「You’re gonna need a bigger boat.」
——Chief Brody, Jaws
我們擴展系統有兩個目的:提升效能(更多吞吐、更低延遲)或提升韌性(多備一份避免故障)。微服務在這兩面都提供豐富選項,但複雜度也跟著升高。
規模化的四個軸#
來自 Martin Abbott 與 Michael Fisher《The Art of Scalability》的「Scale Cube」,作者再加上垂直擴展這一軸(雖然立方體因此變成四維 ⋯)。
| 軸 | 簡述 |
|---|---|
| 垂直擴展(Vertical Scaling) | 換更大的機器 |
| 水平複製(Horizontal Duplication) | 多個複本同時做相同工作 |
| 資料分區(Data Partitioning) | 依資料屬性切分(如客戶群) |
| 功能拆解(Functional Decomposition) | 依工作類型拆解(即微服務拆分) |
本章用 MusicCorp 與虛構案例 FoodCo(多國送餐公司)穿插說明。
垂直擴展(Vertical Scaling)#
在公有雲時代,垂直擴展往往是「先試試看再說」的低風險選項——按小時計費、改機型不需要重寫程式。
- 換大機器最直接:升 CPU、升記憶體、升 I/O
- AWS u-24tb1.metal 提供 24 TB 記憶體——你大概用不到,但選項在那裡
限制#
- 現代 CPU 提速越來越靠核心數,不是時脈——軟體沒寫成多核就拿不到提升
- 機器越大不代表越快增加韌性——掛了還是掛了
- 邊際成本遞增:往往一群小機器比一台大機器划算
FoodCo 案例#
- 多年來都靠垂直擴展撐主資料庫
- 已經逼近極限,下一步必須走別的軸
水平複製(Horizontal Duplication)#
複製多份相同的東西,再用某種機制把工作分給它們。
實作方式#
- 負載平衡器(Load Balancer)+ 多個服務實例
- 偵測不健康節點 → 移出池
- 從消費者看是透明的
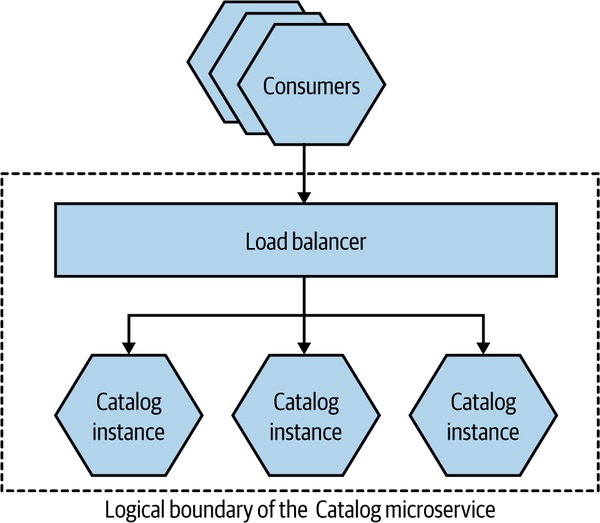
Figure 13.1:Catalog 微服務多執行個體 + 負載平衡器
- 競爭消費者(Competing Consumer)模式:來自《Enterprise Integration Patterns》
- 共用佇列 + 多個 worker 從中搶任務
- 提升吞吐就加 worker
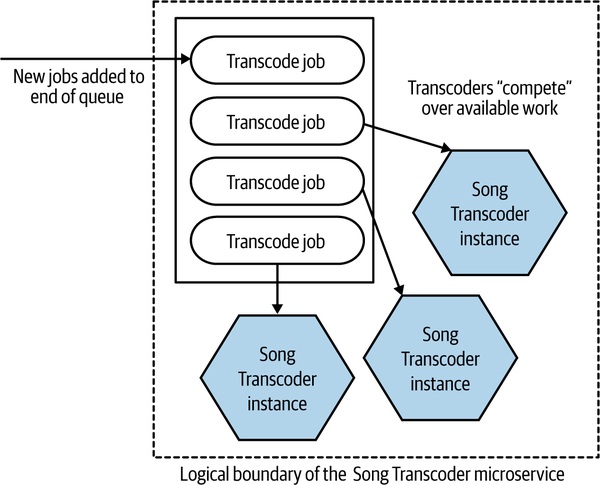
