本章探討如何管理應用程式所依賴的基礎設施與環境,涵蓋從伺服器佈建、組態管理、虛擬化到雲端運算與監控的完整面向。核心訊息是:環境的期望狀態應透過版本控制的組態來定義,基礎設施應能自我修復(autonomic),且你應隨時掌握基礎設施的實際狀態。
環境與基礎設施的定義#
- 環境(Environment):應用程式運作所需的所有資源及其組態,包括:
- 伺服器的硬體組態(CPU、記憶體、磁碟、網路卡等)以及連接它們的網路基礎設施
- 作業系統與中介軟體(Middleware)的組態,如訊息系統、應用程式伺服器、資料庫伺服器等
- 基礎設施(Infrastructure):組織中所有環境及其支援服務的統稱,包括 DNS 伺服器、防火牆、路由器、版本控制儲存庫、儲存設備、監控應用程式、郵件伺服器等
測試環境應該要像生產環境(production-like)。管理測試環境與生產環境的技術手段應完全一致,目的是盡早發現環境問題,並在進入生產環境前演練部署與組態等關鍵活動。
基礎設施管理的三大原則:
- 基礎設施的期望狀態(desired state)應透過版本控制的組態來定義
- 基礎設施應是自主式的(autonomic)——能自動修正至期望狀態
- 應透過監測與監控(instrumentation and monitoring)隨時掌握基礎設施的實際狀態
理解維運團隊的需求#
開發團隊與維運團隊(Operations Team)之間的協作關係是成功部署的關鍵。開發團隊的目標是快速交付軟體,維運團隊的目標是穩定性。雙方共同的目標是:讓有價值的軟體發佈成為低風險的活動。
文件記錄與稽核(Documentation and Auditing)#
- 維運管理者需要確保對環境的每一項變更都有文件記錄和稽核軌跡
- 組織通常會有變更管理流程(Change Management Process),由變更顧問委員會(Change Advisory Board, CAB)審核
- 部署新版應用程式通常屬於「正常變更」(normal change),需要變更經理的核准
- 開發團隊有責任了解並遵守維運團隊既有的流程與系統
異常事件的警報(Alerts for Abnormal Events)#
- 維運團隊需要在異常狀況發生時立即被通知,並知道去哪裡查看更多細節
- 開發團隊應在專案初期就了解維運團隊的監控需求,包括:要監控什麼、日誌應放在哪裡、應用程式應如何通知維運人員故障
- 每個錯誤狀態都應記錄到一個單一且已知的位置,附上適當的嚴重等級
IT 服務持續計畫(IT Service Continuity Planning)#
- RPO(Recovery Point Objective):災難發生前可接受的資料遺失時間長度,決定資料備份策略
