Chapter 9: Testing Nonfunctional Requirements#
引言#
本章聚焦於非功能性需求(Nonfunctional Requirements, NFRs)的測試,特別是容量(Capacity)、**吞吐量(Throughput)與效能(Performance)**三個面向。
首先釐清術語定義(引用 Michael Nygard 的分類):
| 術語 | 定義 |
|---|---|
| 效能(Performance) | 處理單一交易所需的時間,可在隔離環境或負載下測量 |
| 吞吐量(Throughput) | 系統在給定時間內能處理的交易數量,總是受到系統中某個瓶頸的限制 |
| 容量(Capacity) | 在維持可接受的回應時間下,系統能承受的最大吞吐量 |
NFR 是專案交付風險的重大來源。許多系統失敗是因為無法承受負載、不夠安全、運行過慢,或最常見的——因程式碼品質低落而變得無法維護。但另一個極端是過度擔心 NFR,導致開發過慢或系統過度工程化。
將需求劃分為「功能性」與「非功能性」其實是一種人為區分。NFR 如可用性、容量、安全性與可維護性對系統運作同樣不可或缺。專案利害關係人應能在功能需求(如信用卡付款)與非功能需求(如支援 1,000 位同時使用者)之間做出優先順序的判斷。
管理非功能性需求#
NFR 的**跨領域特性(Crosscutting Nature)**使其在分析和實作上都格外困難。將 NFR 與功能需求區別對待,容易導致它們被忽略或分析不足,而這可能帶來災難性後果——在交付後期才發現根本性的安全漏洞或嚴重的效能問題,甚至導致專案取消。
NFR 通常對系統**架構(Architecture)**有極強的影響。例如,任何需要高效能的系統都不應讓請求穿越多個層級。由於架構在交付後期難以更改,因此必須在專案初期就考慮 NFR,做好足夠的前期分析來決定適當的架構。
此外,NFR 之間往往互相牽制:
- 高安全性系統可能犧牲易用性
- 高彈性系統可能犧牲效能
- 每種架構都涉及 NFR 之間的取捨(Trade-off)
軟體工程研究所的**架構權衡分析方法(ATAM, Architectural Tradeoff Analysis Method)**正是為了幫助團隊透過深入分析 NFR(即「品質屬性」)來決定合適的架構。
分析非功能性需求#
對於進行中的專案,有兩種管理 NFR 的方式可搭配使用:
- 附加在功能故事上:將 NFR 作為功能故事的驗收條件
- 獨立建立故事或任務:為 NFR 建立專屬的故事,特別是在專案初期
例如,對於「稽核性(Auditability)」這個 NFR,與其說「所有重要互動都應被稽核」,不如從稽核人員的角度描述需求——他們想看到哪些報告?如此一來,稽核性就不再是跨領域的 NFR,而可以像其他需求一樣被測試和排定優先順序。
分析 NFR 時必須提供合理的細節。說「回應時間要越快越好」是不夠的——這等於對投入的努力和預算不設上限。所有需求都必須被賦予可量化的價值,才能進行估算和排序。
常見的模糊描述如「所有使用者互動必須在兩秒內回應」或「系統每小時處理 80,000 筆交易」,實際上過於籠統。需要進一步釐清:
- 是否在所有情況下都適用?資料中心故障時呢?
- 是指成功完成互動,還是使用者收到任何回饋?
- 是在尖峰負載下,還是平均回應時間?
- 是否錯誤訊息也需在兩秒內回應?
為容量而程式設計#
分析不良的 NFR 容易導致過度設計(Overdesign)與不當最佳化(Inappropriate Optimization)。程式設計師通常不擅長預測效能瓶頸,反而讓程式碼變得不必要地複雜且難以維護。
Donald Knuth 的經典名言:
“We should forget about small efficiencies, say, about 97% of the time: Premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified.”
