把微服務改造完不改組織,等同付了昂貴架構代價卻拿不到回報。本章探討如何把鬆耦合的架構與鬆耦合的組織對齊。
鬆耦合的組織#
Forsgren、Humble、Kim 在《Accelerate》中歸納出鬆耦合自治團隊的指標——團隊能否在不依賴其他團隊的情況下完成下列事情:
- 對自己系統做大規模設計變更(不需外人核可)
- 對系統做大規模變更而不必動別人或讓別人改
- 完成工作而無須與外部協調
- 隨需發佈,不受相依服務的限制
- 隨需測試,不需要整合測試環境
- 工作時間內部署且影響不顯著
把這份清單當作 stream-aligned team 的健檢指標。本質上需要權力與責任的分散化——不只是技術變更,還是行為與決策模式的變更。
康威定律#
Melvin Conway, 1968:
「Any organization that designs a system… will inevitably produce a design whose structure is a copy of the organization’s communication structure.」
(任何組織所設計的系統,其結構必然複製該組織的溝通結構。)
Eric S. Raymond 在《The New Hacker’s Dictionary》補一刀:「如果你有四個團隊在做編譯器,你就會得到四階段編譯器。」
這個定律的逆向理解同樣重要:鬆耦合的組織會產生鬆耦合的架構。想要微服務帶來的彈性,組織不變、架構也變不了。
證據#
- MacCormack 等人 2012 年研究:鬆耦合(如分散式開源社群)開發的軟體比緊耦合公司開發的更模組化
- Microsoft Vista 內部研究:組織結構指標(多少工程師動過某段程式)比程式碼複雜度指標更能預測 bug 機率
- Amazon、Netflix:早期就明白「小而獨立的團隊產出獨立服務」;Amazon 的雲端服務(AWS)正是為了讓 two-pizza team 自給自足而生
團隊大小#
根據《Empirical Findings on Team Size and Productivity in Software Development》研究,平均人數 ≥ 9 的團隊生產力顯著下降。Amazon 的「two-pizza team」就是這個概念——能用兩塊披薩餵飽(約 8-10 人)的團隊。
太大的團隊出錯:
- 同步變慢
- 跨界協調成本暴增
- 加人不一定變快(Brooks’s Law: Adding manpower to a late software project makes it later)
用「許多小團隊」組成「大組織」#
「The biggest cost to working efficiently at scale in software delivery is the need for coordination.」
越多協調 = 越慢。Amazon 把限制協調寫進公司 DNA:團隊互動有限、有明確介面,獨立的團隊跑得快。
Team API(Team Topologies)#
每個團隊應該定義自己對外的「API」:
- 我們對其他團隊有多容易合作?
- 別的團隊上手要多久?
- 我們的待辦清單與藍圖透明嗎?
