軟體變成生活必需後(疫情期間的線上採買就是經典例子),韌性(resiliency)的要求隨之提高。許多組織採用微服務的主因正是「想提升韌性」——但本章想先說清楚:僅有微服務不足以給你真正的韌性。
什麼是韌性?#
David D. Woods 把韌性切成四個面向:
| 面向 | 中文 | 含意 |
|---|---|---|
| Robustness | 強韌 | 吸收已知擾動的能力 |
| Rebound | 反彈 | 創傷事件後恢復的能力 |
| Graceful Extensibility | 優雅延伸 | 應付未預期狀況的能力 |
| Sustained Adaptability | 持續調適 | 持續適應變動環境、持份者、需求的能力 |
微服務主要在「Robustness」這層幫得上忙;其餘三項都需要人、流程、文化配合,不只是程式碼問題。
Robustness 之外#
- Rebound:備份要做、災難復原劇本(playbook)要演練;事件當下大家壓力下無法理性思考
- Graceful Extensibility:扁平、職責下放的組織比僵化階層更善於應付驚奇——自動化過頭反而讓系統變脆弱
- Sustained Adaptability:從未發生過大故障 ≠ 不會發生;混沌工程是培養此面向的工具
- 三者皆需要「無究責文化」「持續學習」這些非技術條件
失敗無所不在#
規模一大,失敗就是統計上的必然。硬碟比過去可靠許多,但你硬碟越多、每天某顆故障的機率就越高。
與其耗盡力氣阻止失敗,不如假設失敗會發生,把心力花在優雅處理它。
Google 案例(第 10 章重提):每台伺服器都有獨立電源、硬碟用魔鬼氈固定 → 預期會壞、預期可快速更換。設計就為了「壞掉」優雅。
多少韌性才夠?#
不是越多越好,要回到跨功能需求(CFR):
- 回應時間/延遲:90 百分位 < 2 秒,每秒 200 並發
- 可用性(Availability):24/7?可容忍多少停機?
- 資料持久性(Durability):可遺失多少資料?保留多久?
這些寫成 SLO(service-level objective),定下日常品質的衡量。
優雅降級(Degrading Functionality)#
部分故障時,部分服務優雅降級 > 全站爆炸。例如電商頁面:
- 庫存服務掛了 → 仍允許下單,事後補帳
- 購物車服務掛了 → 顯示「Be Back Soon」圖示而非整頁壞掉
這通常不是純技術決策:要降級成什麼樣,需要產品方一起判斷哪些功能是核心、哪些可暫時拿掉。
穩定性模式(Stability Patterns)#
AdvertCorp 案例(作者親身經歷):團隊把舊系統慢慢絞殺進新系統,但有一天「蕪菁廣告」舊服務開始緩慢回應——不是徹底掛掉、是「龜速」。新系統的 HTTP connection pool 等待者沒設超時,threads 越積越多,整站 200 倍正常連線數,崩潰。
「慢」比「死」更難處理。In a distributed system, latency kills.
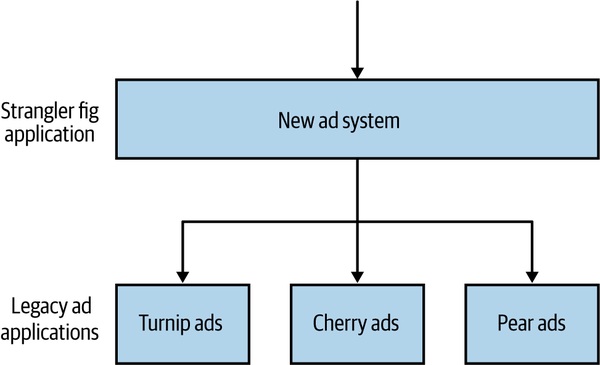