- RTO(Recovery Time Objective):服務恢復的最長允許時間
- 應測試應用程式資料的備份、復原和歸檔流程,並將操作程序提供給維運團隊
使用維運團隊熟悉的技術#
- 維運團隊通常熟悉 Bash 或 PowerShell,但未必精通 Java 或 C#
- 開發與維運團隊應在專案初期就商定部署技術(例如 Perl、Ruby、Python,或打包技術如 Debian 打包系統、WiX)
- 部署系統是應用程式的不可分割的一部分,應與應用程式本身一樣受到測試、重構和版本控制
建模與管理基礎設施#
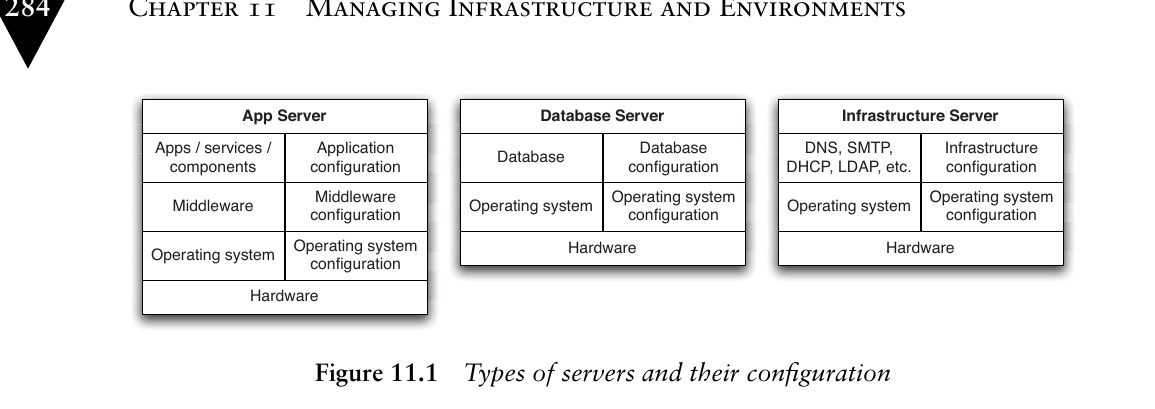
Figure 11.1: Types of servers and their configuration
不同類別的伺服器(應用伺服器、資料庫伺服器、基礎設施伺服器)各有不同層次的組態資訊,都應以自動化方式佈建和管理。
應納入版本控制的項目至少包括:
- 作業系統安裝定義(如 Debian Preseed、RedHat Kickstart、Solaris Jumpstart)
- 資料中心自動化工具的組態(如 Puppet 或 CfEngine)
- 一般基礎設施組態(DNS zone 檔、DHCP、SMTP、防火牆組態等)
- 管理基礎設施所用的任何腳本
這些版本控制中的檔案與原始碼一樣是部署管線(Deployment Pipeline)的輸入。管線的職責有三:(1) 驗證基礎設施變更不會破壞應用程式;(2) 將變更推送到維運管理的測試和生產環境;(3) 執行部署測試以確保新組態已成功部署。
控制對基礎設施的存取#
控制基礎設施有三個面向:
- 控制存取——防止未經核准的變更
- 定義自動化流程——用於進行基礎設施變更
- 監控基礎設施——偵測問題
必須鎖定生產環境以防止未授權存取——不僅防範組織外部人員,也包括組織內部人員,甚至維運人員。否則出問題時,很容易有人直接登入環境「隨手修修看」,這通常會導致更多服務中斷,且因沒有記錄而無法追蹤問題原因。
進行基礎設施變更#
有效的變更管理流程的基本特徵:
- 每項變更都應經過相同的變更管理流程
- 使用單一工單系統管理,產出有用的指標(如每次變更的平均週期時間)
- 確切的變更內容應被記錄以便稽核
- 變更應先在生產環境相似的測試環境中測試
- 變更應提交到版本控制,然後透過自動化流程套用
- 應有測試驗證變更是否成功
flowchart TD
A[提出變更] --> B[建立工單]
B --> C[腳本化變更\n簽入版本控制]
C --> D[在測試環境套用]
D --> E{測試通過?}
E -->|是| F[自動化推送\n到生產環境]
E -->|否| G[修改腳本]