Figure 13.2:Song Transcoder 用競爭消費者模式擴展
- 資料庫讀取副本(Read Replica):FoodCo 用此手法解決讀取瓶頸
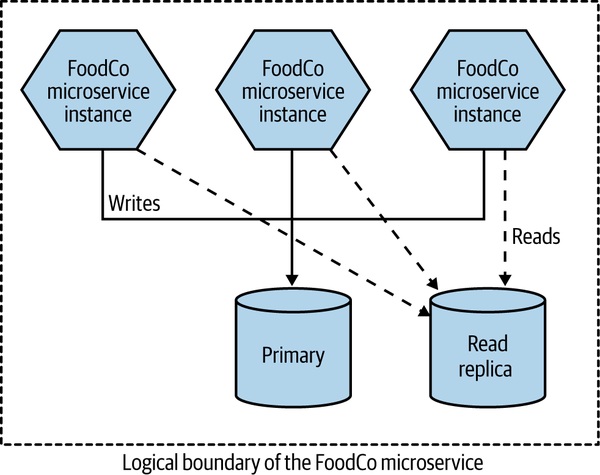
Figure 13.3:FoodCo 用讀取副本擴展讀取流量
限制#
- 需要更多基礎設施 = 成本提高
- **黏性會話(sticky session)**型的架構限制更多——盡量別建這種系統
- 如果只有部分功能需要擴展,水平複製整個單體會浪費資源
資料分區(Data Partitioning)#
按資料的某個屬性切分,把不同切片送到不同節點。也叫做分片(sharding)。
實作方式#
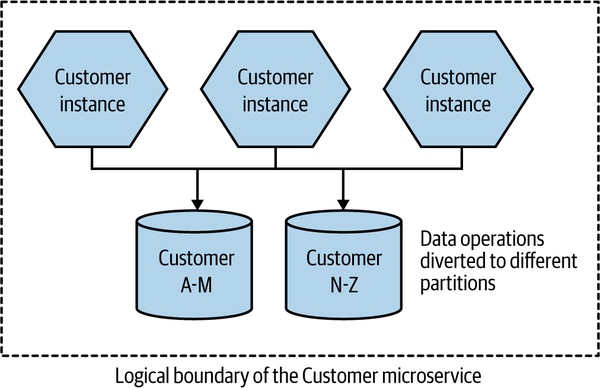
Figure 13.4:客戶資料按姓氏首字母分到兩個資料庫
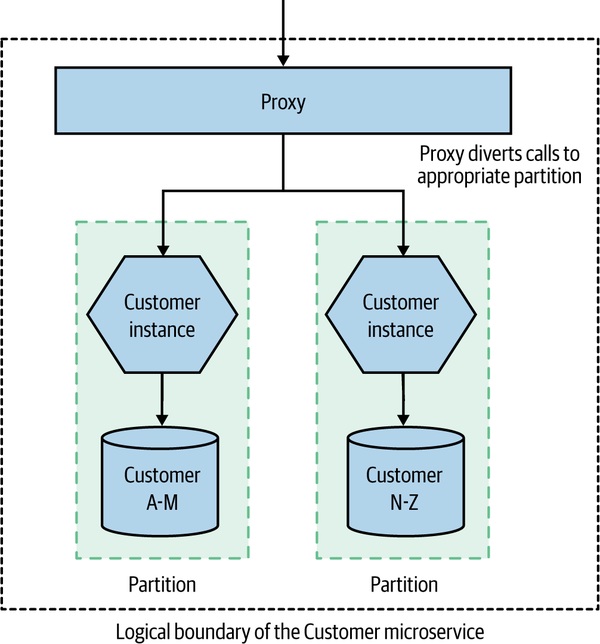
Figure 13.5:依分區把請求路由到對應的微服務實例
- 可在資料庫層分區(讓 DB 自己處理)
- 也可在微服務實例層分區(適合搭配 in-memory cache)
- 常用主鍵:客戶 ID、地理位置
- Cassandra、Kafka 都內建分區機制
限制#
- 分區鍵選錯後果嚴重:上面用「姓氏首字母 A-M / N-Z」是壞例子——華人姓氏中前 100 大已涵蓋 80% 人口,分布極不均
- 改變分區策略代價極高:作者見過為了改主資料庫分區策略 production 停機 3 天
- 跨分區查詢(如「找出所有 18 歲以上客戶」)困難——需要查所有分片再合併或維護獨立讀取庫
- 容錯效益有限:4 個分區一個壞掉 → 25% 請求失敗。通常搭配水平複製一起用
寫入瓶頸是分散式資料庫真正的差異點。撞牆時很多人會換資料庫——延伸閱讀 Pramod Sadalage 與 Martin Fowler《NoSQL Distilled》。
功能拆解(Functional Decomposition)#
最徹底的擴展方式——從現有系統抽出一塊功能變成獨立微服務。
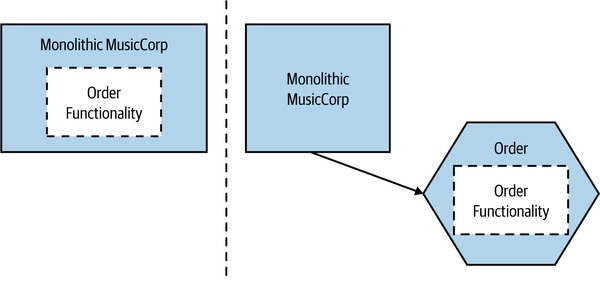
Figure 13.6:把 Order 功能從 MusicCorp 拆出獨立微服務
FoodCo 的下一步#
- 垂直擴展、水平複製、讀取副本都用了,最後選擇功能拆解
- 把交付(delivery)、菜單(menu)相關資料從主資料庫抽出獨立服務
