資料庫管理系統(DBMS)的用途非常多元:有些專門處理暫時性的熱資料(hot data),有些作為長期的冷儲存(cold storage),有些支援複雜的分析查詢,有些只允許透過 key 存取值,有些專門儲存時間序列資料,有些則高效處理大型二進位物件(blob)。
本章從分類與總覽開始,釐清資料庫系統的架構、儲存媒介、資料佈局等基本概念,為後續章節奠定基礎。
依照工作負載特性,DBMS 常被分為三大類:
- OLTP(Online Transaction Processing):處理大量面向使用者的請求與交易,查詢通常是預先定義且短暫的
- OLAP(Online Analytical Processing):處理複雜的聚合運算,常用於分析與資料倉儲,支援長時間執行的 ad hoc 查詢
- HTAP(Hybrid Transactional and Analytical Processing):結合 OLTP 與 OLAP 的特性
此外還有 key-value store、關聯式資料庫、文件導向資料庫、圖資料庫等分類方式,但本書討論的概念廣泛適用於各種類型,因此完整的分類學並非本章重點。
DBMS 架構#
資料庫管理系統沒有統一的架構藍圖,每個系統的設計都有所不同,元件之間的邊界也不容易明確劃分。儘管如此,多數 DBMS 仍具有以下共同的架構模式。
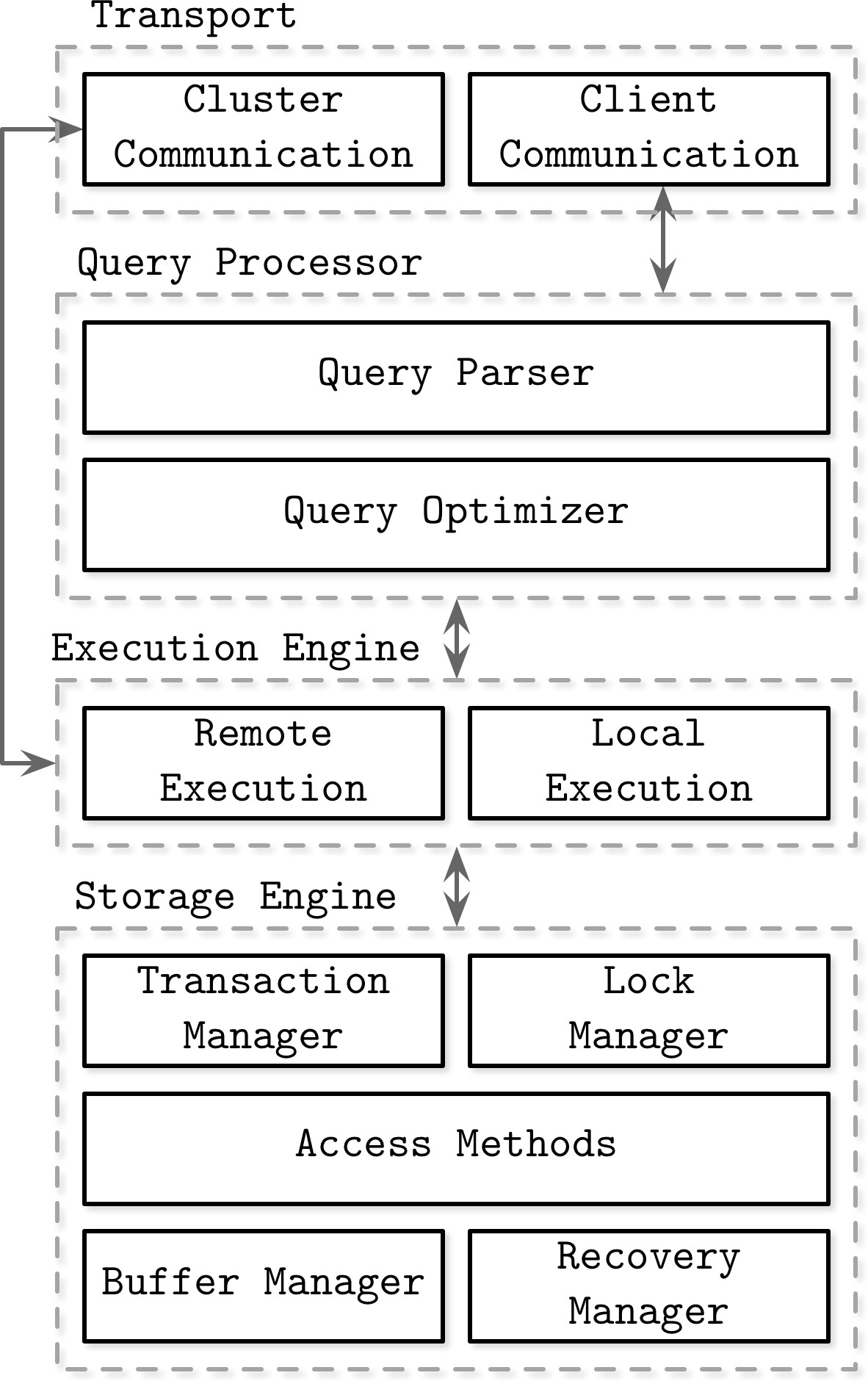
Figure 1.1: Architecture of a database management system
DBMS 採用 client/server 模型,資料庫實例扮演伺服器角色,應用程式實例扮演客戶端角色。一個請求的處理流程如下:
- 傳輸子系統(Transport Subsystem):接收客戶端請求(通常以查詢語言表示),也負責叢集中節點間的通訊
- 查詢處理器(Query Processor):解析(parse)、解讀(interpret)、驗證(validate)查詢,並執行存取控制檢查
- 查詢最佳化器(Query Optimizer):消除不可能與冗餘的查詢部分,根據內部統計資訊(索引基數、近似交集大小等)和資料配置(哪些節點持有資料及傳輸成本),找出最有效率的執行計畫(execution plan)
