「我們把單體換成微服務,從此每次當機都像是一場謀殺懸案。」
——@honest_update(推特名言)
微服務架構讓「production 出狀況時,到底是哪個傢伙出包」變成一道偵探題。本章從監控(Monitoring)走到可觀測性(Observability),並整理對應的工具組與心態調整。
為什麼舊招不夠用#
從一服務一機 → 多服務多機#
- 單服務單機:基本三件事——主機指標(CPU、記憶體)、本機日誌(grep 即可)、外部健康檢查就夠用
Figure 10.1:單台主機跑單一微服務實例
- 單服務多機:要能聚合查看,又能切回看單機;登入每台撈 log 不可行;要在 LB 與服務本身都量回應時間
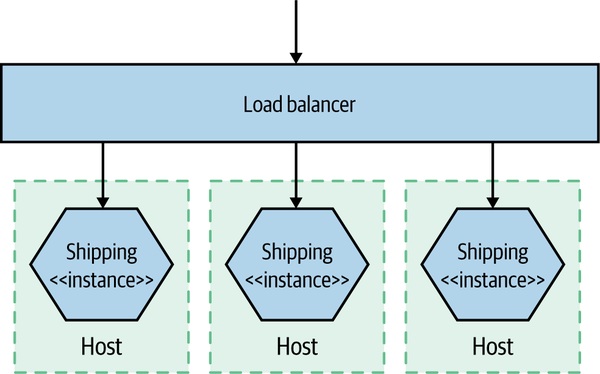
Figure 10.2:單一服務分散在多台主機,前面有負載平衡器
- 多服務多機:log 量爆炸、跨服務追問題像在大海撈針——這時候單純監控(被動看儀表板)已經跟不上
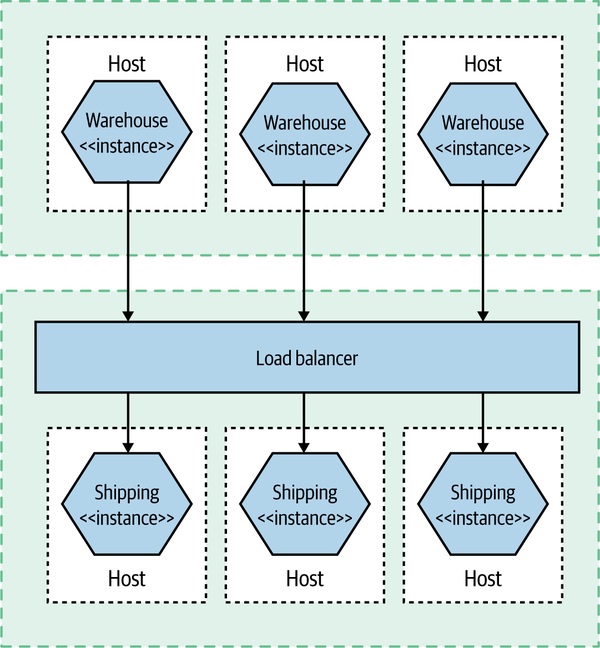
Figure 10.3:多個協作服務分散在多台主機
在 production 跑之前,你不會真正體會微服務架構帶來的痛、苦、與煎熬。
可觀測性 vs 監控#
| 概念 | 性質 |
|---|---|
| 監控(Monitoring) | 一種活動——我們做什麼 |
| 可觀測性(Observability) | 系統的一種屬性——能否從外部輸出推斷內部狀態 |
「可觀測性是你能從外部輸入理解系統行為的程度。日誌、事件、指標可以協助達成這個屬性,但重點是讓系統能被理解,而不是堆一堆工具。」
三支柱(?)的誤區#
業界流行說「可觀測性的三支柱:metrics、logs、distributed tracing」(New Relic 還加上 events 變 MELT)——作者反對這種化約:
- 把屬性化約到實作細節,是本末倒置
- 三類並非互斥(log 裡能放 metric,trace 可由 log 串起來)
- 看起來像供應商賣工具的話術——你需要三套不同的系統與協定
可以把這些東西統一視為「事件(events)」:每筆事件可投影成 trace、可索引、可聚合。當前工具鏈分開存放只是現實限制,不該限制思考。
可觀測性的建構積木#
- 日誌聚合(Log Aggregation)
- 指標聚合(Metrics Aggregation)
- 分散式追蹤(Distributed Tracing)
- 「我們做得好嗎?」(SLA、SLO、SLI、Error Budget)
- 告警(Alerting)
- 語意監控(Semantic Monitoring)
- 生產環境測試(Testing in Production)
日誌聚合(Log Aggregation)#
這是作者全書唯一不留情面的硬性建議:在開始建微服務之前,先把日誌聚合系統建好。
連這個都做不起來的組織,後面更難的東西基本上不用想。
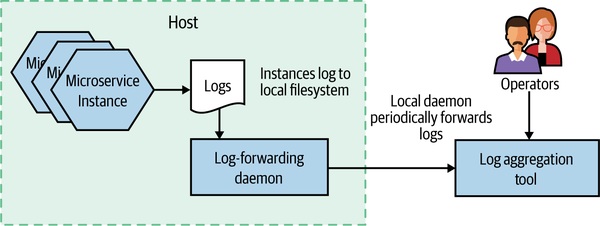
Figure 10.4:日誌聚合架構概覽
共通格式#
- 微服務本身就把日誌寫成標準格式(時間、服務名、log level 在固定位置)
