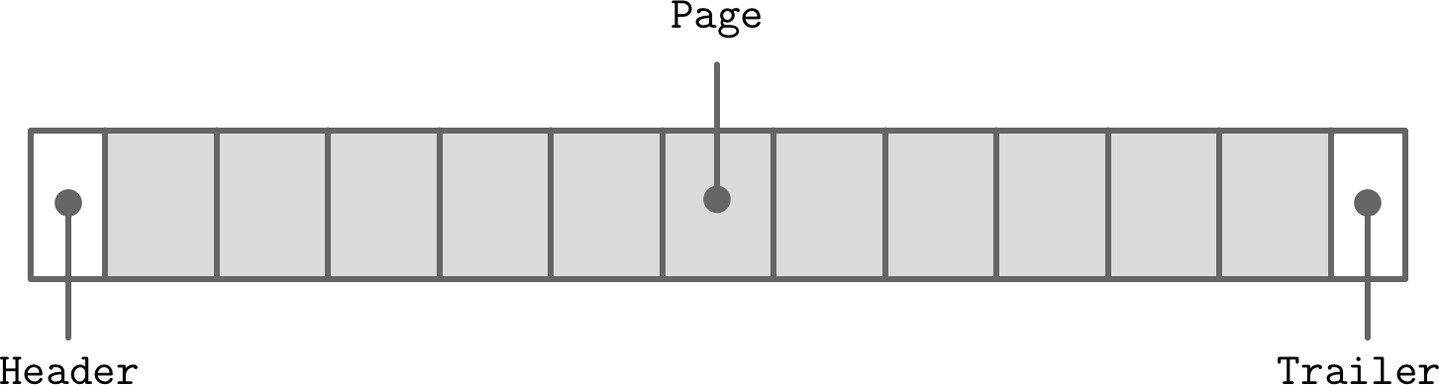
Figure 3.3: File organization
固定 Schema 的優勢:
- 許多資料庫具有固定的 schema,指定欄位的數量、順序和型別
- 不需重複寫入欄位名稱,只需使用位置識別符(positional identifier)
- 固定大小欄位放在結構前端,可變大小欄位放在後方
階層式結構:
建構複雜結構通常採用階層方式:基本型別 → 欄位 → 儲存格(cell) → 頁面 → 區段 → 區域,依需求逐層組合。資料庫檔案通常包含多個部分,並使用查找表(lookup table)指向各部分的起始偏移量。
頁面結構(Page Structure)#
資料庫系統將資料記錄儲存在資料檔和索引檔中,這些檔案被分割成固定大小的單位,稱為頁面(page)。頁面大小通常為 4 到 16 KB。
在 B-Tree 中:
- 葉節點(leaf node)存放鍵與資料記錄的配對
- 非葉節點(non-leaf node)存放鍵與指向其他節點的指標
- 每個 B-Tree 節點佔用一個或多個頁面,因此 node、page、block 這些術語常被交替使用

Figure 3.4: Page organization for fixed-size records
原始 B-Tree 論文描述了一種固定大小記錄的簡單頁面組織方式:每個頁面是三元組的串接(鍵 k、值 v、子頁面指標 p)。但這種方法有明顯缺點:
- 在最右側以外的位置插入鍵時,需要搬移元素
- 無法高效管理或存取可變大小的記錄
分槽頁面(Slotted Pages)#
儲存可變大小記錄時,最大的問題是空閒空間管理:如何回收被刪除記錄所佔的空間。
- 將大小為
n的記錄放入先前大小為m的空間中,除非m == n或能找到大小剛好為m - n的記錄,否則剩餘空間將被浪費 - 將頁面切分為固定大小的區段也會浪費空間(例如 64 bytes 的區段,除非記錄大小是 64 的倍數,否則每個區塊都會有部分浪費)
分槽頁面需要滿足的需求:
- 以最小額外開銷儲存可變大小記錄
- 回收被刪除記錄所佔的空間
- 無需關心記錄的確切位置即可參照頁面中的記錄