G --> C
F --> H[記錄稽核日誌]作者偏好自動化勝過文件記錄——書面文件永遠無法保證記錄的變更確實被正確執行,而人們聲稱做了什麼和實際做了什麼之間的差異,可能導致花費數小時或數天才能追蹤到的問題。
管理伺服器的佈建與組態#
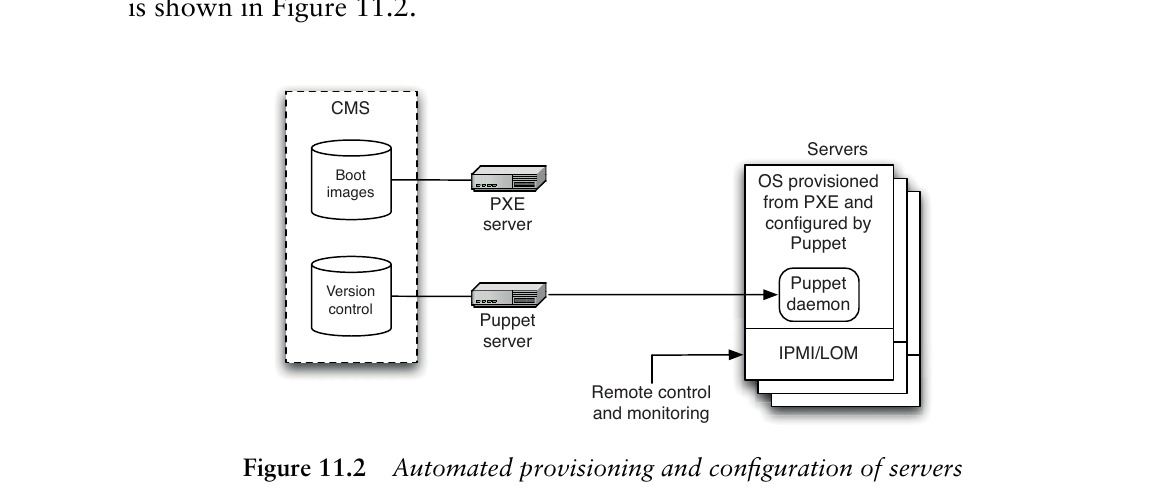
Figure 11.2: Automated provisioning and configuration of servers
佈建伺服器(Provisioning Servers)#
建立作業系統基線(baseline)的方式:
| 方式 | 說明 |
|---|---|
| 完全手動流程 | 不可靠地重複,無法擴展,容易產生「藝術品」伺服器(works of art) |
| 自動化遠端安裝 | 透過 PXE(Preboot eXecution Environment)或 Windows Deployment Services 將新實體機器從零開始自動安裝 |
| 虛擬化 | 利用虛擬機器映像檔建立環境基線 |
PXE 是透過乙太網路啟動機器的標準協定,使用修改過的 DHCP 找到提供開機映像的伺服器,再透過 TFTP 載入映像。在 Windows 環境中,對應的技術是 Windows Deployment Services (WDS)。
持續管理伺服器(Ongoing Management)#
組態管理的目標是確保組態管理是宣告式的(declarative)且冪等的(idempotent)——無論基礎設施的初始狀態為何,最終結果都相同,即使同一組態被重複套用。
集中式、版本控制的組態管理系統帶來的好處:
- 確保所有環境的一致性
- 輕鬆佈建與既有環境匹配的新環境
- 硬體故障時,可透過全自動化流程快速重建
主要的開源工具包括 Puppet、CfEngine 和 Chef;商業工具則有 Microsoft SCCM、BMC BladeLogic、IBM Tivoli、HP Operations Center 等。
你應該能夠從一組全新的(vanilla)伺服器從零開始部署所有東西。一個好的測試問題是:如果生產環境災難性地故障了,佈建一份新的副本需要多長時間?
管理中介軟體的組態#
中介軟體(Middleware)——無論是網頁伺服器、訊息系統或商用現成軟體(COTS)——可以分解為三個部分:二進位檔(binaries)、組態(configuration)和資料(data),三者有不同的生命週期,應獨立處理。
處理頑固的中介軟體#
當中介軟體不支援自動化組態時的應對策略:
- 研究產品:仔細搜尋文件,確認是否有不為人知的自動化組態選項
