線性迴歸的奇蹟與危險#
NASA 能讓 New Horizons 探測器飛行 9 年、跨越 45 億公里,僅誤差 72 秒就抵達冥王星。地球上的問題卻遠比真空中的航行複雜:「若 X 發生,Y 會如何?」
最常用的工具誕生於 200 多年前:高斯(Carl Gauss)用「最小平方法」幫助發現第一顆小行星穀神星——也就是現代所稱的「線性迴歸(linear regression)」。
線性迴歸做的事很簡單:穿過雜亂資料找一條最佳直線。 接著就能:
- 補資料缺口
- 看斜率知變動影響
- 找曲線何處為零
- 甚至「預測未來」
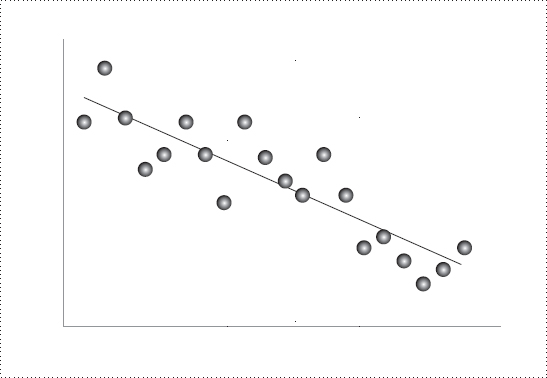
Linear regression finds the 'best' line through messy data – up to a point
凱吉定律:迴歸的笑話#
把上一章 Cage 電影 vs 溺斃資料丟給試算表跑迴歸:
$$ \text{溺斃人數} = 5.8 \times \text{Cage 電影數} + 87 $$
相關係數 +0.67,p = 0.025「統計顯著」。字面上意味著:每多一部 Cage 電影就多 6 人溺斃。
這當然是胡扯。但迴歸軟體不會告訴你「你這分析根本不該做」。 它就像 Frankenstein 醫師的助手 Igor,你叫它做什麼它就做。
線性迴歸的「使用條款」#
許多被忽略的關鍵假設:
- 資料其實是直線關係——若實際是香蕉形,硬擬合直線結果荒謬
- 誤差無模式(無自相關)——時間序列資料常違反
時間序列分析(time series analysis)是處理後者的專門領域,需要專業知識——但即使專家也常出錯。
案例:Google Flu Trends 的崩潰#
2009 年 Google 與 CDC 合作的 Google Flu Trends(GFT)發表於《Nature》:
- 從歷年搜尋資料挖掘 4.5 億模型
- 最佳模型用 45 個關鍵字,與流感爆發相關係數 0.97
- 領先 CDC 自家系統 1–2 週預警
結果:
- 2009 年完全錯失一波流感爆發,需打補丁
- 之後預測仍時常高估
- 2014 年同行論文指出,GFT 連最基本的「自相關」都沒處理
- 2015 年 Google 關閉 GFT 網站
「資料夠多就讓數字自己說話」是徹底的胡說。 Big Data 仍受同樣的 T&C 約束,且還有額外陷阱。 連 Google 的精英都能挖到「愚人金(fool’s gold)」——其他公司更要小心。
大數據的商業現實#
2014 年全球調查顯示,到 2016 年約 75% 企業會投資 Big Data,市場規模約 $1,250 億。但:
- 業內人警告,許多企業打算「挖任何資料」——必失敗
- Netflix 2006 年祭出 $100 萬獎金徵求更好推薦演算法,三年後得獎隊伍勝率提升 10%—— Netflix 卻從未上線——因為太複雜,IT 升級成本過高,效益不划算
業務主管或許不懂自相關,但他們很清楚自己的銷售預測是不是亂七八糟。
數據挖掘的常見陷阱#
- 偏差:10 億筆「篩選過」的資料,可能比一小群隨機抽樣更有誤導性
- 隨手挖出的「顯著」相關:10 個變數兩兩配對,90% 機率冒出至少一個僥倖顯著
- Jeffreys–Lindley 悖論:資料越多,傳統顯著性檢定越無法剔除僥倖
- 偏差-變異權衡:變數越多,舊資料擬合越好,新資料表現越差
數據挖掘不是「越多越好」——而是要在偏差與變異間取得平衡。
案例:「冪次律熱潮」翻車#
1980 年代起,研究者用線性迴歸(在對數座標下)尋找冪次律:
$$ \text{某現象} = k \times (\text{某可量測量})^N $$
從市場波動到螞蟻覓食、信天翁飛行、海豹捕獵都出現「Lévy 飛行」式冪次律。1990 年代中還有專書《How Nature Works》問世。
但 2005 年生態數學家 Andrew Edwards 用更穩健的方法重新檢驗 17 篇宣稱發現此模式的論文——
沒有一篇站得住腳。 信天翁案例後續用先進方法重做,可能仍存在類似模式——但原始論文的論證理由是錯的。
Is it a bird, is it a scribble? No, it's a Lévy flight – and a warning about pushing data too far
結語#
任何資料集都有「模式」——但多數是幻覺。 找出「最佳擬合線」不會改變這件事。 不論宣傳多盛,Big Data 仍逃不過 GIGO(Garbage In, Garbage Out)。 把資料挖掘的「使用條款」忽略到底,你會得到一台「21 世紀產製古典荒謬」的機器。