分槽頁面(slotted page)將頁面組織為槽(slot)或儲存格(cell)的集合,指標和儲存格分別位於頁面的兩端:
- 固定大小的標頭:存放頁面和儲存格的重要資訊
- 儲存格:大小不一,可存放鍵、指標、資料記錄等
- 指標陣列:指向儲存格的偏移量
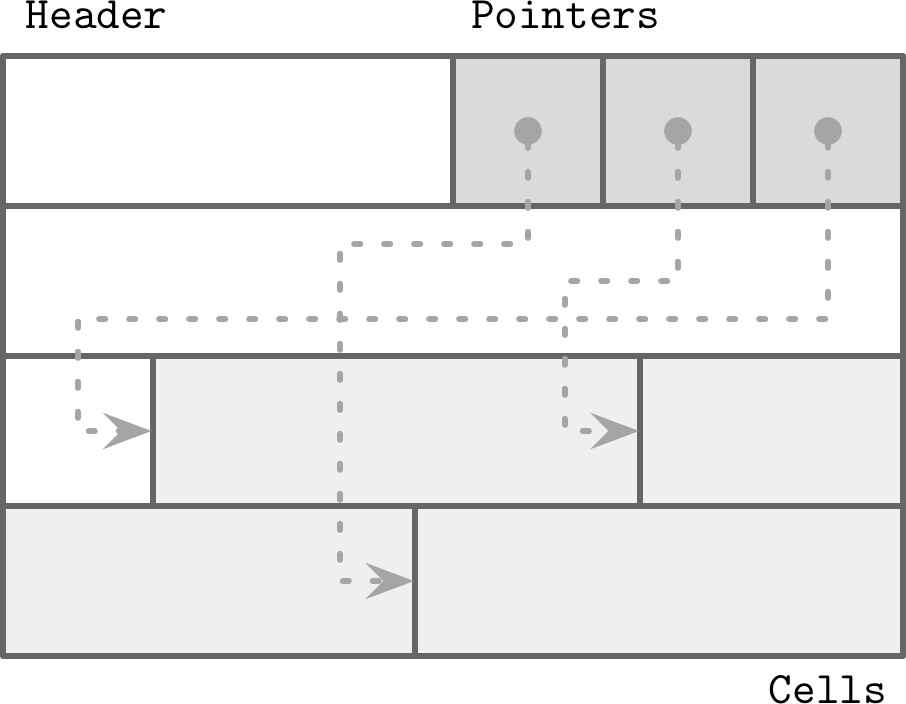
Figure 3.5: Slotted page
分槽頁面解決的問題:
- 最小額外開銷:唯一的額外開銷是存放記錄確切位置的指標陣列
- 空間回收:透過頁面重整(defragmentation)和重寫來回收空間
- 動態佈局:從頁面外部僅透過 slot ID 參照,確切位置是頁面內部的事
儲存格佈局(Cell Layout)#
使用旗標、列舉和基本型別,可以設計儲存格佈局,再將儲存格組合成頁面,由頁面組成樹。
假設同一頁面內的所有儲存格是同質的(uniform):全部只存放鍵,或全部存放鍵值對;全部是固定大小或全部是可變大小。這樣可以將描述儲存格的中繼資料(metadata)只在頁面層級儲存一次。
鍵儲存格(Key Cell)#
組成一個鍵儲存格需要:
- 儲存格類型(可從頁面中繼資料推斷)
- 鍵大小(key size)
- 子頁面 ID(child page ID)
- 鍵位元組(key bytes)
0 4 8
+----------------+---------------+-------------+
| [int] key_size | [int] page_id | [bytes] key |
+----------------+---------------+-------------+固定大小欄位放在一起,後面接著可變大小的鍵位元組,這樣可以簡化偏移量計算。
鍵值儲存格(Key-Value Cell)#
鍵值儲存格存放資料記錄而非子頁面 ID,結構類似:
- 儲存格類型、旗標
- 鍵大小、值大小
- 鍵位元組、資料記錄位元組
0 1 5 9
+--------------+----------------+------------------+
| [byte] flags | [int] key_size | [int] value_size |