Figure 12.1:用 strangler fig 模式把舊系統呼叫導入新平台
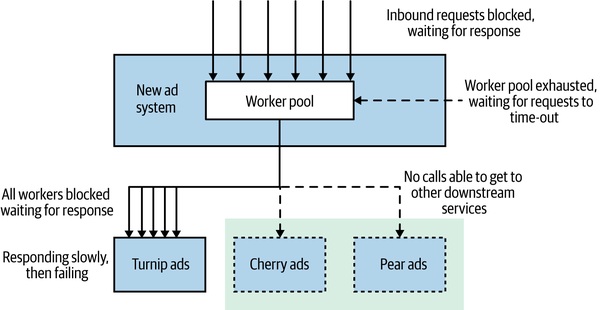
Figure 12.2:AdvertCorp 故障的成因簡圖
修復作法:時間限制(time-outs)、bulkheads、circuit breakers。下面逐一介紹。
時間限制(Time-Outs)#
- 對每個跨行程呼叫設預設 time-out
- 看下游正常回應時間(多半 ms 級)→ 設略高於正常範圍
- AdvertCorp 把 30 秒下游 timeout 改成 1 秒;用戶 30 秒早就重新整理 5 次了
- 也要對「整個操作」設total budget:500 ms 內必須完成 → 即使單一呼叫沒到 timeout,整體預算用光也要中止
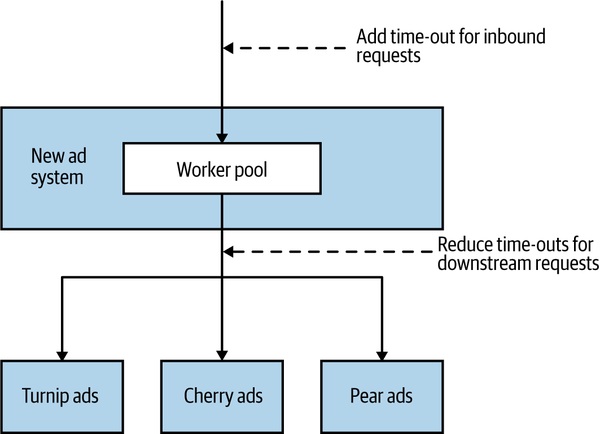
Figure 12.3:AdvertCorp 對 timeout 的調整
把每次 timeout 都記 log,定期檢查並調整。預設值要有,特例再調。
重試(Retries)#
- 短暫錯誤可重試(如 503 Service Unavailable、504 Gateway Time-out)
- 永久錯誤不該重試(如 404 Not Found)
- 重試前加延遲:別在下游已經過載時瘋狂打它
- 重試會推高 total budget——把它納入預算計算
隔艙(Bulkheads)#
來自 Michael Nygard《Release It!》。船艙的隔艙能在漏水時封閉、保住其他艙——軟體一樣。
AdvertCorp 真正的關鍵錯誤:所有下游服務共用同一個 connection pool。蕪菁服務拖累所有其他下游。
正解:每個下游服務一個獨立 connection pool。
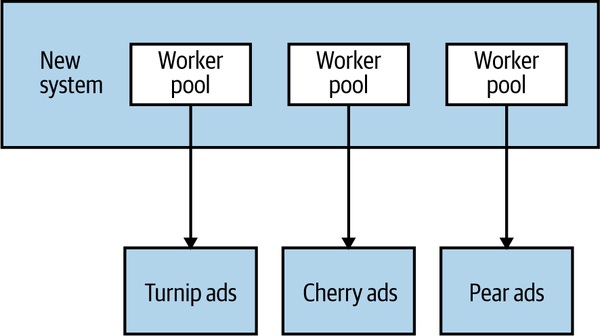
Figure 12.4:每個下游服務專屬 connection pool
切細微服務本身就是一種 bulkhead。也可在資源緊張時主動拒絕請求(load shedding)。
熔斷器(Circuit Breaker)#
也來自 Nygard《Release It!》——對所有同步下游呼叫,作者建議「強制」加上熔斷器。
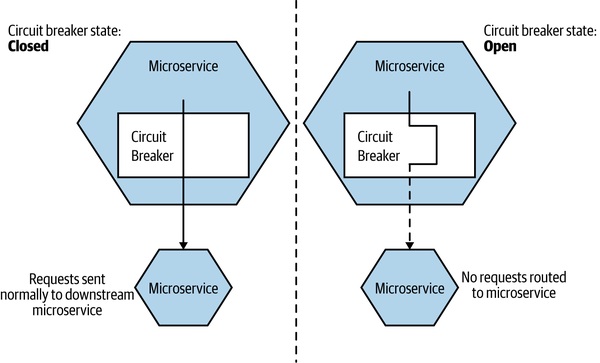
Figure 12.5:熔斷器運作示意
- 連續失敗 N 次後 → 熔斷器開(open):所有後續請求快速失敗,不再打下游
- 過一段時間 → 嘗試送少量請求探測 → 健康就重置
- 正常情境:fail fast > fail slow
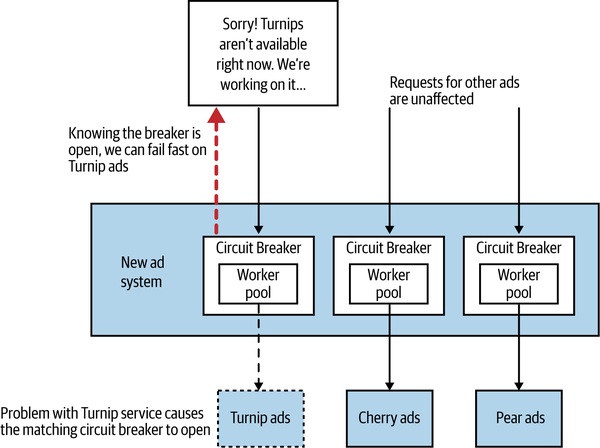
Figure 12.6:AdvertCorp 為每個舊系統加上熔斷器
熔斷器額外用法:
- 作為自動的 bulkhead 密封機制
- 維護時手動「開斷」上游熔斷器,避免請求打到下線中的服務
- 提前檢查熔斷器狀態,若已 open 可在操作開始前直接放棄
隔離(Isolation)#
- 邏輯隔離:服務不依賴對方就能跑(用 message broker 做 buffer)
