本章合併原書 2nd Edition 第 7(Build)、8(Deployment)、9(Testing)三章內容。三者相互交織:建置產出可部署的 artifact,部署需驗證機制把關,測試貫穿整條交付管線。
持續整合(CI)#
CI 的核心目標是讓所有人頻繁同步彼此的變更。每一次提交都會被偵測、檢出、編譯,並跑通過驗證流程(如測試)。最終產出可供後續驗證的部署成品(artifact)。
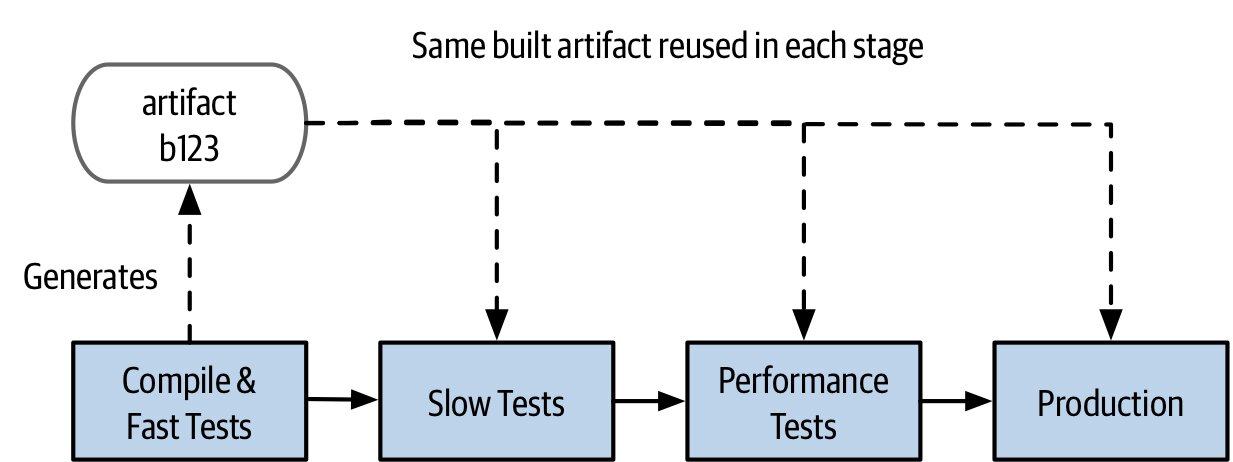
Figure 6.1:以建置流水線呈現 Catalog 服務的簡單發佈流程
同一份 artifact 從頭用到尾:建一次、用一次、上線同一個。避免「測試版」與「部署版」不同所產生的相容性風險。
你真的在做 CI 嗎?#
Jez Humble 的三個自我檢查問題:
- 每天至少把程式碼合進主幹一次嗎?
- 是否有測試套件驗證你的變更?
- 建置失敗時,修復是否變成團隊第一優先?
只是「裝了 Jenkins/CircleCI/Travis」並不等於在做 CI。沒有上述三條原則,工具再花俏都白搭。
分支策略#
- 特性分支(Feature Branching) → 延後整合 → 合併越晚越痛
- 主幹開發(Trunk-Based Development) → 大家都進主幹,未完成功能用 feature flag 隱藏
2016 與 2019 年 State of DevOps Report 都顯示:分支壽命短於 1 天、活躍分支不超過 3 個的團隊,交付表現顯著較佳。
開源專案(GitFlow)的分支策略不適合直接套用到日常閉源開發。開源專案以大量陌生貢獻者為前提,與一般小團隊有本質差異。
建置流水線(Build Pipeline)與持續交付(CD)#