- 對外部 PR 怎麼回應?
不是程式介面,而是人和流程的介面。
自治(Autonomy)#
「Whatever industry you operate in, it is all about your people, and… providing them with the confidence, the motivation, the freedom and desire to achieve their true potential.」
——John Timpson
- W.L. Gore 公司:每個業務單位上限 150 人——對應 Robin Dunbar 的「Dunbar number」
- Timpson 公司:把所有內部規則簡化為兩條——「穿著得體」「把錢放收銀機裡」——其餘讓員工自己決定,包括退款額度
別只是抄 Spotify 模型或 Amazon 模型——不理解為什麼那樣做卻照搬,期待相同結果,多半碰壁。
強擁有 vs 集體擁有(Strong vs Collective Ownership)#
| 模型 | 說明 |
|---|---|
| 強擁有(Strong Ownership) | 微服務由一個團隊擁有;外部要改要麼請該團隊代勞、要麼送 PR(由該團隊決定接不接) |
| 集體擁有(Collective Ownership) | 任何團隊都能改任何微服務 |
強擁有#
- 該團隊決定程式風格、發佈時機、技術選型、部署平台
- 自治程度最高——外部協調最少
- 允許「局部變異」(local variation)——例如某團隊要用函數式 Java;只要不影響別人就 OK
- 進階版:全生命週期擁有(Full Life-Cycle Ownership)——從設計、實作、部署、維運到退役都由同一團隊負責
集體擁有#
- 好處:人力可以彈性流動,瓶頸時可調撥支援
- 代價:需要強制統一技術棧、開發風格,否則跨團隊修改成本爆炸
- 把 James Lewis 的「microservices buy you options」逆轉了——選項變少了
- 協調量大 → 組織耦合 → 進而導致系統耦合
多團隊組織建議:團隊內用集體擁有(每人都能改該團隊的程式碼);組織層級用強擁有(每個微服務由一個團隊擁有)。
全球一致 vs 局部優化#
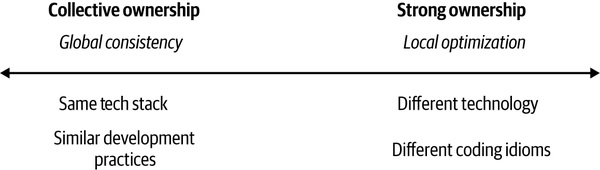
Figure 15.1:全球一致與局部優化的天平
- 集體擁有越強 → 越偏左(要全球一致)
- 強擁有越強 → 越偏右(允許局部優化)
- 平衡不必固定——可以「程式語言完全自由 + 部署平台必須統一」
賦能團隊(Enabling Teams)#
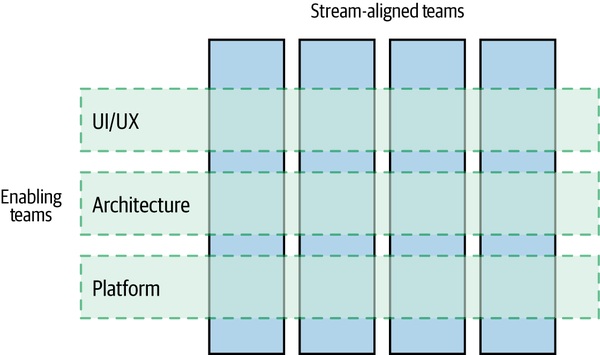
Figure 15.2:賦能團隊支援多個 stream-aligned team
不直接交付產品,而是幫其他團隊變強。
- 像內部顧問——花時間進駐 stream-aligned team 解決棘手問題、教方法
- 結束後團隊應該更自給自足,而非更依賴
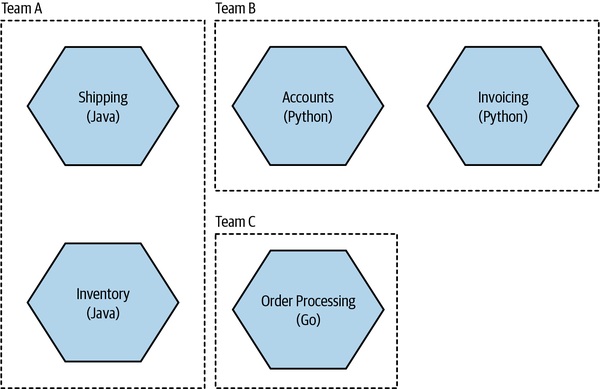
Figure 15.3:每個團隊各自選了不同程式語言——這真的是組織想要的嗎?
