在上一章中,我們將儲存結構分為可變(mutable)與不可變(immutable)兩類。大多數可變儲存結構採用就地更新(in-place update)機制:在插入、刪除或更新時,直接在目標檔案中修改資料記錄的位置。
在眾多儲存結構中,B-Tree 是最受歡迎的一種。許多開源資料庫系統都以 B-Tree 為基礎,多年來已證明它能涵蓋絕大多數使用情境。B-Tree 並非近代發明,早在 1971 年由 Rudolph Bayer 和 Edward M. McCreight 提出,到 1979 年已出現大量變體。
在深入 B-Tree 之前,我們先來理解為什麼傳統的搜尋樹(如 Binary Search Tree、2-3-Tree、AVL Tree)不適合磁碟儲存。
二元搜尋樹(Binary Search Tree)#
二元搜尋樹(BST) 是一種排序的記憶體內資料結構,用於高效的鍵值查找。BST 由多個節點組成,每個節點包含:
- 一個鍵(key)
- 與該鍵關聯的值(value)
- 兩個子節點指標(左子節點與右子節點)
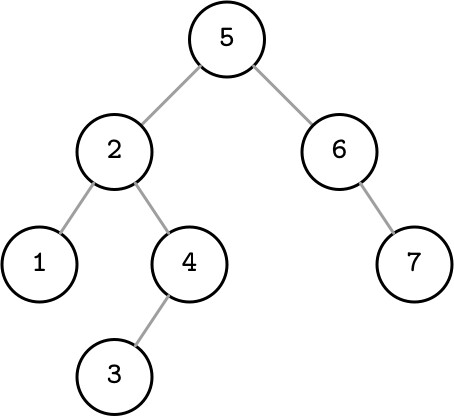
Figure 2.1: Binary search tree
每個節點將搜尋空間分為左右子樹:節點的鍵大於左子樹中所有鍵,且小於右子樹中所有鍵。
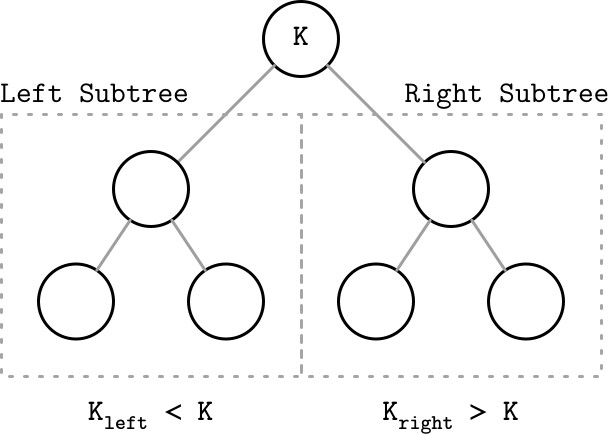
Figure 2.2: Binary tree node invariants
- 沿著根節點的左指標一路走到葉節點,可以找到樹中最小的鍵
- 沿著右指標則找到最大的鍵
- 搜尋從根節點開始,如果在較高層就找到目標鍵,可以提前結束
樹的平衡(Tree Balancing)#