- 額外好處:組織也順勢拆出對應團隊
限制#
- 對程式碼影響最大(前後端都得動)
- 短期不會有明顯效益
- 切完服務數量增加 → 系統整體複雜度增加
- 作者建議:功能拆解放在最後試——除非你還順帶想解決組織問題(FoodCo 就是)
組合不同模型#
多軸組合往往最有效:
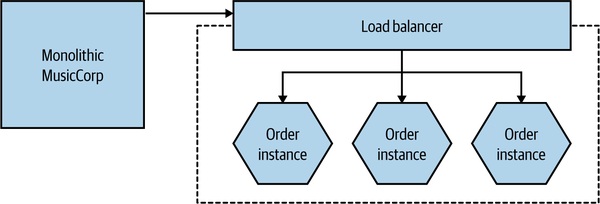
Figure 13.7:拆出的 Order 微服務再做水平複製
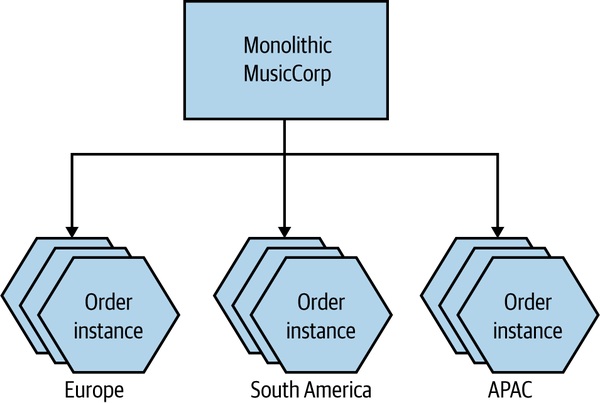
Figure 13.8:Order 按地理分區,每區內再水平複製
一個軸做了,別的軸通常會更容易做。功能拆解之後,你才有能力對特定服務做水平複製或分區。
從小開始#
Donald Knuth:「過早最佳化是萬惡之源(premature optimization is the root of all evil)。」
想當然耳的瓶頸在實驗驗證之前都不算瓶頸。先寫自動化負載測試,建立 baseline、做變更、觀察差異——這是最小可行的科學方法。
快取(Caching)#
「There are only two hard things in Computer Science: cache invalidation and naming things.」
——Phil Karlton
快取的三大用途:
- 效能:減少網路往返、避免重算昂貴查詢
- 規模:把讀流量導去快取,減輕來源(origin)負擔
- 韌性:來源掛了還能用快取資料撐一陣子
在哪裡快取?#
以下用 MusicCorp「找出近七天暢銷 CD」的例子串起來:Sales 服務記錄銷售(含 ID 與時間),但顯示榜單需要曲名 → 必須向 Catalog 取資料。
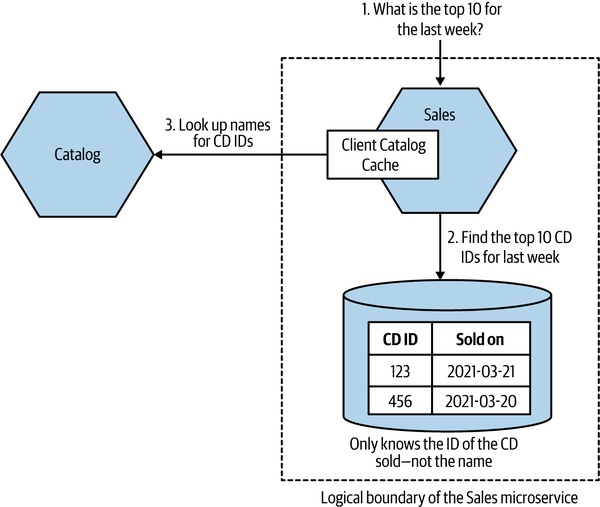
Figure 13.9:MusicCorp 計算暢銷榜的服務組合
客戶端(Client-side)#
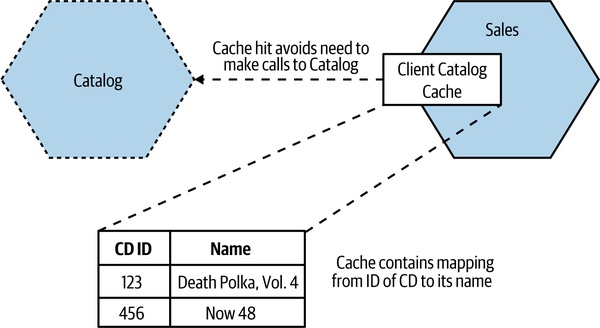
Figure 13.10:Sales 微服務在自己 process 內持有 Catalog 資料的本地副本
- 連網路呼叫都省了 → 效能與韌性最好
- 缺點:多個客戶端各自快取,資料新鮮度不一致
可以折衷:用共享快取(Redis、memcached)統一:
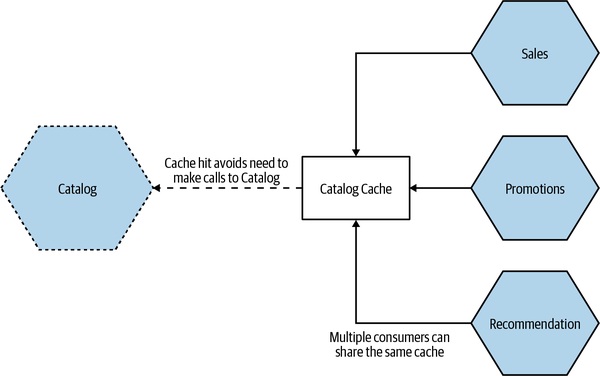
Figure 13.11:多個 Catalog 消費者共用同一個 cache