- 執行引擎(Execution Engine):收集本地與遠端操作的結果,遠端執行可能涉及讀寫其他叢集節點的資料以及資料複製
儲存引擎的元件#
本地查詢由**儲存引擎(Storage Engine)**執行,它包含以下元件:
- 交易管理器(Transaction Manager):排程交易,確保資料庫不會處於邏輯不一致的狀態
- 鎖管理器(Lock Manager):對執行中交易所操作的資料庫物件加鎖,確保並行操作不會違反物理資料完整性
- 存取方法(Access Methods):管理磁碟上的資料存取與組織方式,包括 heap file 和 B-Tree、LSM Tree 等儲存結構
- 緩衝管理器(Buffer Manager):將資料頁快取在記憶體中
- 復原管理器(Recovery Manager):維護操作日誌,在系統故障時還原狀態
交易管理器與鎖管理器共同負責並行控制(Concurrency Control),在確保邏輯與物理資料完整性的同時,盡可能高效地執行並行操作。
記憶體型與磁碟型 DBMS#
依據主要儲存媒介,DBMS 可分為兩類:
- 記憶體型(In-Memory DBMS):資料主要儲存在記憶體中,磁碟僅用於復原與日誌
- 磁碟型(Disk-Based DBMS):大部分資料存放在磁碟上,記憶體用於快取或暫存
記憶體型 DBMS 的優勢#
記憶體存取速度比磁碟快數個數量級,這是選擇記憶體作為主要儲存的核心理由。此外:
- 記憶體程式設計顯著簡單,作業系統抽象化了記憶體管理,允許分配和釋放任意大小的記憶體區塊
- 磁碟則需要手動管理資料參考、序列化格式、已釋放空間和碎片化(fragmentation)
記憶體型 DBMS 的限制#
- 揮發性(Volatility):RAM 的內容不具持久性,軟體錯誤、當機、硬體故障或斷電都可能導致資料遺失
- 成本:RAM 價格仍然遠高於 SSD 和 HDD 等持久性儲存裝置
- 雖然 UPS(不斷電系統)和 battery-backed RAM 可確保持久性,但需要額外硬體與維運專業知識
NVM(Non-Volatile Memory) 技術的發展,有望減少甚至消除讀寫延遲的不對稱性,進一步改善讀寫效能,並提供位元組定址(byte-addressable)的存取方式。
記憶體型資料庫的持久性策略#
為了提供持久性保證,記憶體型資料庫會在磁碟上維護備份:
- 操作完成前,結果必須先寫入循序日誌檔(sequential log file)(即 Write-Ahead Log)
- 維護一份排序的磁碟備份,修改通常以非同步批次方式套用,減少 I/O 次數
- 復原時,從備份和日誌還原資料庫內容
- 日誌記錄批次套用至備份後,備份即代表某個時間點的快照,該時間點之前的日誌即可丟棄,此過程稱為 checkpointing
不能將記憶體型資料庫簡單等同於「擁有巨大 page cache 的磁碟型資料庫」。即使頁面被快取在記憶體中,序列化格式與資料佈局仍會帶來額外的開銷,無法達到記憶體型資料庫所能實現的最佳化程度。
磁碟型與記憶體型的結構差異#
- 磁碟型資料庫使用針對磁碟存取最佳化的儲存結構,通常是寬而矮的樹狀結構
- 記憶體型實作可以從更多元的資料結構中選擇,並進行在磁碟上難以實現的最佳化
- 在磁碟上處理可變大小的資料需要特別注意,但在記憶體中只需用指標參考即可
對於某些場景,整個資料集可以合理假設能放進記憶體。例如學校的學生紀錄、企業的客戶紀錄、線上商店的庫存——每筆紀錄不過幾 KB,且數量有限。
列式與行式 DBMS#
大多數資料庫系統將資料紀錄儲存在表(table)中,由欄(column)與列(row)組成。欄位(field) 是欄與列的交集,即某個型別的單一值。
依照資料在磁碟上的儲存方式,可以區分為:
- 行式(Row-Oriented):水平分割,同一列的值儲存在一起
- 列式(Column-Oriented):垂直分割,同一欄的值儲存在一起
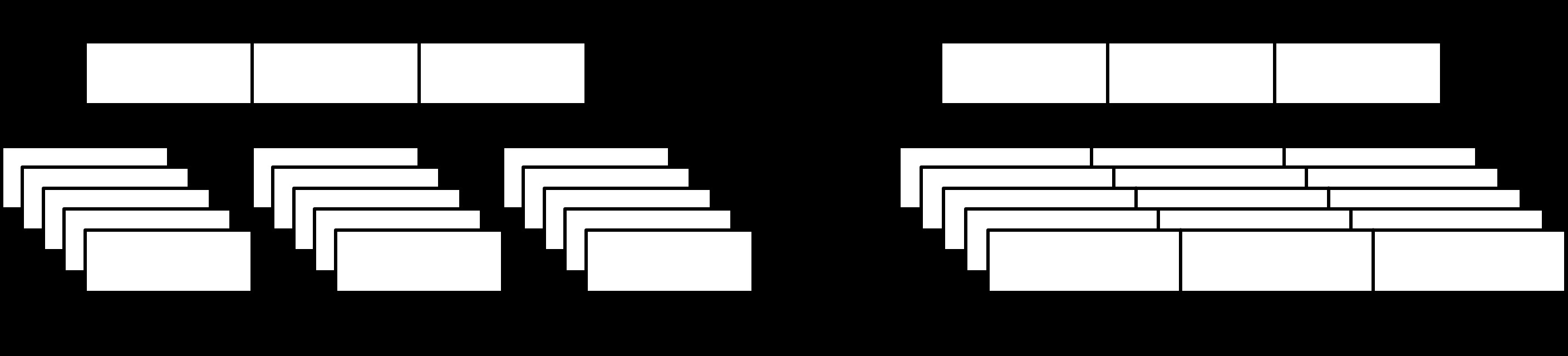
Figure 1.2: Data layout in column- and row-oriented stores
行式資料佈局#
行式 DBMS 將資料以紀錄為單位儲存,佈局接近表格的呈現方式。典型的行式資料庫包括 MySQL 和 PostgreSQL 等傳統關聯式資料庫。
行式儲存的特點:
- 構成一筆紀錄的所有欄位通常會一起讀取與寫入
- 同一列的資料儲存在一起,改善了空間局部性(spatial locality)
- 以區塊為最小磁碟存取單位,單一區塊就包含所有欄位的資料
- 適合需要按列存取完整紀錄的場景(如以主鍵查詢整筆使用者資料)