賦能團隊也是現代「架構師」的好歸屬——舊式架構師發號施令,新式架構師觀察、串連、提供諮詢,是另一種賦能團隊。
實踐社群(Communities of Practice, CoP)#
- 跨團隊的學習論壇——成員每週投入幾小時
- 來自 Emily Webber《Building Successful Communities of Practice》
- 與賦能團隊的差異:CoP 重在學習;賦能團隊重在動手協助執行
- 兩者互補:例如 Kubernetes CoP 把使用痛點回饋給平台團隊
平台團隊(Platform Team)#
RVU’s CTO Paul Ingles:
「We didn’t change our organisation because we wanted to use Kubernetes; we used Kubernetes because we wanted to change our organization.」
平台團隊的使用者就是其他開發者——目標是讓他們生活更輕鬆。
- 提供共通積木:日誌聚合、期望狀態管理、跨服務認證授權等
- 別只把自己當作「平台維護者」——把自己當作賦能團隊
- 作者偏好稱為「Delivery Services」或「Delivery Support」
鋪好的路(The Paved Road)#
概念:清楚說明該怎麼做、提供容易做對的工具,但不強制。
「想用 mTLS 通訊嗎?平台預設幫你;但你要繞開也可以。」
衡量平台成功的方式:有多少團隊主動採用它、有多少流量/營收經過它——而不是「禁止你不用平台」。
強制使用平台的後果:當平台不適用某情境,團隊會繞過去;繞過去後就不知道該守什麼底線。
共享微服務(Shared Microservices)#
雖然作者主張強擁有,但實務上常見共享微服務。可能原因:
1. 太難拆#
舊單體系統一時拆不開——回到第 3 章建議的漸進拆解。
2. 跨領域變更#
有些變更真的會橫跨多個服務。FinanceCo 案例:「一帳戶一使用者」改成「一帳戶多使用者」——上百個微服務都要動。
重組架構與團隊以降低某類常見變更的代價,可能讓另一類稀有變更變昂貴。FinanceCo 接受這個 trade-off——稀有變更值得多痛一次。
3. 交付瓶頸#
選項:
- 等
- 加人
- 拆服務(如果這方向會持續發展)
- 採用內部開源(Internal Open Source)——下面詳述
內部開源(Internal Open Source)#
仿照 OSS 模式:核心 committer + 外部投稿(PR)。
重點:核心 committer 要好好把守品質。守不住的 PR 會讓服務一致性崩潰;過度刁難又變成濫用權力。
採用前提:
- 服務要相對成熟(不成熟時連自己人都還不知道什麼是「好」)
- 工具到位:分散式版控、PR 機制、註解審查、CI、artifact repository
模組化、可插拔的微服務#
FinanceCo 案例:中央服務需要為每個國家做客製,PR 多到中央團隊吃不消。
選項:
變更擁有權#
如果 PR 大量來自單一團隊,乾脆把服務交給那個團隊。
「團隊有大量 inbound PR」是個訊號——很可能這個服務根本應該由別的團隊擁有。
多份變體(Variations)#
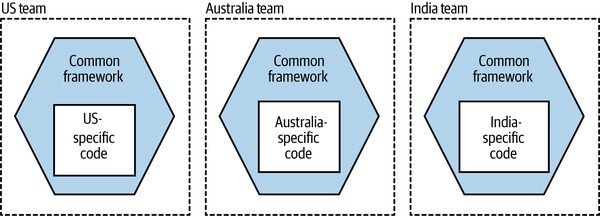
Figure 15.4:以共用框架支援每個國家的變體
每個國家團隊跑自己的變體——共通邏輯做成 framework;缺點是無法 lockstep 升級共通邏輯。
函式庫貢獻#
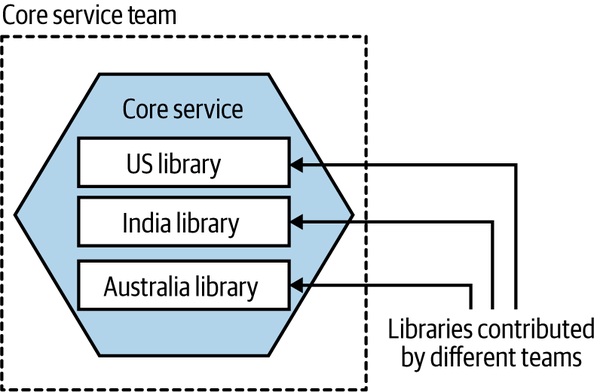
Figure 15.5:各團隊以 library 形式貢獻自己國家的客製邏輯
各國團隊產出 library 包進中央服務 → 仍是單一服務,但部署時機由中央團隊決定。要承擔某國 library 的 bug 連帶影響其他國家。
「自製 framework」常常變成噩夢——一開始美意,後來變成綁住所有人的枷鎖。先用盡其他選項再走這條路。
變更審查(Change Reviews)#
- Pair Programming:邊寫邊審——最即時、最深入的審查
- 同儕審查(Peer Review):同團隊內審查——《Accelerate》研究指出能提升交付效能
- 外部審查:通常負相關——非團隊成員、不熟悉脈絡,又會延遲
不做 pairing 時,code review 越快越好——理想是面對面同步討論。讓 reviewer 等好幾天才看,整個流程效率崩潰。
Ensemble Programming(Mob Programming)#
整個團隊一起寫一段 code——對特定棘手問題 OK。但作者對它有保留:團隊神經多樣性(neurodiversity)+ 權力不對稱讓它不一定能讓所有人安全發聲。「在房間裡 ≠ 真正貢獻」。
孤兒服務(The Orphaned Service)#
服務本身穩定、好幾個月沒改 → 誰擁有?