- 避免在 log forwarding agent 裡轉格式——CPU 負荷重,作者親見因此引發的 production 問題
- 結構化 JSON 利於查詢,但要再用工具才能讓人讀
範例:
15-02-2020 16:00:58 Order INFO [abc-123] Customer 2112 has placed order 988827
15-02-2020 16:01:01 Payment INFO [abc-123] Payment $20.99 for 988827 by cust 2112關聯 ID(Correlation ID)#
有了日誌聚合,馬上把 correlation ID 加進來。從第一個請求進入系統就生成 ID,沿著呼叫鏈傳遞,並寫進每一行 log 的固定位置。早做容易、後補很痛。
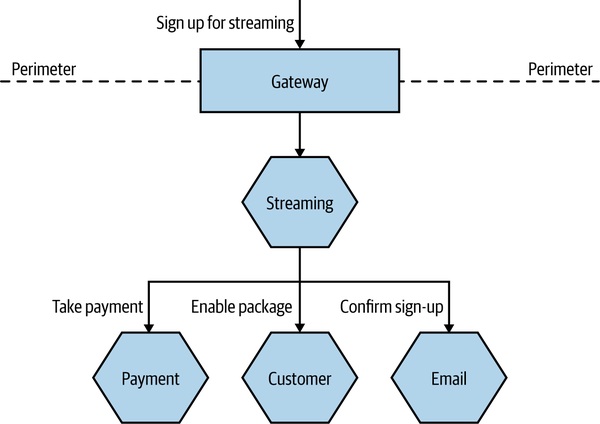
Figure 10.5:客戶註冊串流方案會觸發多個微服務
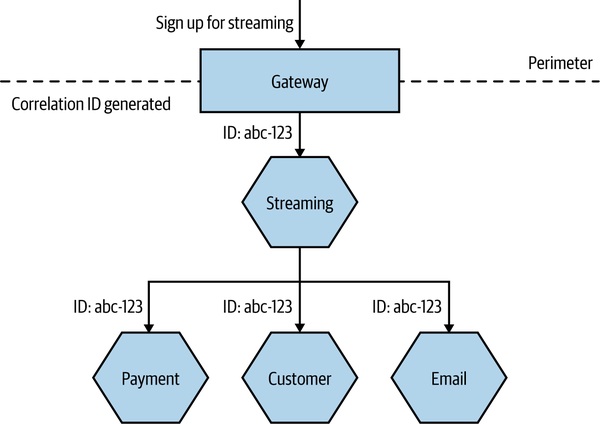
Figure 10.6:在 Gateway 產生 correlation ID 並沿鏈傳遞
時序的限制#
- 各機器時鐘有偏差(clock skew)
- 即使有 NTP(Network Time Protocol)也只能縮小不能消除偏差
- 真正想知道事件順序與精確延遲,用分散式追蹤,不要靠 log 的時戳
工具選擇#
- 開源:Fluentd(forwarding)+ Elasticsearch(儲存)+ Kibana(查詢)
- 商業:Humio、Datadog、Splunk
- 雲端:AWS CloudWatch、Azure Application Insights
Elasticsearch 是搜尋索引而非資料庫——把它當資料庫使用要小心遺失。Elastic 公司於 2021 年把授權從 Apache 2.0 改為 SSPL,引發爭議;AWS fork 出 OpenSearch 維持開源版本。
日誌的盲點#
- 量大 → 儲存與索引成本高(作者見過 Elasticsearch 叢集只能撐六週的 log)
- 含敏感資訊 → 存取要管制;log 本身可能成為攻擊目標
- 節儉策略:不存就不會被偷——刪掉沒必要的敏感欄位
指標聚合(Metrics Aggregation)#
- 趨勢觀察比單點數值更有意義(CPU 增加 20% 是不是問題?看歷史脈絡才能答)
- 容量規劃(capacity planning)依賴長期趨勢
- 不同解析度(10 秒/筆 vs 每小時平均);老資料聚合會丟失細節
- 注意 metadata:要能切到「整系統」「單一服務」「單一執行個體」
低基數 vs 高基數(Low vs High Cardinality)#
- 基數(cardinality):可被查詢的維度數
- 高基數例子:每筆指標附上 service name、customer ID、request ID、build number、product ID、OS、cloud provider……
- 時序資料庫對高基數通常很弱