+--------------+----------------+------------------+
.. + key_size .. + value_size
+--------------------+----------------------+
| [bytes] key | [bytes] data_record |
+--------------------+----------------------+頁面 ID vs. 儲存格偏移量:頁面是固定大小且由頁面快取(page cache)管理,只需儲存頁面 ID,之後透過查找表轉換為檔案中的實際偏移量。儲存格偏移量是相對於頁面起始位置的頁面本地偏移量,可以使用較小基數的整數來保持緊湊。
可變大小資料#
鍵和值不一定要固定大小,它們的位置可以從固定大小的儲存格標頭計算出來:
- 定位鍵:跳過標頭,讀取
key_size個位元組 - 定位值:跳過標頭加上
key_size個位元組,讀取value_size個位元組
將儲存格組合成分槽頁面#
在頁面中組織儲存格時,使用分槽頁面技術:
- 儲存格從頁面右側(末端)向左追加
- 儲存格偏移量/指標從頁面左側向右增長
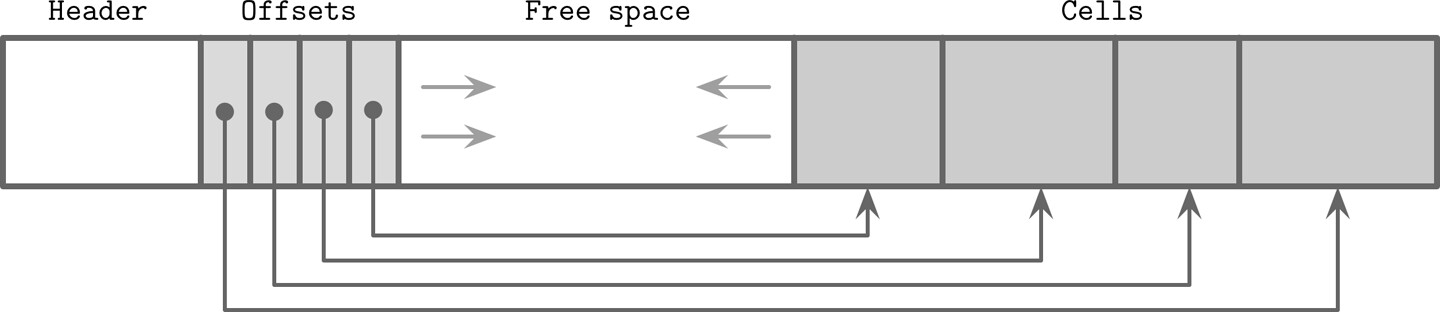
Figure 3.6: Offset and cell growth direction
關鍵設計:鍵可以不按順序插入,邏輯排序順序透過對儲存格偏移指標按鍵順序排序來維護。這種設計讓追加儲存格到頁面的工作量最小,因為儲存格在插入、更新或刪除操作中不需要被搬移。
插入範例:
依序插入 Tom 和 Leslie。儲存格按插入順序排列,但偏移量按字母順序重新排列,以便使用二分搜尋。
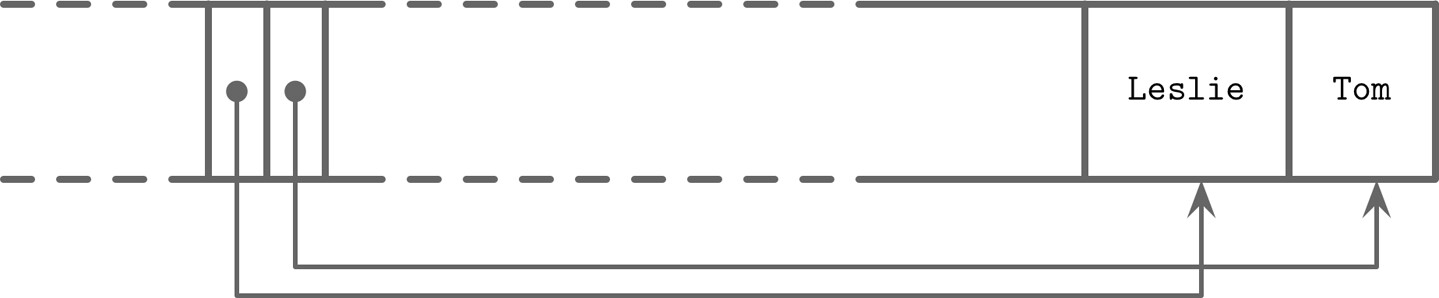
Figure 3.7: Records appended in random order: Tom, Leslie
接著插入 Ron:新資料追加在空閒空間的上界,但儲存格偏移量必須保持字典排序順序(Leslie, Ron, Tom)。插入點之後的指標向右移動,為新的 Ron 指標騰出空間。
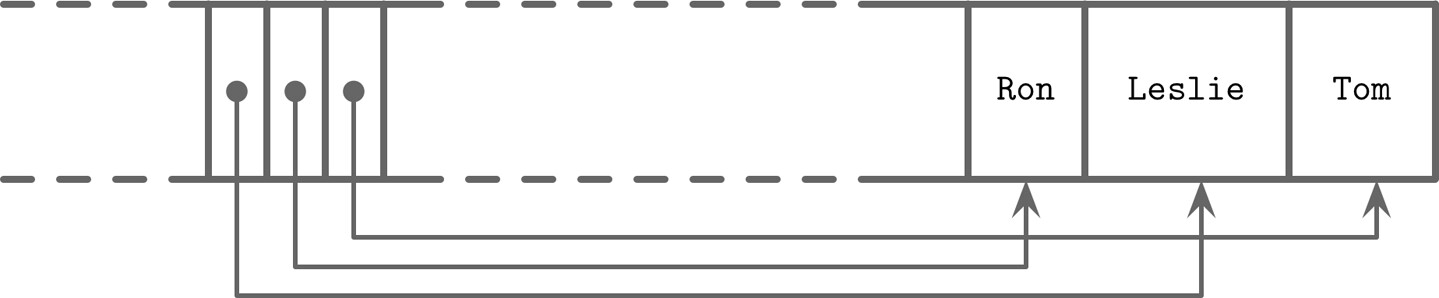