伺服器端(Server-side)#
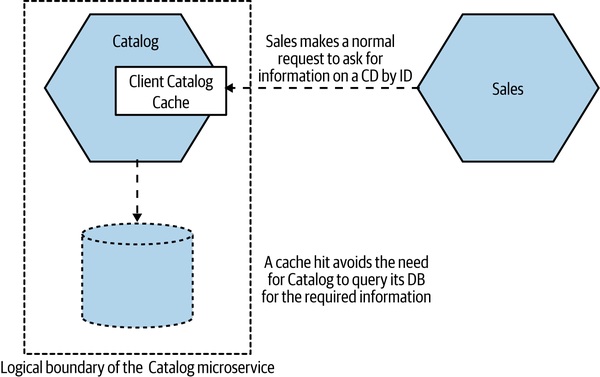
Figure 13.12:Catalog 內部實作快取,對消費者透明
- 對消費者完全透明 → 微服務內部可隨意改實作(in-memory、Redis、read replica 都行)
- 容易做 write-through 等進階失效機制
- 仍需要網路往返 → 對「降低延遲」幫助有限
請求快取(Request Cache)#
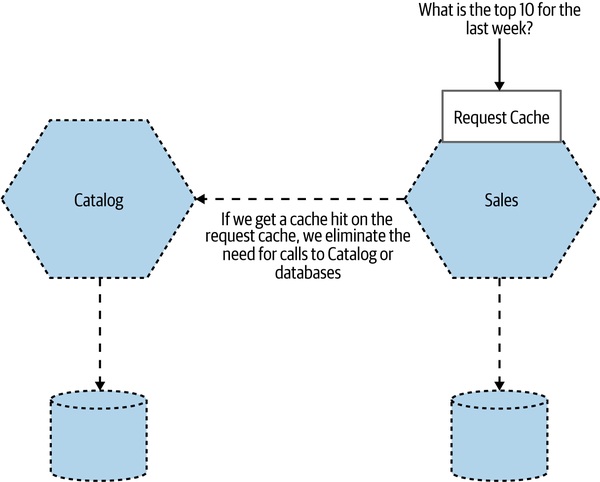
Figure 13.13:直接把 top 10 結果整包快取
- 直接快取最終結果——效能最好
- 缺點:高度針對特定請求,其他操作不受惠
失效機制#
TTL(Time To Live)#
- 最簡單:每筆資料給個過期秒數
- HTTP 的
Cache-Control: max-age=...與Expiresheader 是業界標準 - 缺點:「鈍器」——剛刷新後 1 秒源頭就改,仍會給 4:59 的舊資料
Conditional GET(HTTP 條件式取得)#
- 用 ETag +
If-None-Matchheader - 來源沒變 → 回
304 Not Modified,省掉重組回應的成本 - 仍要送請求,省的是來源端的計算
通知式(Notification-based)#
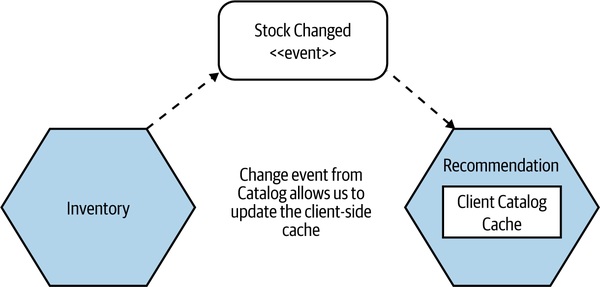
Figure 13.14:Inventory 發 Stock Change 事件,Recommendation 收到後更新本地快取
- 來源發事件,訂閱者收到後失效本地快取
- 最即時,但實作較複雜(需要 message broker)
- 注意:通知系統本身也可能掛——可發定期 heartbeat 確認連線健康
Write-through(同寫穿透)#
- 更新來源時同時更新快取
- 實際上很難真正「同時」——多用於伺服器端快取(同一交易中更新 DB + in-memory cache)
Write-behind(後寫)#
- 先寫快取再寫來源
- 更快,但有資料遺失風險
- 微服務情境下少用——複雜度高、邊界模糊(誰才是 source of truth?)
快取的黃金法則#
「快取的最佳數量是零。」每加一層都讓資料新鮮度變得更難推理。
把快取當作優化手段,需要時才加;加了之後用最少的層數達到目的。
鏈式快取的暗坑#