插入操作沒有特定順序,可能導致樹不平衡——其中一個分支遠長於另一個。最壞情況下會形成病態樹(pathological tree),退化為類似鏈結串列的結構,複雜度從期望的 O(log2 N) 降級為 O(N)。
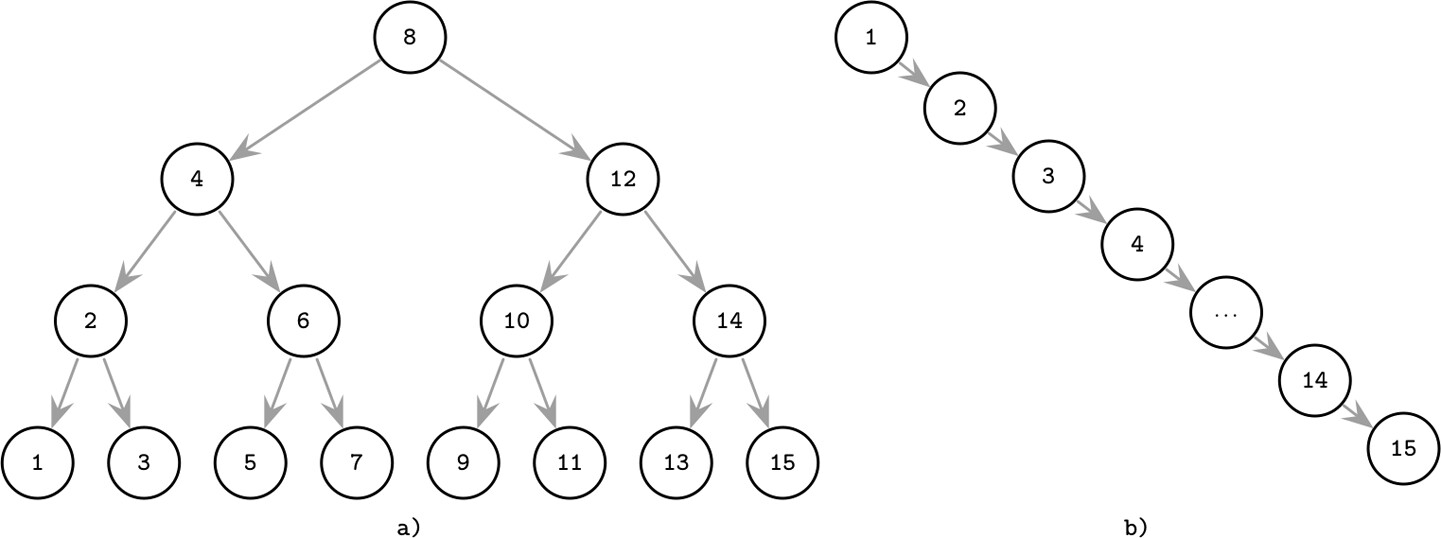
Figure 2.3: Balanced (a) and unbalanced or pathological (b) tree examples
平衡樹的定義:高度為 log2 N(N 為總元素數),且任意兩個子樹的高度差不超過 1。在平衡樹中,每次選擇左或右子節點都能將搜尋空間減半,查找複雜度為 O(log2 N)。
保持平衡的方法之一是在每次新增或移除節點後執行旋轉(rotation)。當某個分支不平衡時(連續兩個節點只有一個子節點),可以圍繞中間節點進行旋轉。中間節點稱為旋轉樞紐(rotation pivot),被提升一層,而其父節點變成它的子節點。
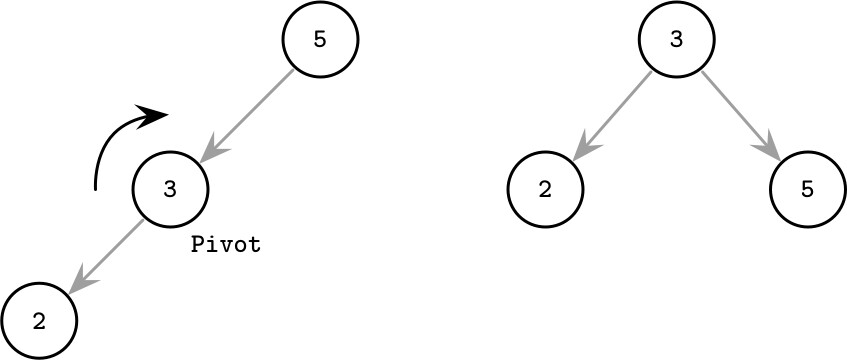
Figure 2.4: Rotation step example
為何 BST 不適合磁碟儲存#
將 BST 用於磁碟儲存會面臨幾個問題:
- 局部性差(locality):元素以隨機順序添加,新節點不保證寫在父節點附近,子節點指標可能跨越多個磁碟頁面
- 樹高過大:BST 的 fanout 僅為 2,高度為 log2 N,每次查找需要 O(log2 N) 次磁碟搜尋
- 頻繁平衡:低 fanout 導致需要頻繁的平衡操作,涉及節點重定位和指標更新
適合磁碟的樹結構需要兩個關鍵性質:高 fanout(提升相鄰鍵的局部性)和低高度(減少遍歷時的磁碟搜尋次數)。Fanout 與高度成反比:fanout 越高,每個節點能容納越多子節點,樹的高度就越低。