Figure 3.8: Appending one more record: Ron
管理可變大小資料(Managing Variable-Size Data)#
刪除頁面中的項目不需要實際移除儲存格並移動其他儲存格。取而代之:
- 將儲存格標記為已刪除
- 更新記憶體中的可用性清單(availability list),記錄已釋放的記憶體大小與指標
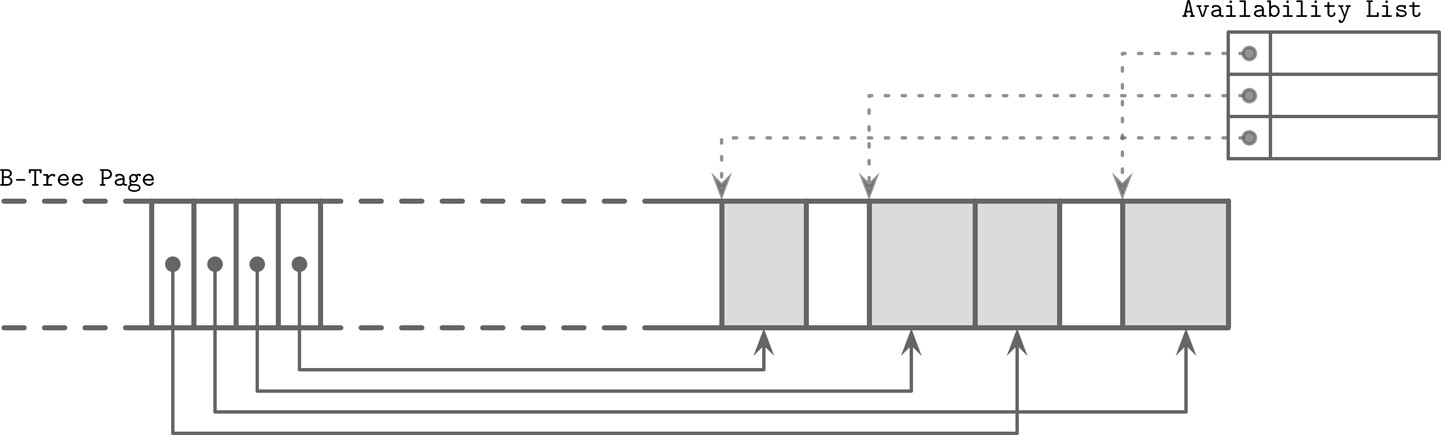
Figure 3.9: Fragmented page and availability list
插入新儲存格時,先檢查可用性清單是否有適合的區段。SQLite 稱未佔用區段為 freeblock,在頁面標頭儲存指向第一個 freeblock 的指標,並儲存頁面中可用位元組的總數,以快速判斷重整後是否能容納新元素。
空間配置策略:
- 首次適配(First fit):使用第一個夠大的區段,可能留下太小的剩餘空間而造成浪費
- 最佳適配(Best fit):尋找插入後留下最小剩餘空間的區段
如果找不到足夠的連續位元組但有足夠的碎片化位元組,則重整頁面(defragment)回收空間。若重整後仍空間不足,則建立溢位頁面(overflow page)。
為了改善局部性(locality),尤其是鍵較小時,某些實作會在葉節點層級將鍵和值分開儲存。鍵放在一起可以提升搜尋時的局部性,找到鍵後再透過對應索引找到值儲存格。
B-Tree 佈局摘要:每個節點佔用一個頁面,頁面由固定大小的標頭、儲存格指標區塊和儲存格組成。儲存格存放鍵及指向子節點或關聯資料記錄的指標。B-Tree 使用簡單的指標階層:頁面 ID 定位子節點,儲存格偏移量定位頁面內的儲存格。
版本控制(Versioning)#
資料庫系統不斷演進,二進位檔案格式也會隨之改變。大多數儲存引擎版本需要支援多種序列化格式(當前版本加上一個或多個舊版格式以維持向後相容性)。
常見的版本管理方式:
- 檔名前綴:Apache Cassandra 在檔名中使用版本前綴(如 4.0 版使用
na前綴,3.0 版使用ma前綴),不需開啟檔案就能辨識版本 - 獨立版本檔案:PostgreSQL 將版本存在