關鍵在最後一句:在找到解決方案之前,必須先識別問題的來源;而在那之前,需要先知道問題是否存在。容量測試階段的目的正是告訴我們是否有問題。不要猜測,要測量。
過早最佳化的實例:某遺留系統中,一則來自訊息佇列的錯誤訊息需要經過七層非同步輪詢才能顯示在 UI 上。設計者的意圖是避免效能瓶頸,但這個情境根本不會發生——商業訊息佇列從未被錯誤淹沒。這是一個針對不存在問題的複雜解決方案。
容量程式設計的策略#
作者提出以下八步策略:
| 步驟 | 策略 | 說明 |
|---|---|---|
| 1 | 決定架構 | 特別注意行程與網路邊界以及 I/O |
| 2 | 理解並使用模式,避免反模式 | 參考 Michael Nygard《Release It!》中描述的穩定性與容量模式 |
| 3 | 在架構邊界內工作 | 鼓勵程式碼的清晰與簡潔,不要為容量犧牲可讀性,除非有明確的測試證明其價值 |
| 4 | 注意資料結構與演算法 | 確保其特性適合應用需求,例如需要 O(1) 效能時不要使用 O(n) 演算法 |
| 5 | 極度小心多執行緒(Threading) | Nygard 指出「Blocked threads 反模式是大多數故障的直接原因」 |
| 6 | 建立自動化測試 | 斷言期望的容量水準,測試失敗時用來引導問題修復 |
| 7 | 使用效能分析工具(Profiling Tools) | 針對測試識別出的問題做聚焦式修復,而非「盡可能加快」的通用策略 |
| 8 | 盡量使用真實世界的容量指標 | 生產系統是唯一真正的測量來源 |
高容量軟體的程式碼實際上更簡單而非更複雜。複雜度會帶來延遲。困難之處在於找到問題的簡潔解法需要額外的努力。必須避免兩個極端:假設所有容量問題都能事後修復,或因恐懼未來的容量問題而寫出防禦性的過度複雜程式碼。
測量容量#
測量容量涉及以下幾種測試類型:
| 測試類型 | 說明 |
|---|---|
| 可擴展性測試(Scalability Testing) | 增加伺服器、服務或執行緒時,回應時間和同時使用者數量如何變化? |
| 長時間運行測試(Longevity Testing) | 長時間運行系統,觀察效能是否變化,可捕捉記憶體洩漏或穩定性問題 |
| 吞吐量測試(Throughput Testing) | 系統每秒能處理多少交易、訊息或頁面瀏覽? |
| 負載測試(Load Testing) | 當負載增加到生產環境等級甚至超過時,容量會如何變化?這是最常見的容量測試類型 |