Charity Majors(Honeycomb 創辦人):「Storage 一個 metric 很便宜;存一堆 tags 卻會把儲存引擎拖垮。」
Prometheus 官方文件就警告:不要把 user IDs、email 等高基數欄位當 label。
工具選擇:
- 簡單低基數:Prometheus(取代過去的 Graphite)
- 高基數可觀測性:Honeycomb、Lightstep——這也是它們同時主打分散式追蹤的原因
監控與可觀測性平台本身就是 production 系統。SolarWinds 的供應鏈攻擊案例提醒我們:監控工具也可能成為入侵媒介。
分散式追蹤(Distributed Tracing)#
把跨服務的呼叫關聯起來,呈現一次請求在系統中的旅程。
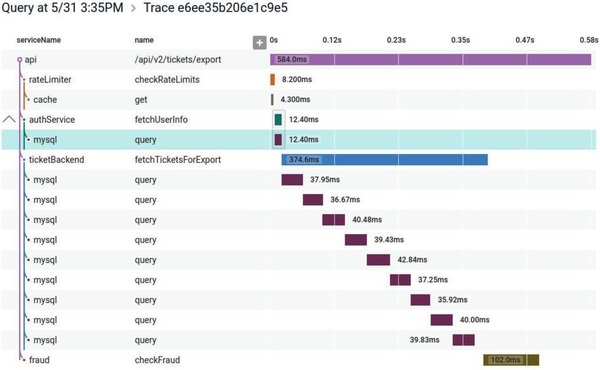
Figure 10.7:Honeycomb 中呈現的分散式追蹤
運作原理#
- Span:單一執行緒內的一段活動
- 多個 span 透過唯一 ID 關聯,在中央 collector 組成完整 trace
- OpenTracing API 中每個 span 含起訖時間、log、key-value tags(custom ID、build number 等)
取樣(Sampling)#
不可能全部都收,會把系統打爆。
- Google Dapper:激進隨機取樣(極小比例)
- Jaeger 預設:1/1000
- Honeycomb / Lightstep:動態取樣——錯誤類事件全收,重複的成功事件可只取 1/100
實作要點#
- 微服務要 instrument span 資訊
- 通常用本機 forwarding agent 中轉
- 中央 collector 負責組裝、儲存、查詢
- 強烈建議選支援 OpenTelemetry API 的工具——標準化、可移植
我們做得好嗎?SLA / SLO / SLI / Error Budget#
這些概念來自 Google 的站點可靠性工程(Site Reliability Engineering, SRE)。
| 名詞 | 含意 |
|---|---|
| SLA(Service-Level Agreement) | 服務水準協議——對使用者承諾的最低標準(沒達到時的後果) |
| SLO(Service-Level Objective) | 服務水準目標——團隊內部承諾達成的水準(通常高於 SLA) |
| SLI(Service-Level Indicator) | 服務水準指標——實際量測 SLO 是否達成的數據 |
| Error Budget | 由 SLO 推算出可接受的「壞掉時間」總額度 |
Error budget 重點是「給團隊嘗試新東西的呼吸空間」:
- 季內目標 99.9% → 一季可掛掉 2 小時 11 分
- 預算還剩很多 → 可大膽嘗試新語言、新架構
- 預算已花光 → 暫緩變動,先把穩定性顧好
告警(Alerting)#
不是所有問題都該叫醒人#
Google 在 Mountain View 園區大廳曾展示一台舊伺服器,硬碟用魔鬼氈黏著——「壞掉太多了,根本不裝螺絲」。硬碟壞掉是常態,不是緊急事件。
你必須學會分類:什麼問題該凌晨三點叫人?什麼可以等到上班再處理?
