Tyler Vigen 的「發現引擎」#
哈佛法學研究生 Tyler Vigen 寫了一個自動化的「發現引擎」——掃網路上各種資料集,找出**相關係數(correlation coefficient)**接近 +1 或 -1 的成對組合。
相關係數從 -1(負相關)→ 0(無相關)→ +1(正相關)。 高絕對值意味著「兩變數的高低值同步變化」。
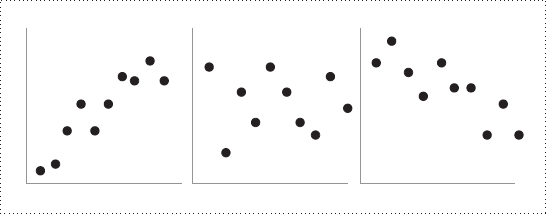
Three degrees of correlation: +0.85, 0.0, –0.85. All can be important — or twaddle
引擎產出大量荒謬卻「統計顯著」的「發現」:
- 尼可拉斯・凱吉電影上映數 vs 美國泳池溺斃人數(+0.67)
- 美國從日本進口汽車 vs 自殺式車禍人數(+0.94)
- 起司消費量 vs 被床單纏死人數(+0.97)
- 緬因州人均人造奶油消費量 vs 離婚率(強相關)
- 美國從挪威進口石油 vs 火車撞死駕駛人數(+0.96)
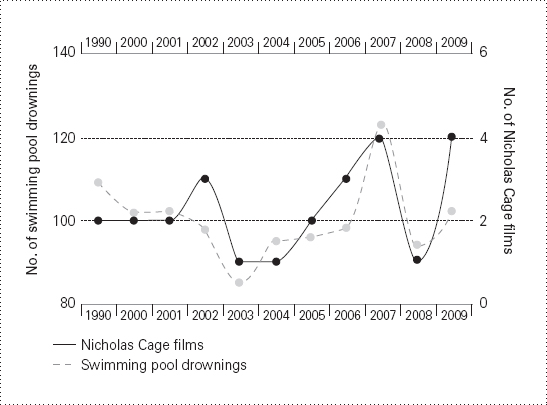
Why you should avoid swimming pools if Nic Cage has a movie out
這些自動產出的「相關」幾乎都會通過傳統的「統計顯著」檢定。 換句話說,研究界倚賴的標準工具根本擋不住這些垃圾。
排除荒謬「發現」的方法#
工具 1:合理性#
最容易的篩選——這個關聯在生物、物理、社會層面講不講得通?
工具 2:細看原始數據#
凱吉每年作品數變動小(最多 3 部),泳池溺斃年均約 100 人(85–123 之間)。十年資料中,恰巧兩個極端年同步出現,離群值就讓相關係數飆到 +0.666(驚悚)。
「資料清洗(data cleaning)」可以正當地剔除確認為實驗誤差的離群值——但有時離群值是冪次律等真實現象的一部分,不能任意刪。 凱吉案例清掉離群值後,相關性砍半且不再顯著。
工具 3:相關 ≠ 因果#
「相關不等於因果」。即使統計上強且可信,仍可能是:
- 巧合
- 共同的隱藏混淆因子(confounder)
範例:嚴重曬傷與防曬乳銷量、冰淇淋、冷飲銷量都高度相關——共同混淆因子是太陽。
案例:大麻與 IQ#
2012 年發表的研究宣稱:
- 青少年起持續重度使用大麻者,到 30 多歲 IQ 下降 8 點
- 已控制酒精、硬性毒品等混淆因子
但隨即被質疑:
- 一千多人原始樣本經過多重排除後,最後分析只剩幾十人
- 未考慮「Flynn 效應」——多年來各國 IQ 普遍上升的現象
- 把 Flynn 效應納入後,大麻效應幾乎消失
大麻使用者並非因此清白——而是這提醒我們: 即便已得到「正確」答案,仍要繼續尋找混淆因子。
「漂亮數據」的陷阱#
陷阱 1:用平均代替個別資料#
把雜亂的個別資料平均成「漂亮的點」,相關係數會誇大:
- 美國各州「教育水準與收入」相關係數:+0.64
- 但用個人普查資料:相關係數降至 +0.44
陷阱 2:使用「率」(rate)#
統計學奠基者皮爾森(Karl Pearson)就警告過:用「每千人」、「每月」這類率作相關時容易誤導。理論與實證都已證實——但商業與學術仍大量使用率相關。
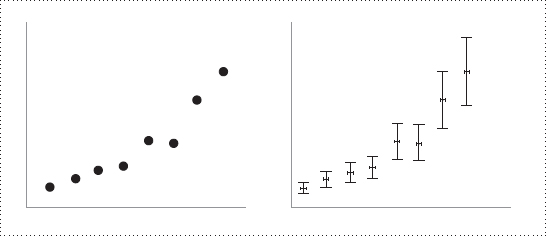
Correlated data: the neat presentation version – and the messy, uncertain raw stuff
別忘了:相關 = 線性關係#
簡單相關係數只測線性關係。看下圖:
東京一年 12 個月的氣溫變化呈先升後降的拋物線。 線性相關係數僅 0.36,p 值 0.25「不顯著」。 但這個關聯在每個意義上都既真實又「顯著」——只是不是直線。 盲目套用相關公式會讓你錯失真正的洞見。
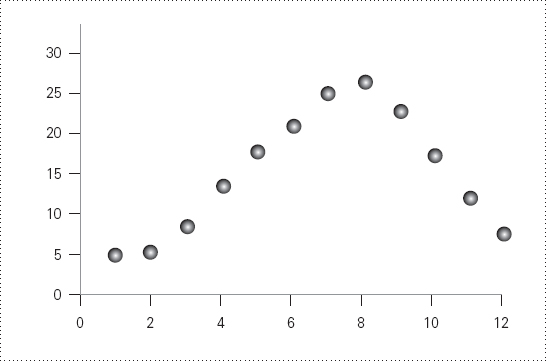
It's clear something's going on here – unless you mindlessly use correlation analysis
結語#
相關性就像巧合——若我們知道找出它有多容易,便不會輕易當真。 量測相關有許多強大方法,但只要你執著於「這個模式背後一定有什麼」,它們全都會誤導你。