- 實體隔離:別把所有服務塞同一台主機;別讓「邏輯獨立」的兩個服務共用同一座資料庫基礎設施
- 隔離有成本:更多基礎設施、更多管理工具——要做風險/成本權衡
冗餘(Redundancy)#
- 一個服務多個實例 → 一台掛還有別台
- 一個技術專家 → 至少兩個人懂
- AWS 不為單一 EC2 實例提供 SLA → 必須跨可用區(availability zone)部署
- 冗餘也順便給負載擴展(下章主題)
中介軟體(Middleware)#
訊息代理可以提供保證投遞、retry、timeout——專家寫的、用就對了。但回到 AdvertCorp:把同步請求改成佇列也救不了用戶——他們還是看不到蕪菁廣告。Middleware 不是萬能。
冪等性(Idempotency)#
重試的前提:操作要冪等。冪等性指的是「同一操作重複執行結果不變」。
不冪等的範例:
<credit>
<amount>100</amount>
<forAccount>1234</forAccount>
</credit>收到兩次就加 200 點。改成附帶來源訂單即可冪等:
<credit>
<amount>100</amount>
<forAccount>1234</forAccount>
<reason>
<forPurchase>4567</forPurchase>
</reason>
</credit>冪等是指底層業務操作冪等——log、metric 等附帶 side effect 仍會被記錄,這沒關係。
HTTP 規定 GET、PUT 應為冪等,前提是你的服務真的把它們實作為冪等。
分散風險#
- 一台機器多個服務 → 一台掛多服務掛
- 多台 VM 但同一台實體機 → 也是同樣風險
- 多台 VM 但 root partition 同一個 SAN → 仍是單點
- 多台跨資料中心、跨可用區、跨地區、甚至跨雲服務商
- 雲端 SLA 注意:99.95% 月度 ≠ 你不會掛掉,且廠商賠的多半是當月費用——自己準備備援方案
CAP 定理#
在分散式系統中,一旦發生網路分區(partition),一致性(Consistency)、可用性(Availability)、**分區容忍性(Partition Tolerance)**三者只能保留其二。
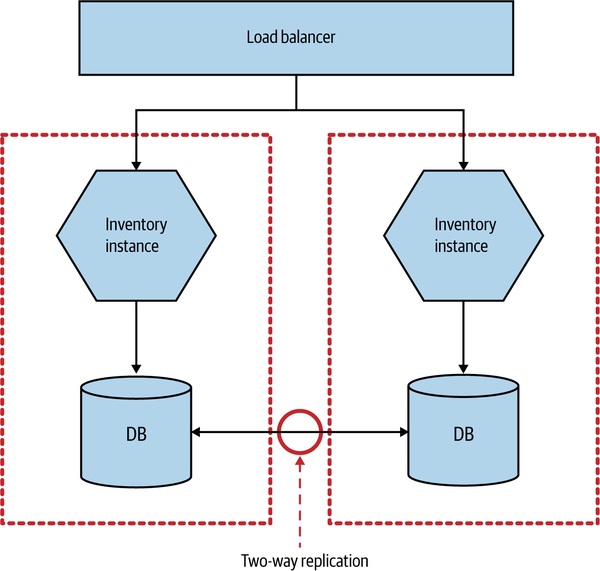
Figure 12.7:跨資料中心的多主資料庫複寫
AP 系統(犧牲一致性)#
- 分區發生時兩邊都繼續服務 → 資料可能短暫不同步 → 最終一致性(eventual consistency)
- 容易實作、容易擴展
- 適合寬鬆的場景:MusicCorp 的目錄、社群貼文計數
CP 系統(犧牲可用性)#
- 分區發生時無法保證一致 → 拒絕服務
- 多節點一致性極難自己手寫;用現成的(Consul、ZooKeeper、etcd)
- 「Friends don’t let friends write their own distributed consistent data store.」
CA 不存在#