- 檢視中介軟體如何處理狀態:許多產品使用 XML 檔案儲存組態,可以直接版本控制;對於二進位檔也應考慮版本控制
- 尋找組態 API:定義自己的組態檔,建立自訂建置任務透過 API 來組態系統
- 使用更好的技術:如果以上方法都行不通,考慮替換技術。作者建議維護一份「痛苦紀錄簿」(pain-register),記錄因低效技術而浪費的時間,以此說服管理層投資更好的替代方案
凌晨兩點需要將關鍵修正送入生產環境時,透過 GUI 工具手動輸入資料極容易出錯。此時自動化部署流程將拯救你。作者認為,沒有任何技術可以被視為真正的企業級(enterprise-ready),除非它能夠以自動化方式部署和組態。
管理基礎設施服務#
基礎設施服務(如路由器、DNS、目錄服務)的問題極常導致在部署管線中完美運作的軟體在生產環境中崩潰。
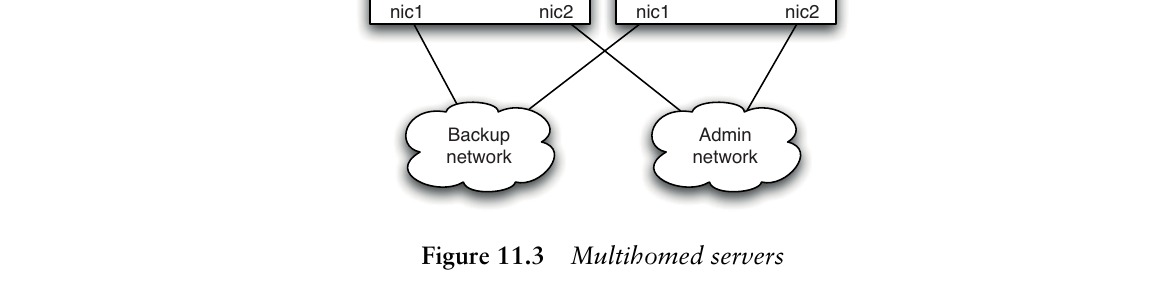
Figure 11.3: Multihomed servers
作者的建議:
- 網路基礎設施的所有組態(DNS zone 檔、DHCP、防火牆、路由器等)都應版本控制,使用 Puppet 等工具從版本控制推送組態
- 安裝良好的網路監控系統(如 Nagios、OpenNMS),監控應用程式使用的每條路由上的每個埠
- 日誌是你的好朋友:連線逾時或意外關閉時記錄 WARNING,關閉連線時記錄 INFO 或 DEBUG,開啟連線時記錄 DEBUG
- 確保煙霧測試(smoke tests)在部署時檢查所有連線
- 整合測試環境的網路拓撲應盡可能與生產環境相似
多宿主系統(Multihomed Systems)#
生產系統的一項重要強化措施是為不同類型的流量使用多個隔離的網路。多宿主伺服器擁有多個網路介面,各自連接不同的網路:
- 監控與管理網路(Administration network)
- 備份網路(Backup network)
- 生產資料網路(Production network)
關鍵實務:每個服務和應用程式只應繫結(bind)到相關的 NIC,且所有多宿主網路的組態(包括路由)應集中管理和監控。
虛擬化(Virtualization)#
虛擬化透過在實體資源之上增加一層抽象,為自動化佈建伺服器和環境的技術帶來倍增效益。

Figure 11.4: Creating virtual environments from templates
虛擬化的主要好處:
| 好處 | 說明 |
|---|---|
| 快速回應需求變化 | 新虛擬機器可在數秒內佈建,無需等待數天或數週取得新的實體環境 |
| 合併整合(Consolidation) | 將 CI 伺服器和測試基礎設施合併,作為服務提供給交付團隊 |
| 標準化硬體 | 實體環境標準化為單一硬體組態,但可虛擬地運行多種異質環境 |