磁碟儲存結構#
並非每種滿足空間和複雜度要求的資料結構都適合磁碟儲存。磁碟資料結構必須考慮持久性媒體的限制。
硬碟(HDD)#
- 在旋轉式硬碟上,隨機讀取的成本很高,因為需要磁碟旋轉和磁頭移動
- 一旦磁頭定位完成,連續讀寫(sequential I/O)相對便宜
- 最小傳輸單位為磁區(sector),大小通常為 512 bytes 至 4 KB
- 磁頭定位是 HDD 最昂貴的操作,這也是連續 I/O 被推崇的原因
固態硬碟(SSD)#
SSD 沒有機械零件,其內部階層結構為:
- 記憶體單元(cell)→ 字串(string,32-64 cells)→ 陣列(array)→ 頁面(page,2-16 KB)→ 區塊(block,64-512 pages)→ 平面(plane)→ 晶粒(die)
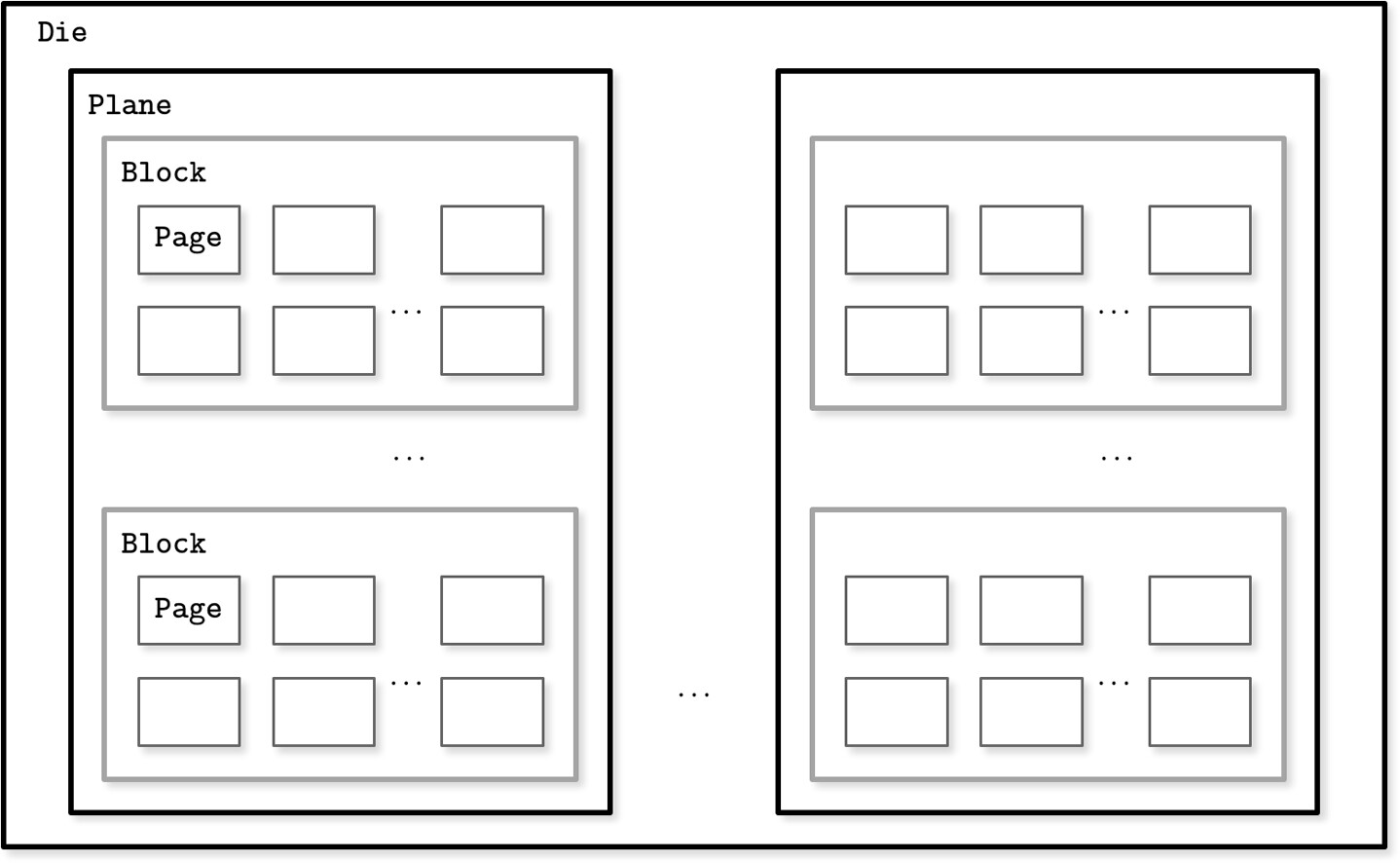
Figure 2.5: SSD organization schematics
關於 SSD 的重要特性:
- 最小讀寫單位是頁面(page)
- 只能寫入已清空的記憶體單元
- 最小抹除單位是區塊(block),又稱 erase block
- Flash Translation Layer(FTL) 負責頁面 ID 到實體位置的映射、追蹤頁面狀態,以及垃圾回收
- SSD 的隨機與連續讀取延遲差異不如 HDD 大,但仍因預取和內部平行處理而存在差異
無論 HDD 或 SSD,存取都是以區塊為單位(block-wise)。作業系統提供區塊裝置抽象(block device abstraction),讀取單一字元也會讀取整個區塊。設計磁碟資料結構時必須考量這個限制。
磁碟結構的設計原則#
- 磁碟操作的最小單位是區塊,跟隨指標到區塊內的特定位置需要讀取整個區塊