前兩種是相對測量(系統屬性變化時效能如何改變),後兩種則是絕對測量。
情境式測試的重要性#
作者強調容量測試應模擬真實的使用情境,而非僅做技術基準測量(如「資料庫每秒能存多少交易」)。更有價值的問題是:「在常規使用模式下,我每秒能處理多少筆銷售?」或「我預期的使用者群在尖峰負載時能否有效使用系統?」
真實世界的系統不會一次只做一件事。例如,銷售系統在處理銷售的同時,也在更新庫存、處理訂單、記錄工時單等。容量測試應能組合多種互動情境同時運行,才能防禦更多類別的問題。
定義成功與失敗標準#
許多容量測試更像是測量而非真正的測試——成敗由人工分析決定。但容量測試系統同時生成圖表和測量數據也很有價值,因為趨勢與絕對值同樣重要。
設定通過門檻時需要平衡:
- 門檻過高:容易出現間歇性的誤報失敗(如網路被其他任務使用時)
- 門檻過低:無法發現幾乎使吞吐量減半的變更
兩個策略:
- 追求穩定、可重現的結果:盡量隔離容量測試環境,專門用於測量容量。容量測試是少數不適合虛擬化的情境(除非生產環境本身就是虛擬的)
- 逐步調升通過門檻(Ratcheting):一旦測試在最低可接受水準通過,就逐步提高門檻,保護免受容量衰退
容量測試環境#
容量的絕對測量理想上應在盡可能複製生產環境的測試環境中進行。配置變更對容量特性的影響往往是非線性的——例如調整 UI 會話數與應用伺服器連線數、資料庫連線數的比例,就可能使系統整體吞吐量提升一個數量級。
如果容量或效能是應用的關鍵議題,應投資建立生產環境的副本,使用相同的硬體與軟體規格。
不要天真地假設應用程式會隨硬體參數線性擴展。例如,假設測試處理器的時脈速度是生產伺服器的一半,就認為應用在生產環境會快兩倍,這不僅假設應用是 CPU 限制的,還假設 CPU 速度增加後仍然是瓶頸。複雜系統很少以如此線性的方式運作。
對於部署在伺服器農場(Server Farm)的應用,一個有效的策略是複製一個切片而非整個農場:
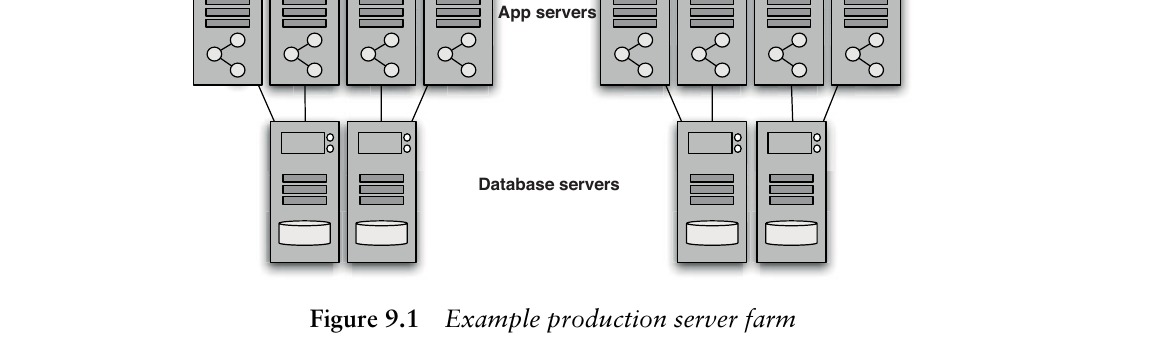
Figure 9.1: Example production server farm
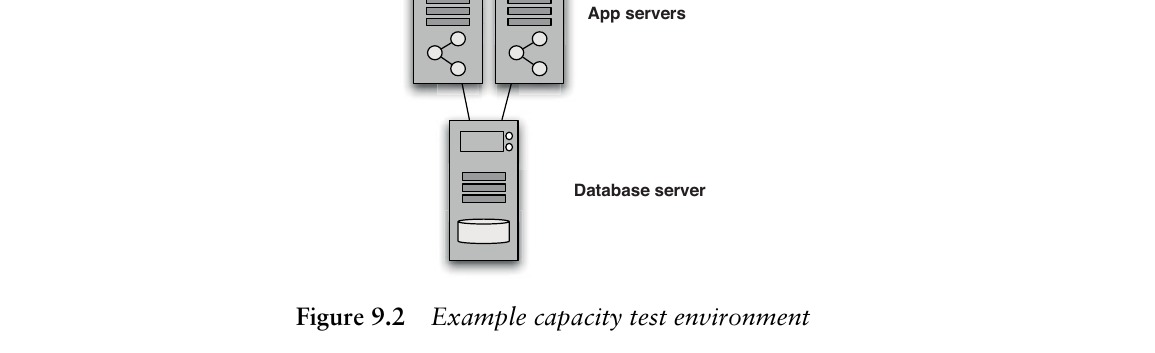
Figure 9.2: Example capacity test environment
例如,若生產環境有 4 台 Web 伺服器、8 台應用伺服器、4 台資料庫伺服器,則容量測試環境可使用 1 台 Web、2 台應用、1 台資料庫伺服器。這能提供單一分支的相當準確測量,並揭示多伺服器競爭資源時的部分問題。