| 更容易維護基線 | 可維護一個基線映像庫(baseline images),一鍵推送到叢集 |
管理虛擬環境#
虛擬機器映像(disk image)是單一檔案,可以複製和版本化,作為範本(template)或基線使用。

Figure 11.5: Creating VM templates
工作流程:
- 從基礎 OS 映像(含資料中心管理工具的 agent,如 Puppet daemon)啟動
- 執行自動化流程組態 OS、安裝並組態應用程式堆疊
- 將已組態的 VM 儲存為範本
- 重複此流程建立不同類型的伺服器範本
虛擬化也提供了處理「藝術品」遺留環境(legacy environments)的方法——用虛擬化工具對運行中的機器拍快照轉為 VM,即可輕鬆建立測試用的環境副本,並逐步從手動管理過渡到自動化。
虛擬環境與部署管線#
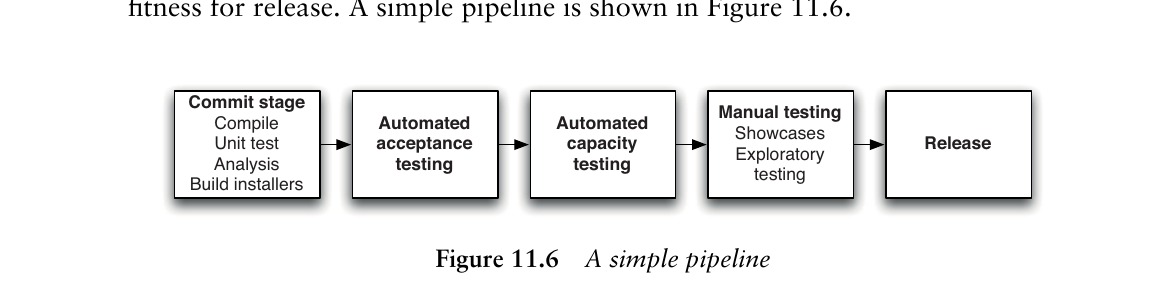
Figure 11.6: A simple pipeline
部署管線中的每個管線實例都與觸發它的版本控制變更相關聯。當管線中出現測試失敗時,五個最可能的原因是:
- 應用程式程式碼中的錯誤
- 測試中的錯誤或無效預期
- 應用程式組態的問題
- 部署流程的問題
- 環境的問題
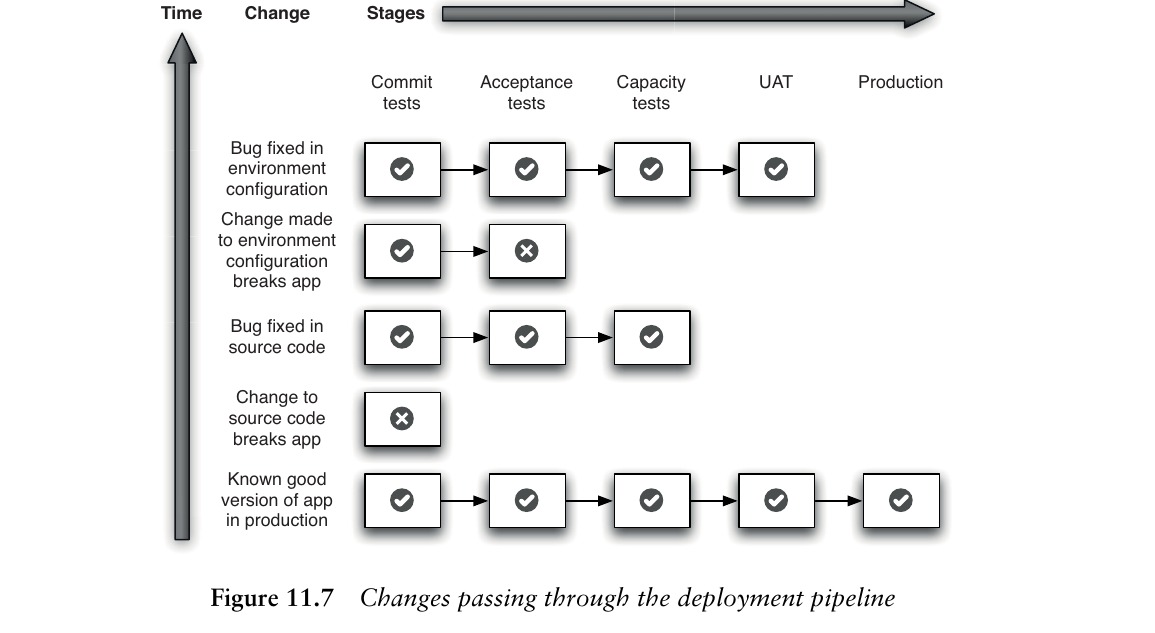
Figure 11.7: Changes passing through the deployment pipeline
環境組態的變更應與其他變更(原始碼、測試、腳本)一樣觸發新的管線實例。部署到生產環境時,應使用與執行所有測試時完全相同的環境。
不建議每次變更都建立全新的虛擬基線。更好的做法是保持相對穩定的 VM 基線映像(基礎 OS + 最新 service packs + 中介軟體 + 資料中心管理工具 agent),然後由工具完成佈建流程,將基線調整到所需的確切組態。
高度平行化測試#
虛擬化可用於在多個虛擬機器上平行執行測試,大幅縮短回饋週期。作者提到在一個大型專案中,此方法將測試時間從 13 小時縮短到 45 分鐘。
虛擬網路(Virtual Networks)#

Figure 11.8: Using virtual networks
現代虛擬化工具提供強大的網路組態功能,可以複製生產環境的精確網路拓撲(包括 IP 和 MAC 位址),在虛擬網路上建立多個環境副本,同時進行 UAT、容量測試和自動化測試。甚至可以透過虛擬化 API 程式化地模擬伺服器間的連線中斷,用於非功能性測試。
雲端運算(Cloud Computing)#
雲端運算的定義特徵是運算資源(CPU、記憶體、儲存等)可以依需求彈性擴縮,且按用量付費。