- 磁碟上的「指標」語義與記憶體中不同,需要手動管理資料佈局,計算目標位址
- 應盡量減少跨頁指標的數量和跨度,避免建立長的依賴鏈
磁碟結構的核心優化方向:
- 提升局部性(locality)
- 優化結構的內部表示
- 減少跨頁指標的數量
分頁式二元樹(Paged Binary Trees)#
將二元樹的節點按照分頁方式分組(如下圖),可以改善局部性問題:查找下一個節點時,只需要在已讀取的頁面內跟隨指標。但節點與指標之間仍有額外開銷,且平衡操作需要頁面重組和指標更新。
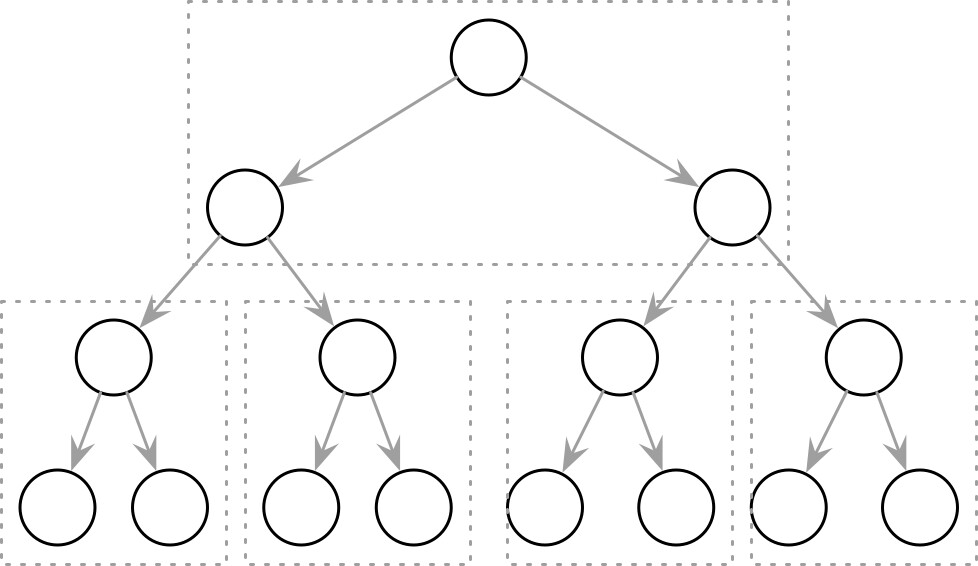
Figure 2.6: Paged binary trees
B-Tree#
B-Tree 可以類比為圖書館的大型目錄室:先選對的櫃子,再選對的架子,然後對的抽屜,最後在卡片中瀏覽找到目標。B-Tree 建立了一個導航層級結構,幫助快速定位搜尋項目。
與 BST 相比,B-Tree 具有更高的 fanout(每個節點有更多子節點)和更低的高度。
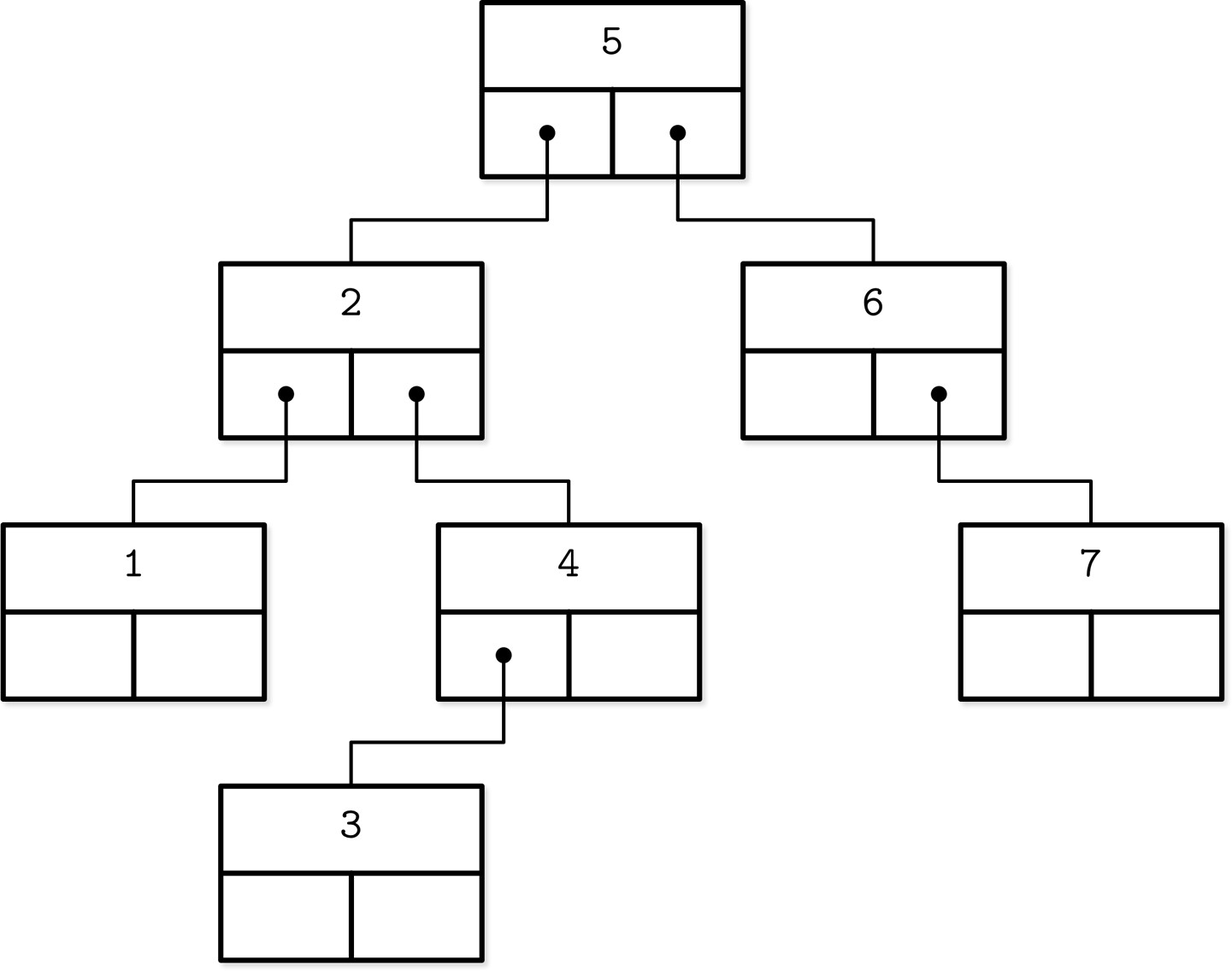
Figure 2.7: Binary tree, 2-3-Tree, and B-Tree nodes side by side

Figure 2.8: Alternative representation of a binary tree
B-Tree 的核心特性:
- 節點內的鍵以排序方式儲存,可使用二元搜尋定位目標鍵
- 查找複雜度為對數級別:在 40 億筆資料中查找只需約 32 次比較
- 由於每個節點儲存數十到數百個項目,每次層級跳躍只需一次磁碟搜尋
- 支援點查詢(point query,等值查詢)和範圍查詢(range query,比較查詢)