警報疲勞(Alert Fatigue)#
1979 年三哩島核電廠事故:操作員被海量警報淹沒,事後 Craig Faust 說「真希望能把警報盤丟掉,它根本沒給有用的資訊」。
2018-19 波音 737 Max 兩次空難:NTSB 調查指出多重警報同時觸發讓飛行員注意力被分散,無法在多個系統交互失效時優先處理關鍵問題。
軟體系統不是核電廠,但教訓相同:警報太多 = 沒有警報。
好警報的八個準則(EEMUA)#
來自 Engineering Equipment and Materials Users Association:
- Relevant(有價值)
- Unique(不重複另一個警報)
- Timely(即時)
- Prioritized(讓人知道先處理哪個)
- Understandable(資訊清楚)
- Diagnostic(明確指出問題)
- Advisory(建議怎麼處置)
- Focusing(聚焦最重要的議題)
語意監控(Semantic Monitoring)#
不再被動「等錯誤出現」,而是定義系統「正常運作該長什麼樣」。
例如 MusicCorp 的語意模型:
- 新客戶可成功註冊
- 尖峰時段每小時銷售額 ≥ $20,000
- 出貨速度維持在正常範圍
只要這些條件達成,系統就被視為「健康」——這比 CPU 95% 之類的低階指標更貼近商業現實。
要驗證模型有兩種做法:
- 真實使用者監控(Real User Monitoring)——觀察真實流量
- 合成交易(Synthetic Transactions)——稍後在 Testing in Production 中說明
生產環境測試#
「不在 production 測試,就像因為在家獨奏沒問題就不跟整個交響樂團排練。」
——Charity Majors
常見的「生產環境測試」型態:
| 類型 | 說明 |
|---|---|
| 合成交易(Synthetic Transactions) | 注入假使用者行為,預期已知輸出 |
| A/B 測試 | 同時部署兩個版本,比較指標 |
| 金絲雀發佈 | 一小群使用者先用新版 |
| 平行執行(Parallel Run) | 兩個版本同時跑,比較結果 |
| 冒煙測試(Smoke Test) | 部署完還沒釋出時驗證健康 |
| 混沌工程(Chaos Engineering) | 故意注入故障;Netflix Chaos Monkey 為知名範例(第 12 章詳述) |
作者朋友的故事:某電商不小心把測試跑到 production 訂單系統——直到一大批洗衣機真的送到公司大門才發現。合成交易要小心副作用:用假資料、假帳號、隔離環境。
標準化#
監控與可觀測性是少數值得全公司強制標準化的領域:
- log 寫成共同格式
- metric 命名統一(不要一個叫
ResponseTime、另一個叫RspTimeSecs) - 中央化把這些建構積木做好(通常由平台團隊負責,第 15 章詳述)
工具選型的原則#
- Democratic(人人可用):別讓工具難用到只有 SRE 老手能玩;開發者也要在 dev/test 環境就用得上
- Easy to Integrate(易整合):選支援 OpenTracing/OpenTelemetry 等開放標準的工具,方便日後換廠商
- Provide Context(提供脈絡):時序、相對、關聯、比例四種脈絡都應提供
- Real-Time(即時):以「秒」為單位,而非「分」「時」
- Suitable for Your Scale(規模合身):別硬套 Google 規模的工具
- Ben Sigelman(LightStep 創辦人):Google 每秒 50 億次 RPC,能 scale 到那個量級的工具必然功能精簡;你只有它千分之一的規模,你應該用功能更豐富的工具
機器裡的專家?#
近年 AI/ML 廠商不斷宣稱「自動異常偵測」——能取代運維專家。作者的看法:
自動化目前能告訴你「有東西看起來不對勁」,但要知道「不對勁是什麼意思、該採取什麼行動」,仍然需要人類專家。
工具應該支援專家做更好的判斷,不該替代專家。把預算花在好工具 + 好的人,而不是「神奇盒子」。
入門建議#
最小可行起步:
- 主機基本指標(CPU、I/O);確保能對應到實例與服務
- 各服務介面的回應時間
- 下游呼叫寫進 log
- 第一天就把 correlation ID 加進 log
- 重要業務步驟要 log 出來
- 至少要有一套 metric + log 聚合工具
- 分散式追蹤可以稍後上,但若雲端託管成本不高,越早越好
- 為關鍵業務建合成交易
小結#
- 微服務的監控不是把單體那套工具搬過來——心態要從監控轉向可觀測性
- 日誌聚合是先決條件;correlation ID 越早做越好
- 分散式追蹤對複雜系統的延遲與因果分析極關鍵
- 用 SLO/Error Budget 來治理穩定性與創新的平衡
- 警報設計:少而精,避免警報疲勞
- 接受一個現實:production 永遠會給你預料之外的問題——學會與未知共處
- 推薦延伸閱讀:Charity Majors 等《Observability Engineering》、Google《Site Reliability Engineering》與《Site Reliability Workbook》