- 對於只存取少數欄位但橫跨大量列的查詢(如只取所有人的電話號碼),效率較差,因為其他不需要的欄位也會一併載入
列式資料佈局#
列式 DBMS 將同一欄的值連續儲存在磁碟上。先驅的開源列式資料庫包括 MonetDB 和 C-Store(Vertica 的前身)。
列式儲存的特點:
- 適合分析型工作負載,例如趨勢分析、計算平均值等聚合運算
- 按欄查詢時可以一次讀取完成,無需載入整列後再丟棄不需要的欄位
- 為了重建資料元組(tuple),需要保留一些元資料來關聯不同欄的資料點。可以為每個值附帶 key(但會增加儲存空間),也可以使用隱含識別符(virtual ID),以值的偏移量來對應回相關的值
近年來,分析型查詢的需求不斷增長,催生了許多新的列式檔案格式(如 Apache Parquet、Apache ORC、RCFile)與列式資料庫(如 Apache Kudu、ClickHouse)。
行式與列式的選擇#
行式與列式的差異不僅在於資料儲存方式,還涉及一系列最佳化策略:
- 快取與運算效率:連續讀取同一欄的多個值,能顯著改善快取利用率。在現代 CPU 上,可使用 SIMD(Single Instruction Multiple Data) 向量化指令,以單一 CPU 指令處理多個資料點
- 壓縮比:相同型別的值儲存在一起(例如數字與數字、字串與字串),能使用更適合該型別的壓縮演算法,獲得更好的壓縮率
如何選擇行式或列式?若讀取時需要整筆紀錄的大部分欄位,且工作負載以點查詢(point query)和範圍掃描(range scan)為主,選擇行式。若需要跨越大量列掃描,或對欄位子集做聚合運算,選擇列式。
寬欄資料庫(Wide Column Store)#
寬欄資料庫(如 BigTable、HBase)不應與列式資料庫混淆。寬欄資料庫的特性如下:
- 資料以多維 map 表示
- 欄被分組為欄族(column family),通常儲存相同類型的資料
- 在每個欄族內部,資料以行式儲存
- 最適合透過 key 或一系列 key 檢索資料

Figure 1.3: Conceptual structure of a Webtable
以 Bigtable 論文中的 Webtable 為例:
- 儲存網頁內容的快照、屬性及頁面間的關係
- 以反轉 URL 作為列鍵(row key)識別頁面