雲端基礎設施(Infrastructure in the Cloud)#
以 Amazon Web Services (AWS) 為代表,提供高度可組態的基礎設施服務(訊息佇列、靜態內容託管、負載平衡、儲存、EC2 虛擬機器等)。
主要考量:
| 考量面向 | 說明 |
|---|---|
| 安全性 | 雲端供應商提供可組態的防火牆和連接至組織 VPN 的私有網路 |
| 合規性 | 需仔細規劃,但通常可以調和(例如加密資料以符合 HIPAA) |
| 服務等級 | 需研究確保供應商能滿足效能需求 |
雲端平台(Platforms in the Cloud)#
如 Google App Engine 和 Force.com,提供標準化的應用程式堆疊,供應商負責擴展和基礎設施管理。
優勢:
- 成本結構與佈建靈活性等同於雲端基礎設施
- 服務供應商處理非功能需求(可擴展性、可用性、安全性)
- 部署到完全標準化的堆疊,無需擔心環境的組態或維護
可以混合搭配不同服務來實作系統——例如靜態內容託管在 AWS,應用程式託管在 Google App Engine,專有服務運行在自有基礎設施上。這要求鬆耦合架構(loosely coupled architecture)。
雲端運算的批評#
- 供應商鎖定(vendor lock-in):各供應商提供不同服務,且缺乏通用標準
- 經濟性:取決於具體應用,應比較效用運算與自有基礎設施的成本投射,考慮損益平衡點、折舊、維護、災難復原和支援等因素
監控基礎設施與應用程式#
監控生產環境的三個原因:
- 即時商業智慧(real-time business intelligence)——更快的業務策略回饋
- 事故回應——維運團隊需立即知道問題並追蹤根因
- 規劃用的歷史資料——了解系統在需求高峰或新增伺服器時的表現
蒐集資料#
監控資料來源:
| 資料來源 | 監控項目 |
|---|---|
| 硬體 | 透過 IPMI/LOM 監控電壓、溫度、風扇轉速、周邊健康狀態 |
| 作業系統 | 記憶體使用率、磁碟空間、I/O 頻寬、CPU 使用率等(UNIX 使用 Collectd,Windows 使用 Performance Counters) |
| 中介軟體 | 資源使用(記憶體、連線池、執行緒池)、連線數、回應時間 |
| 應用程式 | 商業交易數量與金額、轉換率、使用者行為分析、對外部系統連線的狀態、版本號碼 |
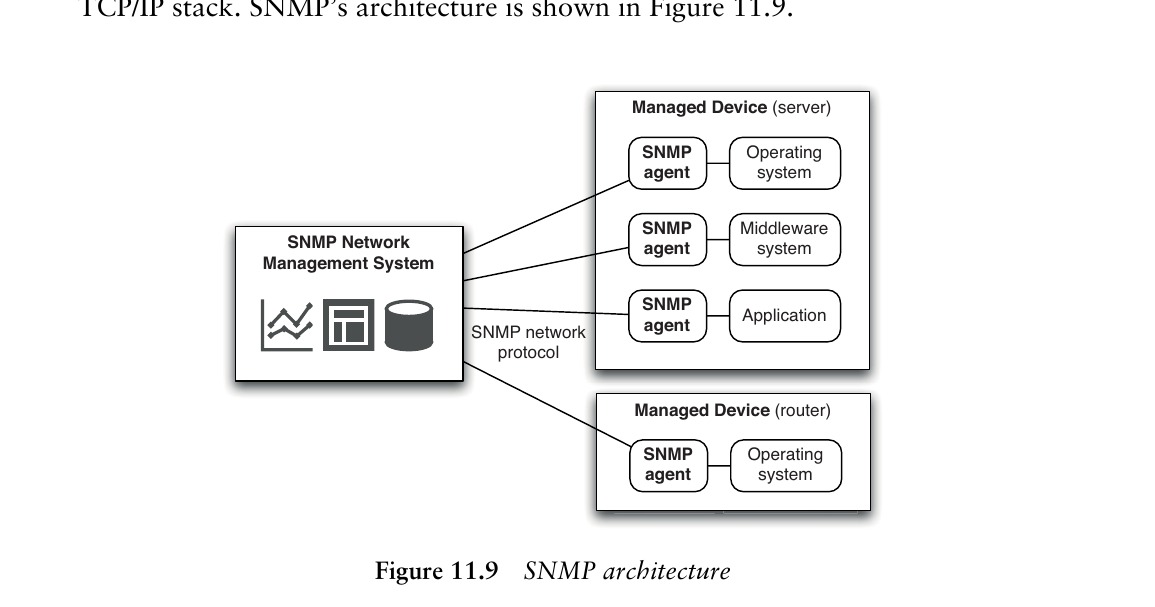
Figure 11.9: SNMP architecture