自動化容量測試#
過去曾將容量測試視為一個完全獨立的階段,但當容量是專案關鍵議題時,應盡快在引入變更後得知容量影響——這主張將容量測試加入部署流水線。
優良容量測試的特性#
| 特性 | 說明 |
|---|---|
| 測試特定的真實世界情境 | 避免過度抽象的測試遺漏重要缺陷 |
| 具有預定義的成功門檻 | 能判斷是否通過 |
| 執行時間短 | 使測試能在合理時間內完成 |
| 面對變更具有韌性 | 避免因應用變更而不斷重寫 |
| 可組合為大規模複雜情境 | 模擬真實世界的使用模式 |
| 可重複執行 | 能循序和平行運行,以建立負載套件和執行長時間測試 |
記錄與回放策略#
一個好策略是將既有的驗收測試改造為容量測試。驗收測試已代表真實的互動情境且面對變更較為穩固,只需補上擴展負載的能力和成功標準的規格。
根據系統架構,記錄與回放的注入點有三種選擇:
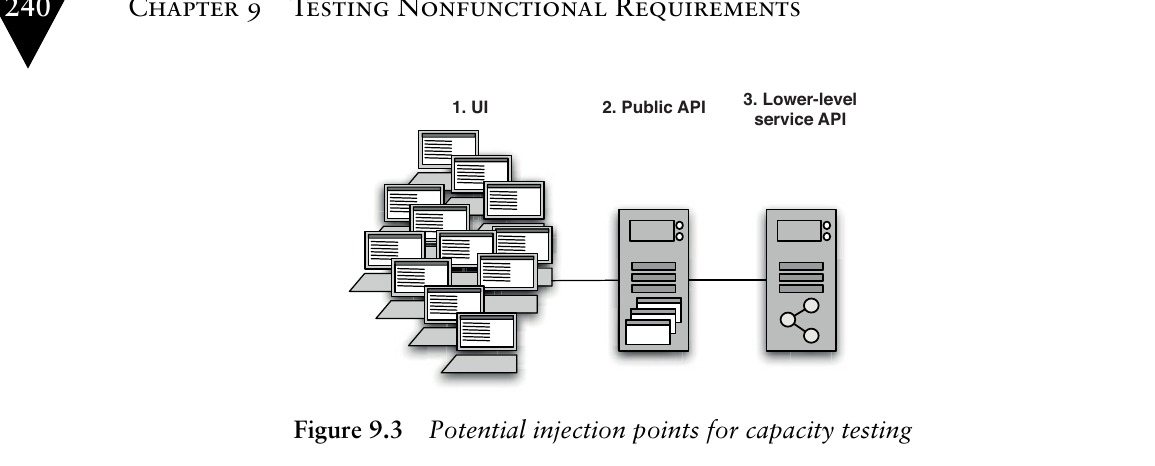
Figure 9.3: Potential injection points for capacity testing
- 透過使用者介面(UI)
- 透過服務或公開 API——例如直接向 Web 伺服器發送 HTTP 請求
- 透過較低層級的 API——例如直接呼叫服務層或資料庫
透過 UI 的容量測試#
這是最常見的方式,也是大多數商用負載測試工具的運作點。但對高流量系統而言並不實際——需要數千台客戶端機器來注入負載。此外,UI 測試較為脆弱且維護成本高。
對分散式系統,作者建議將容量測試分離:找到中間的記錄與注入點來測試伺服器,並獨立定義 UI 客戶端測試(讓 UI 對抗後端的 stub 版本)。
透過服務或公開 API 記錄互動#
對於提供 Web 服務、訊息佇列或其他事件驅動通訊機制的應用,這是理想的記錄點。可繞過客戶端擴展、管理複雜度和 UI 脆弱性的問題。
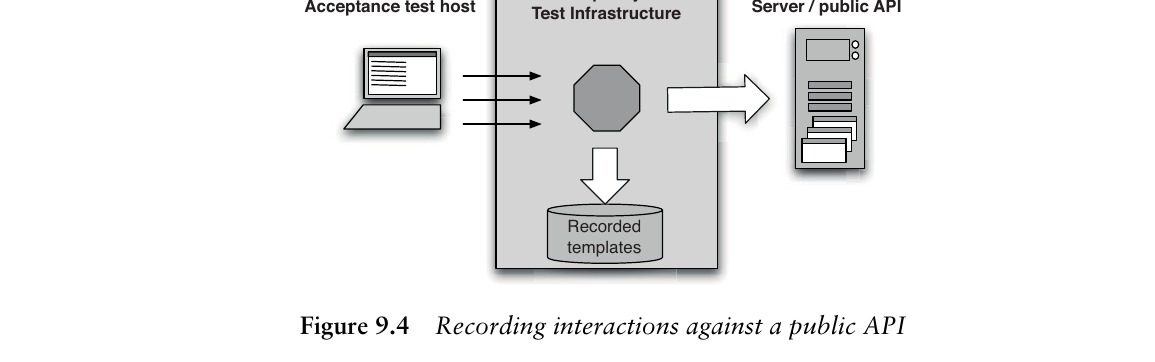
Figure 9.4: Recording interactions against a public API
使用互動範本(Interaction Templates)#
記錄互動的目的是取得一種範本,後續用來生成容量測試資料。流程如下:
- 執行驗收測試的特殊運行:注入額外程式碼記錄互動,將輸入輸出副本存到磁碟
- 標記可替換欄位:部分值(如訂單號碼、客戶 ID)被標記為未來替換用,其餘保持不變——替換越少越好,降低測試與資料的耦合