CA 系統意味著「不能跑在網路上」——只能單一行程;不適用分散式系統。
不是全有全無#
- 整個系統不必全 AP 或全 CP
- 同一個微服務不同操作可以採不同策略:Points Balance 顯示餘額用 AP,扣點用 CP
- Cassandra 等資料庫允許每次讀寫設定不同的 quorum 強度
- 「打敗 CAP 定理」的人沒有打敗它,只是把不同能力切成不同 trade-off 而已
真實世界本來就不一致#
倉庫盤點 100 片 → 賣出 1 → 應該是 99 → 但有人摔破一片。系統說 99,實際 98。再 CP 的系統也救不了現實世界的不一致。
與其追求技術上的強一致,不如接受 AP + 後續對帳補償的設計,更貼近真實業務。
混沌工程(Chaos Engineering)#
Chaos Engineering(混沌工程)的標準定義:「在系統上做實驗,以建立信心,相信系統能在生產環境的混亂條件下運作。」
——Principles of Chaos Engineering
關鍵字「system」應理解為「人 + 流程 + 文化 + 軟體 + 基礎設施」整體,不只是隨便關幾台機器。
Game Day#
事先規劃、現場給人意外的災難演練。Google 早期就常做 DiRT(Disaster Recovery Test),甚至模擬大規模地震。Russ Miles 在《Learning Chaos Engineering》舉例:演練「Bob 不在」場景——Bob 被關小房間,結果團隊在演練中誤入 production 開始刪資料,Bob 不得不衝出來阻止。
Production 實驗#
Netflix 的 Simian Army:
- Chaos Monkey:隨機關掉機器
- Chaos Gorilla:關掉整個可用區
- Latency Monkey:模擬慢速網路
工具:Chaos Toolkit(開源)、Reliably、Gremlin。
跑混沌工程工具不會自動讓你有韌性——韌性來自團隊文化與設計觀念,工具只是輔助驗證。
究責(Blame)#
2016 年澳洲電信 Telstra 全國網路中斷數小時,COO 出事後幾小時內公開聲明:「是某位個人沒按程序、是令人尷尬的人為錯誤」。
後續 Telstra 又發生一連串故障,最後 COO 自己辭職。
這種公開究責創造恐懼文化:員工不敢主動回報錯誤 → 失去從失敗中學習的機會 → 同樣問題反覆發生。
John Allspaw《Blameless Post-Mortems and a Just Culture》是必讀文章。
韌性 = 持續質問系統弱點的文化。事件後的學習機會,要靠**安全感(psychological safety)**才能換取。
小結#
- 韌性四面向:強韌、反彈、優雅延伸、持續調適——微服務只在「強韌」幫得上忙
- 失敗無可避免;接受它,比抗拒它更划算
- 穩定性模式工具箱:時間限制、重試、bulkhead、circuit breaker、冗餘、隔離、冪等
- CAP 定理是工具,不是教條;可以在不同微服務、不同操作做不同 trade-off
- 混沌工程是文化的一部分,不是工具的勝利
- 不究責的事後檢討是建立學習型組織的關鍵