- 屬性(如頁面內容和錨點連結)以時間戳標識快照版本
- 相關欄被分組為欄族(例如
contents和anchor),各欄族獨立儲存在磁碟上 - 欄族內的每一欄由欄鍵(column key) 識別,即欄族名稱加上限定詞(qualifier)的組合
- 欄族儲存多個時間戳版本的資料
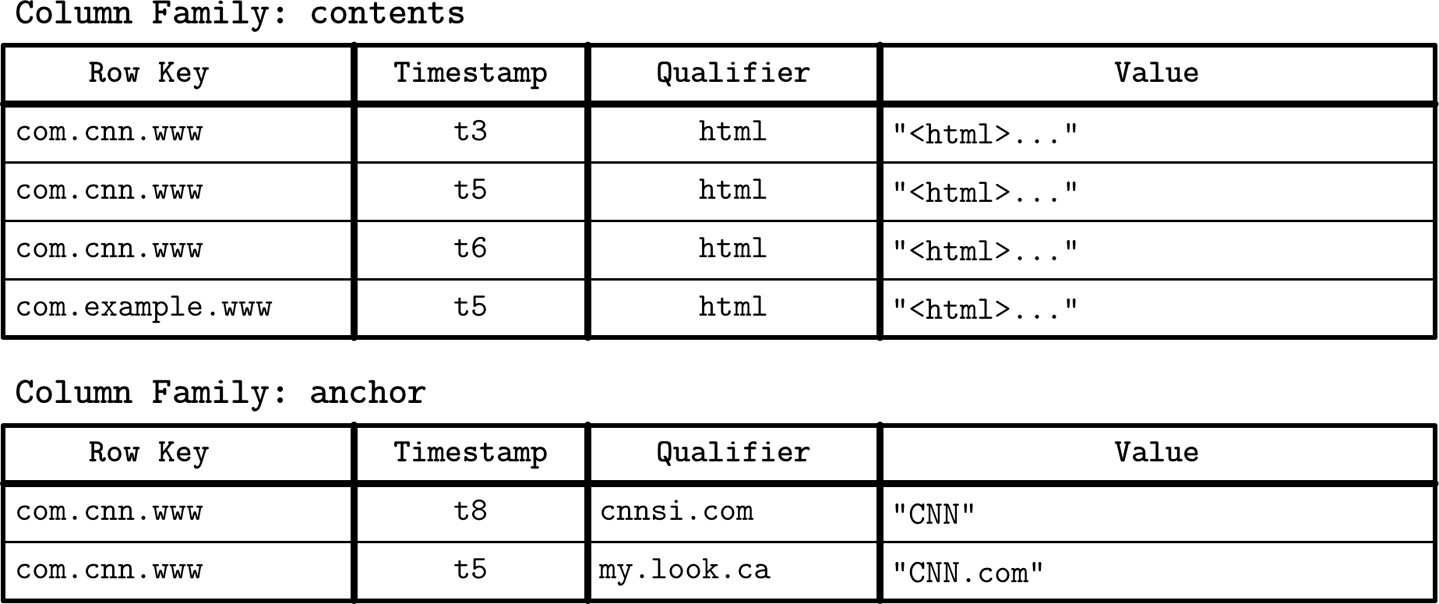
Figure 1.4: Physical structure of a Webtable
寬欄資料庫的物理佈局與概念模型不同:欄族分開儲存,但在同一個欄族內,屬於同一個 key 的資料儲存在一起。
資料檔案與索引檔案#
資料庫系統使用特殊格式組織檔案,而非依賴檔案系統的目錄與檔案階層來定位紀錄。主要原因有三:
- 儲存效率(Storage Efficiency):最小化每筆紀錄的儲存開銷
- 存取效率(Access Efficiency):以最少的步驟定位紀錄
- 更新效率(Update Efficiency):最小化磁碟上的變更次數
資料庫系統通常將資料檔案和索引檔案分開:資料檔案儲存實際資料紀錄,索引檔案儲存紀錄的元資料,用來定位資料檔案中的紀錄。索引檔案通常比資料檔案小。檔案被分割為頁面(page),大小通常為一個或多個磁碟區塊。
新紀錄的插入與既有紀錄的更新以 key/value 對表示。大多數現代儲存系統不會顯式刪除頁面中的資料,而是使用刪除標記(tombstone)。被更新或刪除標記所覆蓋的紀錄,其空間在垃圾回收(garbage collection) 時才會被回收。
資料檔案#
資料檔案(又稱 primary file)的組織方式有三種:
- 索引組織表(Index-Organized Table, IOT):資料紀錄直接儲存在索引中,按 key 順序排列,因此範圍掃描可以直接循序讀取。這能減少至少一次磁碟尋址,因為走訪索引找到 key 後不需要再存取另一個檔案
- 堆積組織表(Heap-Organized Table):紀錄不按特定順序排列,通常依寫入順序存放,新增頁面時不需要額外整理。但需要額外的索引結構來指向資料的位置
- 雜湊組織表(Hash-Organized Table):紀錄根據 key 的雜湊值儲存在對應的 bucket 中,bucket 內的紀錄可以按寫入順序或 key 排序