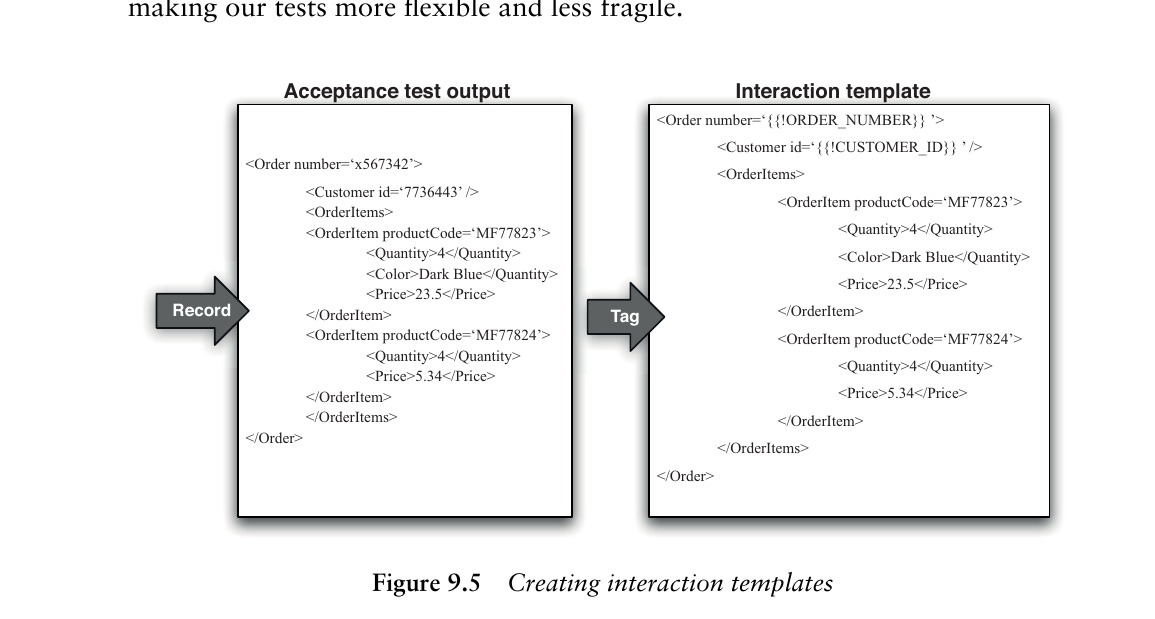
Figure 9.5: Creating interaction templates
- 生成測試資料:為每個範本建立多組測試資料,每組資料搭配範本即為一個有效的互動實例

Figure 9.6: Creating test instances from interaction templates
- 加入成功標準:為範本所代表的測試添加通過條件
- 執行容量測試時:將各測試實例回饋至系統的同一注入點
互動範本和測試資料也可作為開源效能測試工具(如 Apache JMeter、Marathon、Bench)的輸入,或自行編寫簡單的測試工具來管理和執行。
flowchart TD
A[1. 執行驗收測試\n記錄所有互動] --> B[2. 標記可替換欄位\n建立互動範本]
B --> C[3. 為每個範本\n生成多組測試資料]
C --> D[4. 加入成功標準\n定義預期回應]
D --> E[5. 注入系統\n執行容量測試]使用容量測試 Stub 開發測試#
對高效能系統而言,容量測試本身的複雜度可能超過被測程式碼。因此,務必先實作一個簡單的 no-op stub,驗證測試本身能在所需速率下正確運行並斷言通過——避免因測試自身跟不上速度而誤判應用失敗。
將容量測試加入部署流水線#
大多數應用需要滿足某個最低容量門檻。在開發期間,需要能斷言應用達到客戶要求的容量。
放置位置的考量#
如果能在幾秒內證明應用達標,可將容量測試加入 Commit 階段以獲得即時回饋。但要注意依賴執行時期最佳化編譯器的技術(如 .NET 和 Java),需要數分鐘的「暖機」才能得到穩定結果。
對已知效能熱點,可建立快速的**守護測試(Guard Test)**作為效能冒煙測試——不能證明應用滿足所有效能標準,但能凸顯錯誤的趨勢。
但大多數容量測試不適合放在 Commit 階段或驗收測試階段,原因包括:
- 容量測試需在專屬環境運行,避免與其他測試同時執行影響結果
- 某些容量測試耗時極長,會延遲驗收測試結果
- 驗收測試後的許多活動(展示軟體、手動測試、整合測試)可與容量測試平行進行,不應被容量測試阻擋
- 某些專案不需要像驗收測試一樣頻繁地執行容量測試
flowchart TD
A[容量測試] --> B{能在幾秒內完成?}
B -->|是| C[放入 Commit 階段]
B -->|否| D{是否為效能熱點?}