Inventory 內部 1 分鐘 TTL + Recommendation 用戶端 1 分鐘 TTL → 客戶端拿到的資料最舊可能落後 2 分鐘,而 Recommendation 還以為只有 1 分鐘。
時戳式(timestamp-based)失效比 TTL 在這種情境下更可靠。
中毒的快取(Cache Poisoning)#
AdvertCorp 案例:發版後一個 bug 讓一小部分頁面保留了下游系統的
Expires: Neverheader。Squid cache 清掉沒用——用戶瀏覽器也快取了Never,永遠不會更新。唯一解:改 URL 強迫重抓。提醒:快取鏈延伸到使用者端後,控制權早已不在你手上。
自動擴展(Autoscaling)#
兩種觸發策略:
- 預測式(Predictive):依固定模式(如 9 點到 17 點是尖峰)提前 scale up
- 反應式(Reactive):依即時負載或失敗事件動態調整
新聞網站作者建議的混合:日內走勢用預測式(每天類似),突發大新聞靠反應式。
注意:
- 反應式 scale up 速度跟不上突發負載 → 可能要保留 buffer
- 自動擴展也常被用來「保證至少 N 個實例」——失敗時自動補位
- 不要太快 scale down,多花一點錢比掛掉划算
重新開始(Starting Again)#
某些規模臨界點,沒辦法只靠調參數,必須改架構。
Gilt 案例:兩年用 Rails 單體業務蒸蒸日上 → 撞牆 → 大幅重設計 → 變成 450+ 微服務。
但不要因為「以後會撞牆」就一開始就為極致規模而設計——往往連產品有沒有人要用都不知道。Eric Ries 說過:與其花六個月做沒人下載的產品,不如先放個 404 連結看會不會有人點,再決定要不要做。
撞牆是成功的訊號,不是失敗。
CQRS 與事件溯源#
Command Query Responsibility Segregation(CQRS)把讀寫拆成不同模型。事件溯源(Event Sourcing)用事件流而非當前狀態存實體。
兩者都很複雜,作者見過聰明人在實作時踩坑。先試簡單方案(如 read replica);要用時把它當成微服務的內部實作細節,對消費者隱藏。
小結#
- 規模化四軸:垂直、水平、分區、功能拆解——按需求組合使用
- 從小開始;瓶頸要靠實驗驗證,別憑感覺最佳化
- 快取很強大,但越多層越難管;最佳數量是 0,遞增只能是被需求推著走
- 自動擴展可以省錢,但 scale down 要保守
- 規模成長到一定程度後,重新設計是常態——這是好事,不是失敗