PG_VERSION檔案中 - 索引檔標頭:將版本直接儲存在檔案標頭中,標頭的一部分必須使用跨版本不變的格式編碼。某些格式使用魔術數字(magic number)來識別版本
校驗和(Checksumming)#
磁碟上的檔案可能因軟體錯誤或硬體故障而損壞。為了預防性地識別這些問題並避免將損壞資料傳播到其他子系統或節點,可使用校驗和(checksum)與循環冗餘檢查(CRC)。
各方法的保證程度:
- 校驗和(Checksum):保證最弱,無法偵測多位元損壞。通常使用 XOR 搭配奇偶校驗或加總計算
- CRC:可偵測突發錯誤(burst error,多個連續位元損壞),使用查找表和多項式除法。因為通訊網路和儲存裝置中有相當比例的故障以此方式表現
- 密碼學雜湊(Cryptographic hash):用於驗證資料是否被竄改
非密碼學雜湊和 CRC 不應用於驗證資料是否被竄改。若需防範蓄意篡改,務必使用安全的密碼學雜湊。CRC 的主要目標是確保資料未發生無意的、偶然的變更。
實務做法:
- 寫入資料前計算校驗和,連同資料一起寫入
- 讀取時重新計算校驗和,與儲存的校驗和比對
- 若不匹配,表示資料已損壞,不應使用
- 通常對每個頁面分別計算校驗和並放在頁面標頭中,而非對整個檔案計算(更精確、更實際,且損壞可被限制在單一頁面內)
總結#
本章涵蓋了磁碟上二進位資料組織的核心概念:
- 二進位編碼:如何序列化基本資料型別(整數、浮點數、字串),注意位元組順序(endianness)和位元打包(bit-packing)技術
- 檔案結構:檔案由標頭、尾部和頁面組成;頁面大小通常為 4-16 KB
- 分槽頁面(Slotted Page):解決可變大小記錄的儲存問題,儲存格從頁面尾端向前增長,指標從頁面前端向後增長,透過排序指標維護邏輯順序
- 儲存格佈局(Cell Layout):區分鍵儲存格和鍵值儲存格,固定大小欄位在前、可變大小欄位在後
- 空間管理:使用可用性清單追蹤已釋放空間,透過首次適配或最佳適配策略重用空間,必要時進行頁面重整或建立溢位頁面
- 版本控制:透過檔名前綴、獨立檔案或檔案標頭管理格式版本,確保向後相容
- 校驗和:使用 CRC 或校驗和保護頁面資料完整性,在寫入和讀取時分別計算比對
這些原則不僅適用於 B-Tree,也可推廣到各種磁碟資料結構和網路協定的二進位格式設計。