B-Tree 階層結構#
B-Tree 由多個節點組成,每個節點最多持有 N 個鍵和 N + 1 個子節點指標。節點分為三類:
- 根節點(Root node):沒有父節點,是樹的頂端
- 葉節點(Leaf nodes):最底層節點,沒有子節點
- 內部節點(Internal nodes):連接根節點與葉節點,通常有多於一層
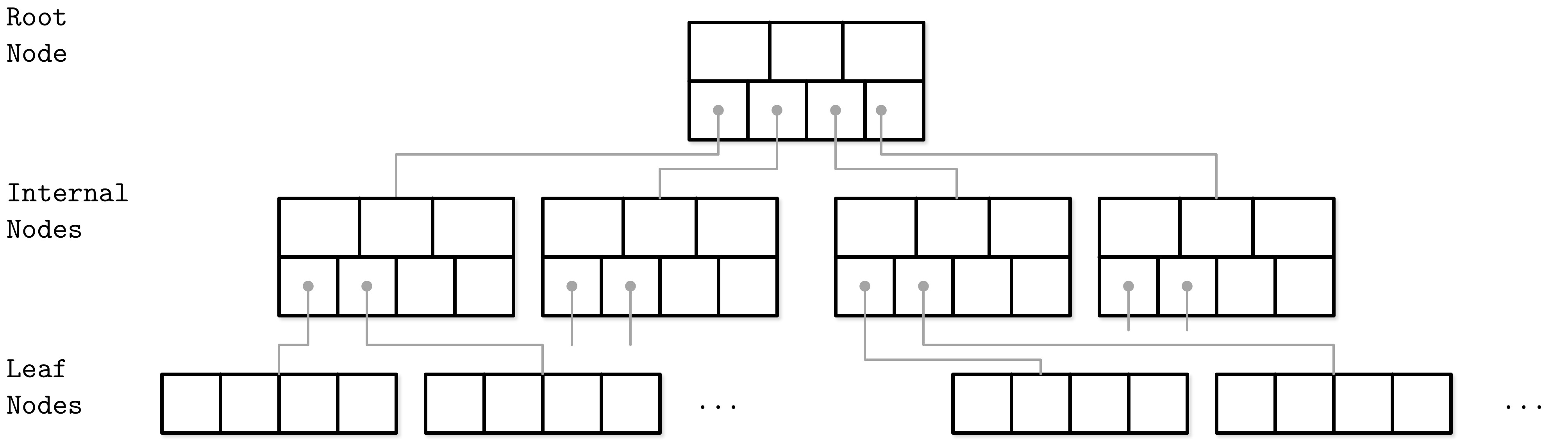
Figure 2.9: B-Tree node hierarchy
由於 B-Tree 是一種頁面組織技術(page organization technique),節點(node)與頁面(page)常被交替使用。
節點容量與實際持有鍵數的比例稱為佔用率(occupancy)。B-Tree 的特徵在於其 fanout——每個節點儲存的鍵數。高 fanout 有助於:
- 攤銷維持樹平衡所需的結構變更成本
- 減少磁碟搜尋次數(鍵和子節點指標儲存在同一或連續區塊中)
- 當節點滿或接近空時,觸發分裂(split)和合併(merge)操作
B+-Tree 與 B-Tree 的區別:本書使用「B-Tree」作為整個資料結構家族的統稱,更精確的名稱是 B+-Tree。B-Tree 允許在任何層級儲存值(根、內部、葉節點),而 B+-Tree 只在葉節點儲存值,內部節點僅存放用於導引搜尋的分隔鍵(separator key)。B+-Tree 已成為主流實作,例如 MySQL InnoDB 的 B-tree 實際上就是 B+-Tree。
分隔鍵(Separator Keys)#
儲存在 B-Tree 節點中的鍵稱為索引項目(index entry)、分隔鍵(separator key)或分隔單元(divider cell),它們將樹分割成持有對應鍵範圍的子樹。