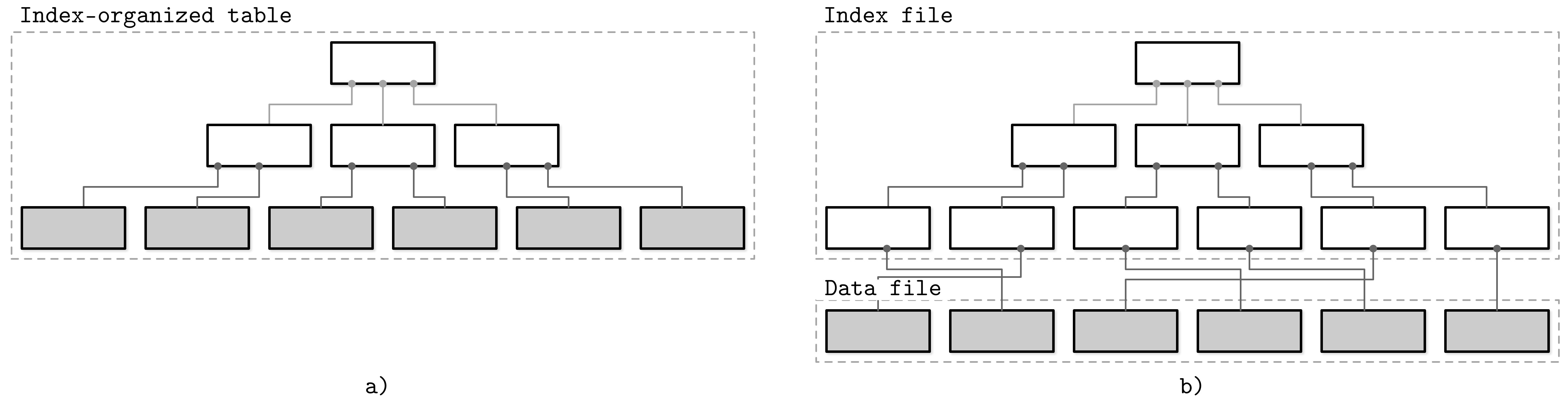
Figure 1.5: Storing data records in an index file versus storing offsets to the data file
索引檔案#
索引是一種將 key 對應到資料檔案中紀錄位置的結構:
- 主索引(Primary Index):建立在主資料檔案上的索引,通常建立在主鍵上,每個搜尋鍵對應唯一的項目
- 次索引(Secondary Index):其他所有索引,可以直接指向資料紀錄或僅儲存其主鍵,每個搜尋鍵可能對應多個項目。多個次索引可以指向同一筆紀錄,允許透過不同欄位定位資料
- 叢集索引(Clustered Index):資料紀錄的順序與搜尋鍵順序一致。IOT 在定義上就是叢集的,主索引通常是叢集的
- 非叢集索引(Nonclustered Index):資料儲存在獨立檔案中,順序與鍵序不一致。次索引在定義上是非叢集的
這套術語廣泛用於各種資料庫系統:關聯式資料庫(MySQL、PostgreSQL)、Dynamo 系列的 NoSQL(Apache Cassandra、Riak)、文件資料庫(MongoDB)。不同專案可能有特定命名,但大多能明確對應到這些術語。
主索引作為間接層#
資料紀錄應該透過檔案偏移量直接參考,還是透過主鍵索引間接參考,資料庫社群對此有不同看法:
| 方式 | 優點 | 缺點 |
|---|---|---|
| 直接參考(檔案偏移量) | 減少磁碟尋址次數 | 紀錄更新或搬移時需更新所有指標 |
| 間接參考(主索引) | 降低指標更新成本 | 讀取路徑上需額外查找 |
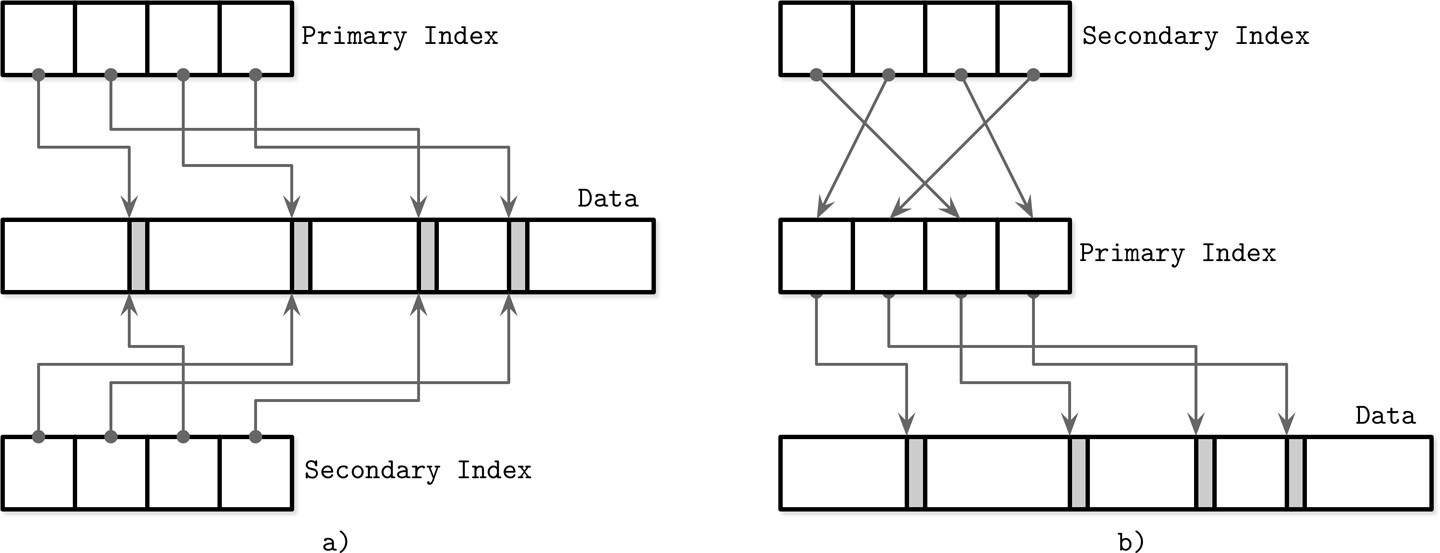
Figure 1.6: Referencing data tuples directly (a) versus using a primary index as an indirection
例如,MySQL InnoDB 就採用主索引間接參考:查詢時先在次索引中查找,再到主索引中查找,以此避免在寫入密集的工作負載中頻繁更新多個索引中的指標。
也有混合方式:同時儲存資料檔案偏移量和主鍵,先檢查偏移量是否仍然有效,若無效再透過主鍵索引查找,並於找到新偏移量後更新索引。
緩衝、不可變性與排序#