SNMP(Simple Network Management Protocol)是最廣泛使用的監控標準,包含三個主要元件:受管理裝置(managed devices)、代理程式(agents)、網路管理系統(network management system)。SNMP 中一切都是變數——透過觀察變數來監控,透過設定變數來控制。
日誌記錄(Logging)#
- 日誌等級:DEBUG、INFO、WARNING、ERROR、FATAL
- 預設應只顯示 WARNING 以上,但應可在執行時或部署時調整
- 每筆日誌條目應使用單行、欄位式格式,一目了然地顯示時間戳記、日誌等級、來源和錯誤描述
- 日誌記錄應被視為第一級需求(first-level requirements),從專案初期就納入
建立儀表板(Creating Dashboards)#
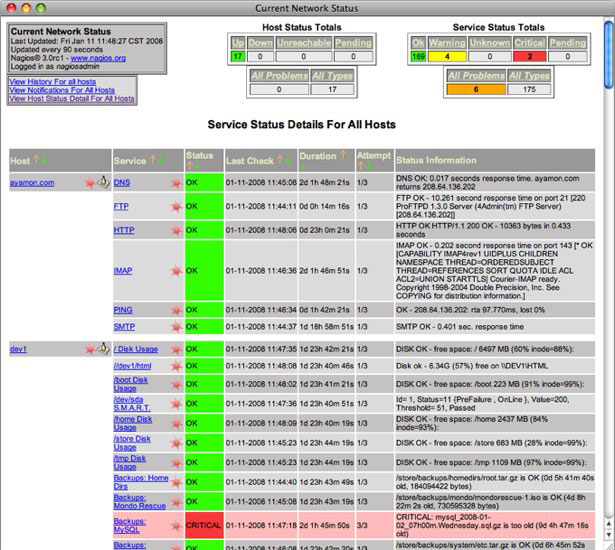
Figure 11.10: Nagios screenshot
使用紅黃綠交通燈聚合模式:
| 燈號 | 意義 |
|---|---|
| 綠色 | 所有預期事件已發生、無異常事件、所有指標在名義值範圍內、所有狀態完全運作 |
| 黃色 | 預期事件未發生、發生中等嚴重性異常事件、參數超出名義值、非關鍵狀態未完全運作 |
| 紅色 | 必要事件未發生、發生高嚴重性異常事件、參數遠超名義值、關鍵狀態未完全運作 |
行為驅動監控(Behavior-Driven Monitoring)#
如同開發者進行行為驅動開發(BDD),維運人員也可以撰寫自動化測試來驗證基礎設施的行為:
- 在監控系統中撰寫一個監控服務,確認儀表板顯示為紅色
- 實作組態變更,由 Puppet 推送到測試系統
- 當服務轉為綠色後,推送變更到生產環境
flowchart LR
A[1. 撰寫監控服務\n儀表板顯示紅色] --> B[2. 實作組態變更\nPuppet 推送到測試系統]
B --> C{服務轉為綠色?}
C -->|是| D[3. 推送到生產環境]
C -->|否| BCucumber-Nagios 是一個工具,允許以 Cucumber 撰寫 BDD 風格的測試,輸出 Nagios 插件所期望的格式,使你不僅能驗證網頁伺服器是否啟動,還能確認應用程式是否實際正常運作。
總結#
- 基礎設施組態管理的程度取決於系統的本質——簡單的命令列工具可能需求不高,但一級網站需要考慮所有面向
- 本章的建議確實增加了部署系統的複雜度,但對於大型、多組態點的系統而言,這些做法能夠挽救專案
- 自動化環境管理的成本雖然不低,但遠遠低於手動環境管理在整個應用程式生命週期中的成本
- 評估第三方產品時,應將其是否能融入自動化組態管理策略列為高優先級
- 從專案一開始就應建立基礎設施管理策略,並在該階段讓開發與維運團隊的利害關係人參與