分隔鍵的指標規則:
- 第一個指標指向持有所有小於第一個鍵的項目的子樹
- 最後一個指標指向持有所有大於等於最後一個鍵的項目的子樹
- 其他指標指向兩個相鄰鍵之間的子樹:Ki-1 <= Ks < Ki
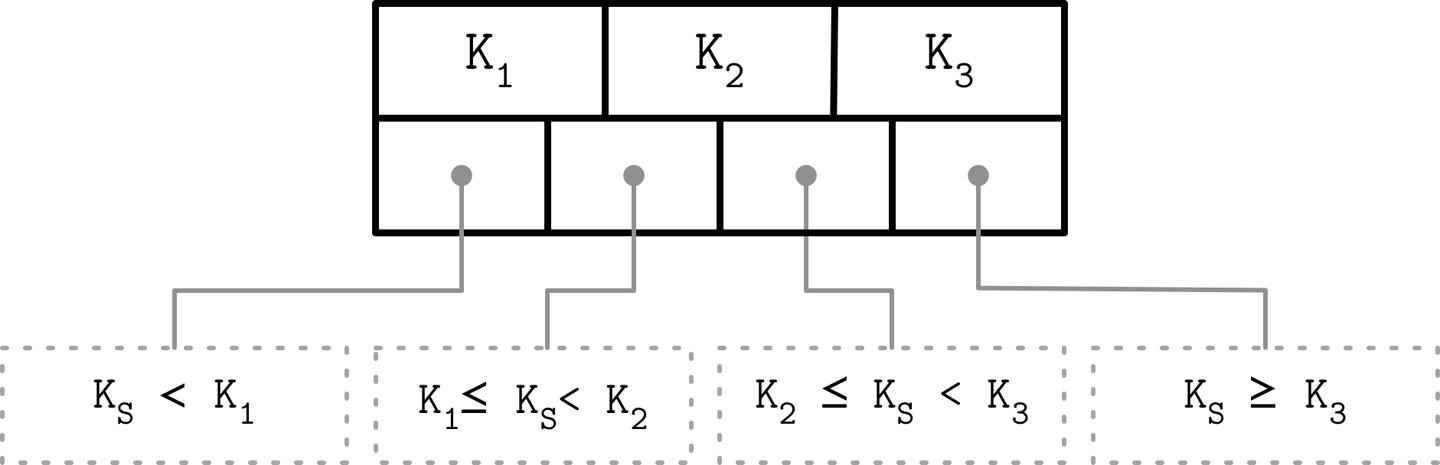
Figure 2.10: How separator keys split a tree into subtrees
關於分隔鍵的重要特性:
- 某些 B-Tree 變體在葉節點層有兄弟節點指標(sibling pointers),簡化範圍掃描,避免回到父節點尋找下一個兄弟。有些實作使用雙向指標,形成雙向鏈結串列,支援反向迭代
- B-Tree 是從底向上建構的(不同於 BST 的從頂向下):葉節點數量增長帶動內部節點和樹高增加
- B-Tree 預留額外空間給未來的插入和更新,因此儲存利用率可低至 50%,但通常遠高於此
B-Tree 查找複雜度#
B-Tree 查找複雜度可以從兩個角度理解:
| 角度 | 複雜度 | 說明 |
|---|---|---|
| 區塊傳輸次數 | O(logN M) | N 為每節點鍵數,M 為總項目數。每層跟隨子節點指標將搜尋空間縮減 N 倍,最多存取 logN M 個頁面,等於樹高 h |
| 比較次數 | O(log2 M) | 每個節點內使用二元搜尋,每次比較將搜尋空間減半 |
B-Tree 查找演算法#
查找過程是從根到葉的單次遍歷,目標是找到目標鍵或其前驅(predecessor):
- 從根節點開始,使用二元搜尋比較目標鍵與節點中的鍵
- 找到第一個大於目標值的分隔鍵,定位到對應的子樹
- 跟隨指標到下一層,重複搜尋過程
- 到達葉節點後,找到目標鍵或確認其不存在