- 若團隊邊界對應到限界上下文,自然有事實上的擁有者
- 即使沒人改,需要時擁有團隊還能重寫——微服務小,重寫成本相對低
- 但若該服務是另一種技術棧、團隊已不熟悉,麻煩就大了——多技術棧的代價
案例:realestate.com.au#
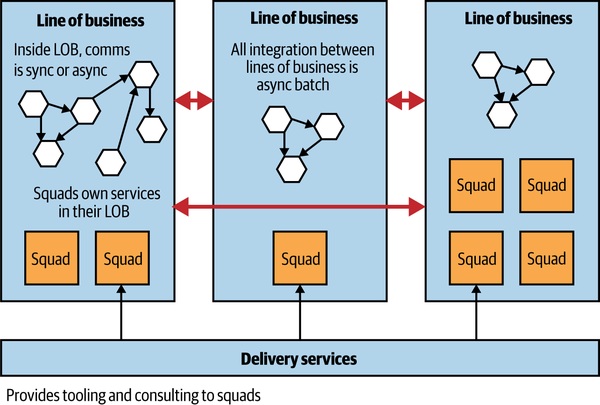
Figure 15.6:REA 2014 年的組織與架構對齊
2014 年的 REA:
- 核心業務拆成多條業務線(Lines of Business, LOB):住宅、商用、海外
- 每個 LOB 內有一到多個團隊(Squad)
- 每 squad 端到端擁有自己的服務生命週期
- 中央Core Delivery Services Team 扮演賦能團隊角色(提供工具、建議)
- LOB 內部任何整合方式都行;LOB 之間規定只能用非同步批次——對應業務之間的粗粒度溝通
「向其他組織學習是好的;不理解他們為什麼那樣做卻照搬,是愚蠢的。」
地理分布#
- 同地點 → 同步溝通最簡單
- 跨時區 → 同步成本高,作者親身經歷澳洲 + 印度/英國/巴西/美國的協調困境
- 時區差距是團隊邊界的強訊號:地理分散的團隊應對應粗粒度的服務介面
- 當組織開新國家辦公室時,正好可以借機重新切分系統
反向康威定律#
「組織影響架構」之外,架構也會影響組織。
作者見過案例:某印刷公司起家、網站早期僅是配菜——卻因為網站系統的 input/core/output 三段式設計,公司 IT 部門逐漸長出三個部門呼應這三段。最後業務數位化、必須改架構,但組織也要跟著變才行。
人#
「No matter how it looks at first, it’s always a people problem.」
——Gerry Weinberg, The Second Law of Consulting
- 從單體到微服務 → 開發者必須面對網路呼叫、失敗模式、跨語言操作
- 從「丟過牆給別人」到「自己負責 oncall」 → 不是每個人都樂意
- 別硬推太快——找願意先動的人試水
- 可能要從外部找對的新人進來示範——讓老人看到可能性
小結#
- 康威定律告訴我們:強迫不對齊組織的架構是徒勞
- 多團隊組織下,強擁有是預設選擇;集體擁有在規模放大時會反過來綁架你
- 平衡全球一致與局部優化——以強擁有為基礎,再針對需要的點要求一致
- 賦能團隊、實踐社群、平台團隊各有角色,都是為了讓 stream-aligned team 跑得更快
- 內部開源、共用框架等「共享」手段在特殊情境有用,但不該是預設模式
- 推薦延伸閱讀:Skelton & Pais《Team Topologies》、James Lewis《Scale, Microservices and Flow》(YOW! 演講)