儲存引擎的設計基於特定的資料結構,但這些結構本身並不涵蓋快取、復原、交易等語義。本書討論的儲存結構有三個共同的設計變數:
緩衝(Buffering)#
定義儲存結構是否選擇在記憶體中收集一定量的資料後再寫入磁碟。
- 每個磁碟結構都需要某種程度的緩衝(因為最小傳輸單位是區塊,寫入完整區塊是理想的)
- 這裡討論的是可選擇的緩衝,即儲存引擎實作者主動選擇做的
- 例如:在 B-Tree 節點加入記憶體緩衝以分攤 I/O 成本(Lazy B-Trees)
- LSM Tree 以完全不同的方式使用緩衝,將緩衝與不可變性結合
可變性與不可變性(Mutability / Immutability)#
定義儲存結構是否會讀取檔案的一部分、更新後寫回原位。
- 可變(Mutable):就地更新(in-place update),讀取、修改、寫回同一位置
- 不可變(Immutable):append-only,修改追加到檔案末尾,原有內容不變
- Copy-on-Write:修改後的頁面寫到檔案中的新位置,而非原始位置
- B-Tree 與 LSM Tree 的區別常被描述為就地更新 vs. 不可變儲存,但也有例外(如 Bw-Tree 受 B-Tree 啟發但採用不可變設計)
排序(Ordering)#
定義資料紀錄是否按照 key 的順序儲存在磁碟頁面上。
- 有序儲存:排序相近的 key 儲存在磁碟上連續的區段,使範圍掃描更高效
- 無序儲存(通常按插入順序):可帶來寫入時的最佳化。例如 Bitcask 和 WiscKey 將資料紀錄直接儲存在 append-only 檔案中
總結#
本章涵蓋了資料庫管理系統的架構與核心分類概念:
- DBMS 架構:從傳輸子系統、查詢處理器、最佳化器、執行引擎到儲存引擎,每個元件各司其職
- 記憶體型 vs. 磁碟型:兩者都需要磁碟結構,但用途不同——記憶體型用於持久化與復原,磁碟型用於主要儲存
- 行式 vs. 列式:存取模式決定了選擇。行式適合按紀錄存取,列式適合跨列聚合分析
- 寬欄資料庫:不同於列式資料庫,欄族內部是行式儲存
- 資料檔案與索引檔案:IOT、heap file、hash file 三種組織方式各有適用場景;主索引與次索引、叢集與非叢集的概念貫穿各類資料庫系統
- 緩衝、不可變性、排序:這三個設計變數是理解後續章節中各種儲存結構差異的關鍵框架