查找結果的用途:精確匹配用於點查詢、更新和刪除;前驅查找用於範圍掃描和插入。範圍掃描時,從最近的鍵值對開始,沿兄弟指標迭代直到範圍結束。
B-Tree 節點分裂(Node Splits)#
當目標葉節點空間不足時,節點發生溢出(overflow),必須分裂為兩個節點。觸發分裂的條件:
- 葉節點:可容納 N 個鍵值對,再插入一個會超過容量 N
- 非葉節點:可容納 N + 1 個指標,再插入一個會超過容量 N + 1
分裂步驟:
- 分配一個新節點
- 將分裂節點的一半元素複製到新節點
- 將新元素插入到對應的節點
- 在父節點中新增分隔鍵和指向新節點的指標(鍵被「提升」promoted)
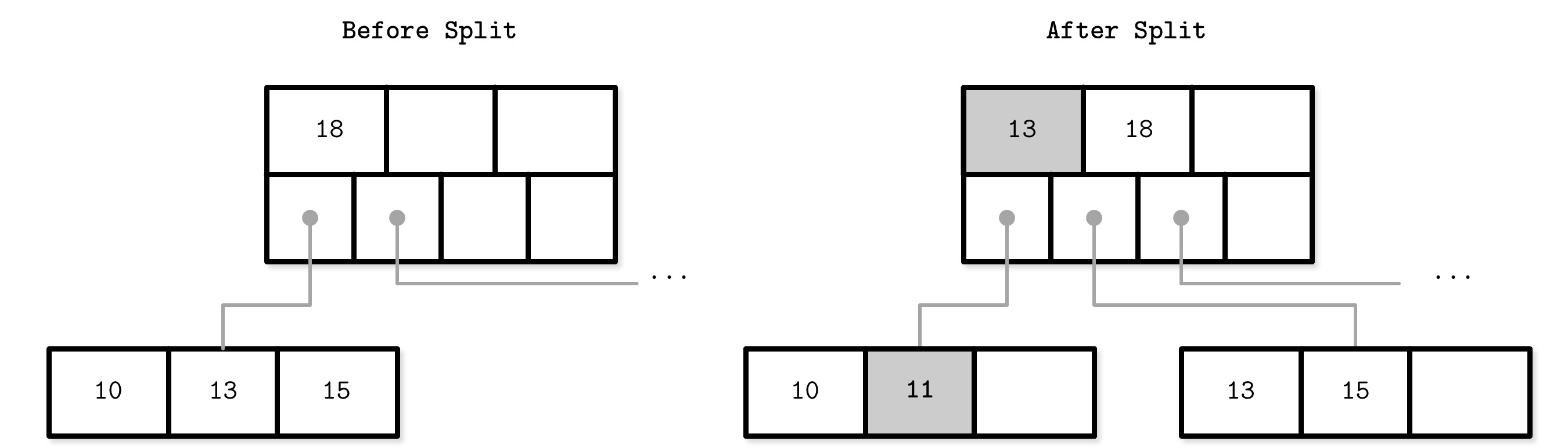
Figure 2.11: Leaf node split during the insertion of 11
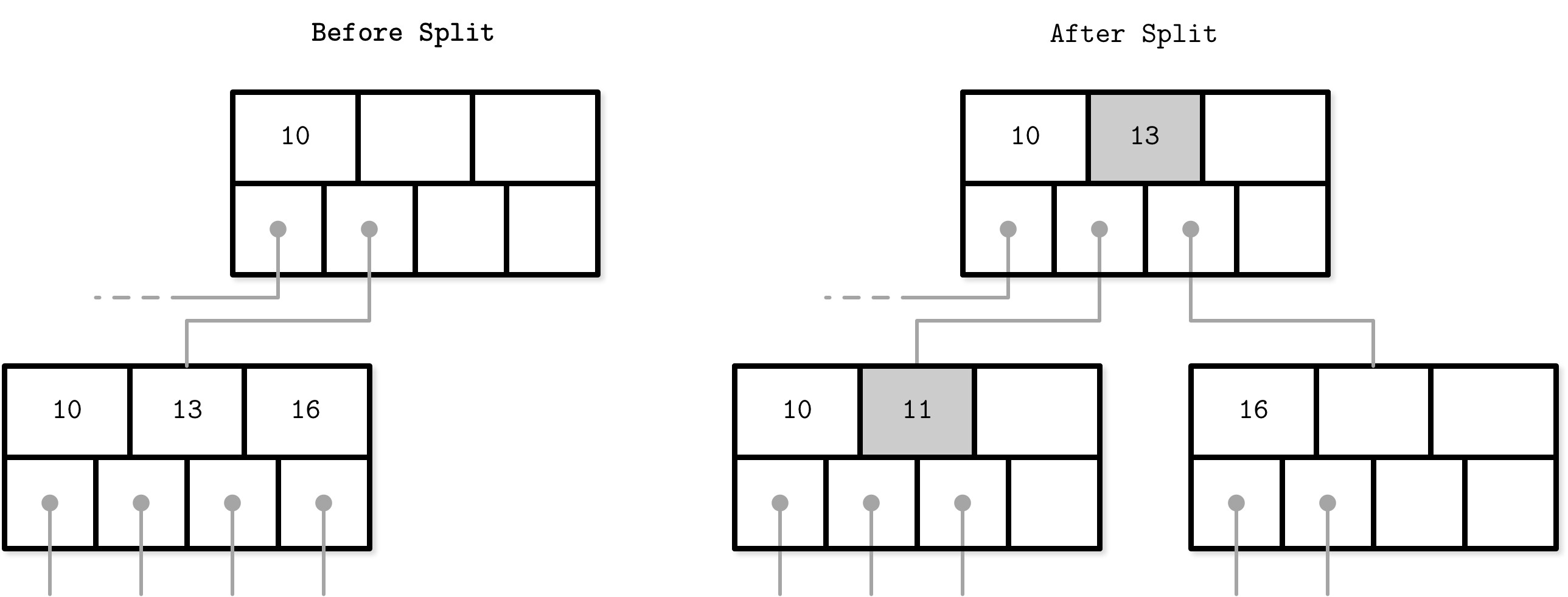
Figure 2.12: Nonleaf node split during the insertion of 11
分裂的關鍵行為:
- 分裂在分裂點(split point / midpoint)進行,分裂點之後的元素轉移到新節點
- 如果父節點也滿了,分裂會遞迴向上傳播,最遠可達根節點
- 當根節點分裂時,會建立新的根節點,樹高增加一層
- 在葉節點和內部節點層,樹只會水平擴展
- 分裂完成後,依據分隔鍵不變式選擇正確的節點完成插入:插入鍵小於提升鍵則插入原節點,否則插入新節點
B-Tree 節點合併(Node Merges)#
刪除操作先定位目標葉節點,移除鍵和對應的值。當相鄰節點的值太少(佔用率低於閾值)時,發生下溢(underflow),需要將兄弟節點合併。