D -->|是| E[建立快速守護測試\n作為效能冒煙測試]
D -->|否| F[建立獨立的\n容量測試階段]
E --> F作者建議將自動化容量測試作為部署流水線中一個完全獨立的階段。
Figure 9.7: The capacity test stage of the deployment pipeline
容量測試階段的流程遵循驗收測試階段的範本:準備部署 → 部署 → 驗證環境與應用配置 → 執行容量測試。根據專案需求,可視為全自動部署閘門(測試不通過則不能部署),或搭配 YAGNI(You Ain’t Gonna Need It) 原則,做最少量的工作達到目標,將最佳化延後到明確需要時再進行。
容量測試系統的額外效益#
容量測試系統通常是最接近生產環境的模擬環境,是極有價值的實驗資源。若按照情境式測試設計,等於擁有一個生產系統的精密模擬器,可用於:
- 重現複雜的生產缺陷
- 偵測與除錯記憶體洩漏(Memory Leaks)
- 長時間運行測試
- 評估與調校**垃圾回收(Garbage Collection)**的影響
- 調校應用與第三方配置(作業系統、應用伺服器、資料庫)
- 模擬最壞情境的病態負載
- 評估複雜問題的不同解決方案
- 模擬整合失敗
- 測量不同硬體配置下的可擴展性
- 對外部系統進行負載測試
- 演練複雜部署的回滾(Rollback)
- 選擇性地使應用部分失效,評估服務的優雅降級(Graceful Degradation)
容量測試系統本質上是一個實驗平台,可以有效地加速或減慢時間來滿足需求,用以設計和執行各種實驗來診斷問題或預測問題並制定應對策略。
總結#
- NFR 的跨領域特性使其風險管理困難,容易導致兩種癱瘓行為:從專案初期就不夠重視,或防禦性架構與過度工程
- 技術人員傾向於完整、封閉的解決方案,但 NFR 要求技術人員在分析中投入更多,這可能偏離業務價值
- NFR 如同橋樑建造者確認樑柱強度——這些需求是真實的,必須被考量,但不是出資者心中所想的。技術人員必須與客戶和使用者密切合作,根據真正的業務價值來定義詳細的 NFR
- 確定 NFR 後,交付團隊應選擇合適的架構,並以與功能需求相同的方式捕捉 NFR 的需求和驗收標準,使其可被估算和排定優先順序
- 建立並維護自動化測試確保 NFR 被滿足,這些測試應作為部署流水線的一部分,在每次變更通過 Commit 測試和驗收測試後執行
- 以驗收測試為起點,進行更廣泛的情境式 NFR 測試,是獲得全面且可維護覆蓋率的絕佳策略