合併條件:
- 葉節點:可容納 N 個鍵值對,兩個相鄰節點的鍵值對總和 <= N
- 非葉節點:可容納 N + 1 個指標,兩個相鄰節點的指標總和 <= N + 1
如果兩個相鄰節點的內容無法放入單一節點,則不合併,而是進行重新平衡(rebalancing),在節點間重新分配鍵以恢復平衡。
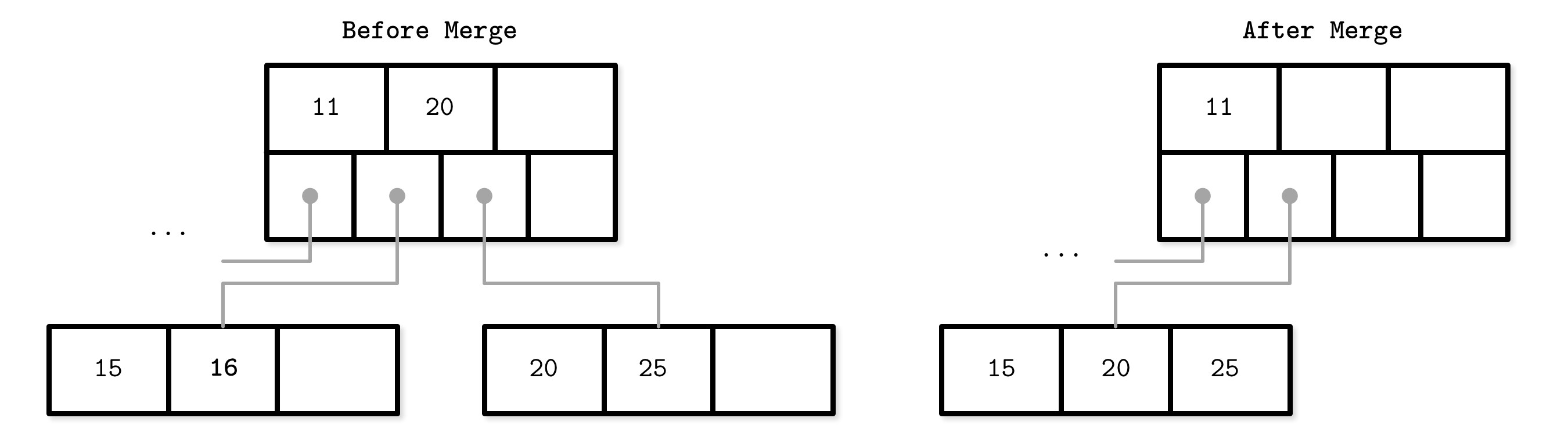
Figure 2.13: Leaf node merge
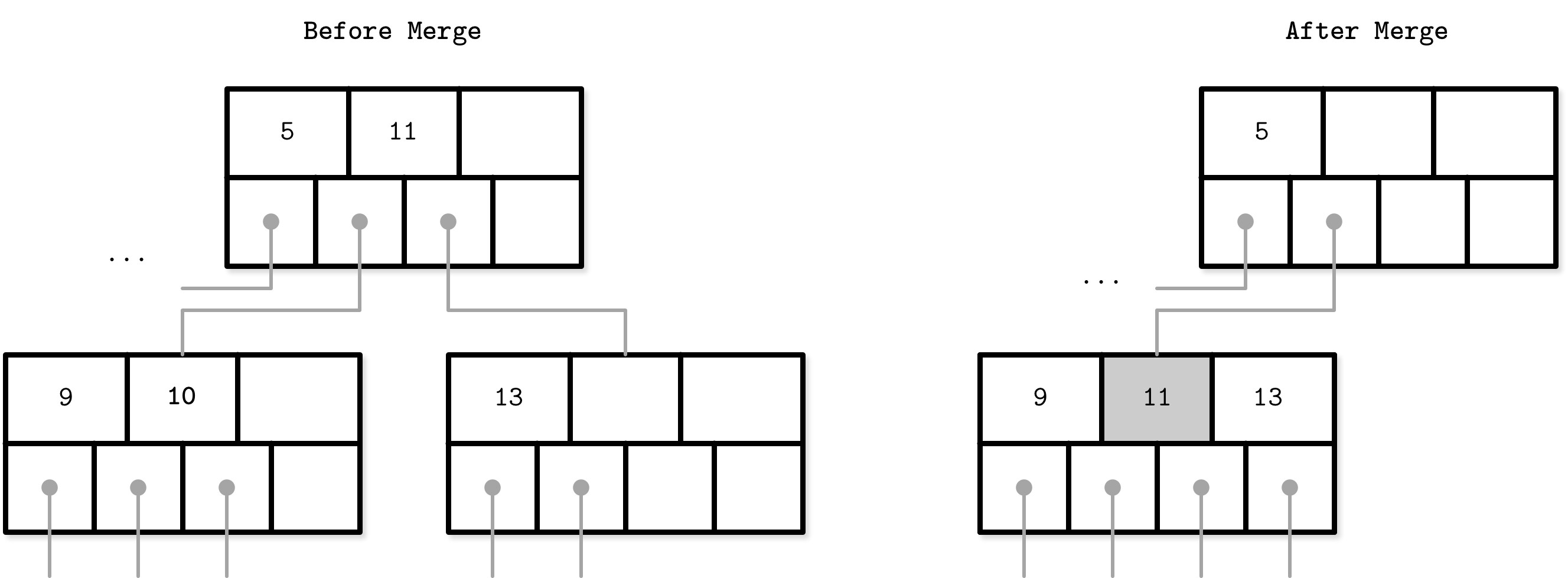
Figure 2.14: Nonleaf node merge
合併步驟(假設元素已移除):
- 將右節點的所有元素複製到左節點
- 從父節點中移除右節點的指標(非葉節點合併時需要降級 demote 分隔鍵)
- 移除右節點
合併也可以遞迴傳播到根節點層級。為了減少分裂和合併的頻率,常見的技術是重新平衡(rebalancing)。
總結#
本章從為什麼需要專門的磁碟儲存結構出發,說明了 BST 雖然在複雜度上有類似特性,但由於低 fanout 和頻繁的平衡操作(導致大量節點重定位和指標更新),不適合用於磁碟。B-Tree 透過以下方式解決了這些問題:
- 高 fanout:每個節點儲存更多項目,提升局部性
- 低高度:減少磁碟搜尋次數
- 較少的平衡操作:分裂和合併在節點滿或過空時才觸發
B-Tree 的核心操作:
- 查找:從根到葉的單次遍歷,每層使用二元搜尋
- 插入:定位目標葉節點後追加;空間不足時觸發分裂
- 刪除:移除鍵值對;佔用率過低時觸發合併
分裂和合併操作維持樹的平衡,同時保持最小樹深度。要建構磁碟上的 B-Tree 實作,還需要深入了解節點在磁碟上的佈局方式以及資料編碼格式,這些將在後續章節中探討。