Pipeline 結構#
把建置流程切成多個階段,例如:快測 → 慢測 → 效能測 → 部署。前段失敗就不必跑後段;通過階段越多,信心越高。
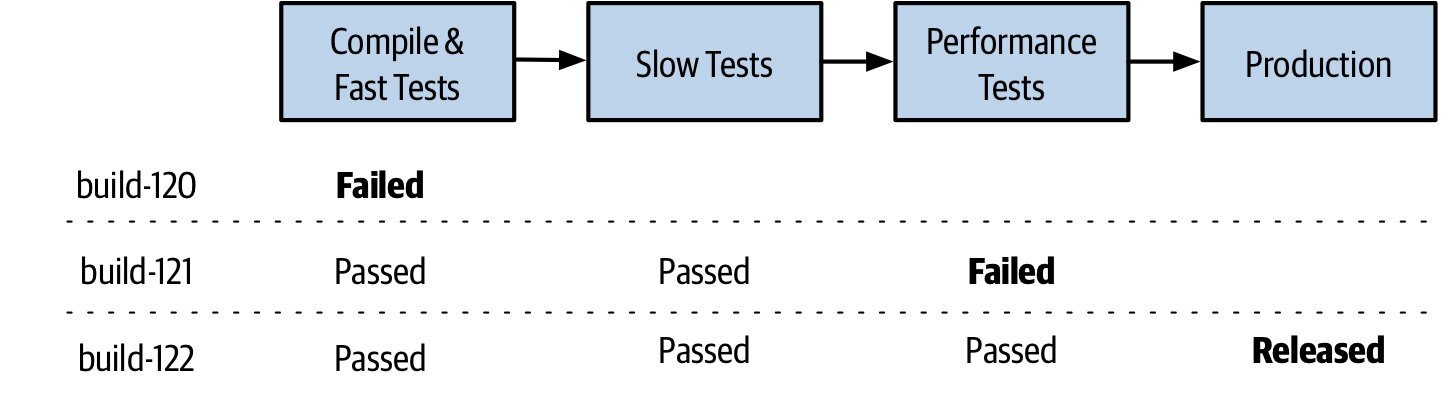
Figure 6.2:Catalog 微服務必須通過流水線每一階段才能部署
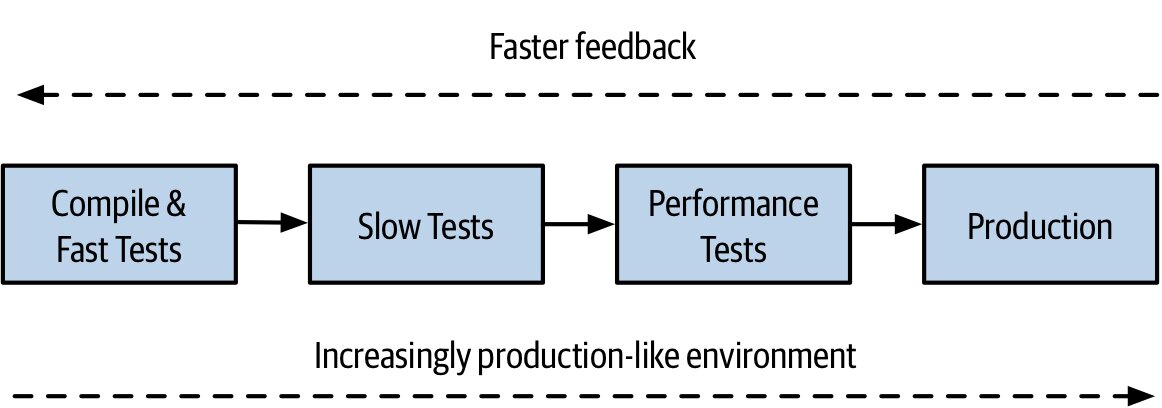
Figure 6.3:在快速回饋與類正式環境之間取得流水線的平衡
CD vs Continuous Deployment#
| 概念 | 說明 |
|---|---|
| 持續交付(Continuous Delivery) | 每次提交都被視為候選版本,能否上線由人決定 |
| 持續部署(Continuous Deployment) | 通過自動驗證的版本自動上線,無需人工干預 |
持續部署是持續交付的子集,不是每個團隊都需要——但 CD 必然要求你不斷壓縮人為瓶頸。
Artifact 規則#
- 建一次就好:管線早期建好,後續所有階段重用
- 驗證的 artifact = 部署的 artifact
- 環境設定要外部化:不同環境的差異透過設定注入,而非重建 artifact
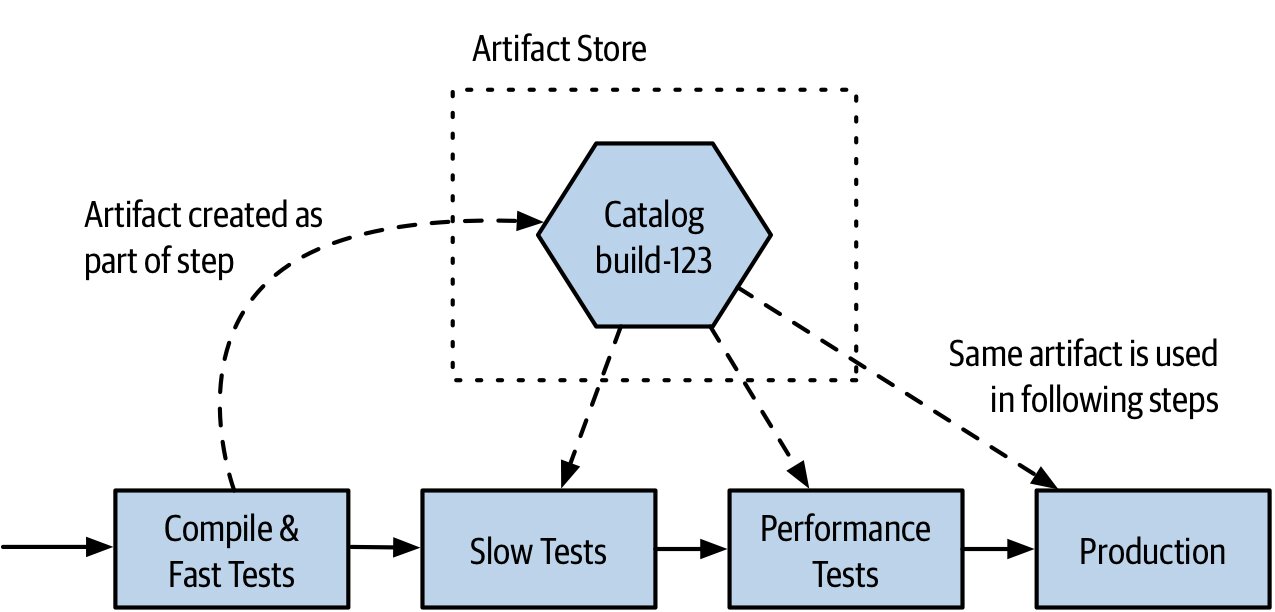
Figure 6.4:同一份 artifact 部署到每一個環境
原始碼與微服務的對應#
一個大 Repo + 一個大 Build#
最簡單但問題最多:
- 改一行程式所有服務都要重編
- 不知道該部署哪些服務 → 常退化成「全部一起部署」
- 任何一個服務壞掉就整條 build 紅
- 早期專案、單一團隊還能容忍;長期幾乎都會痛
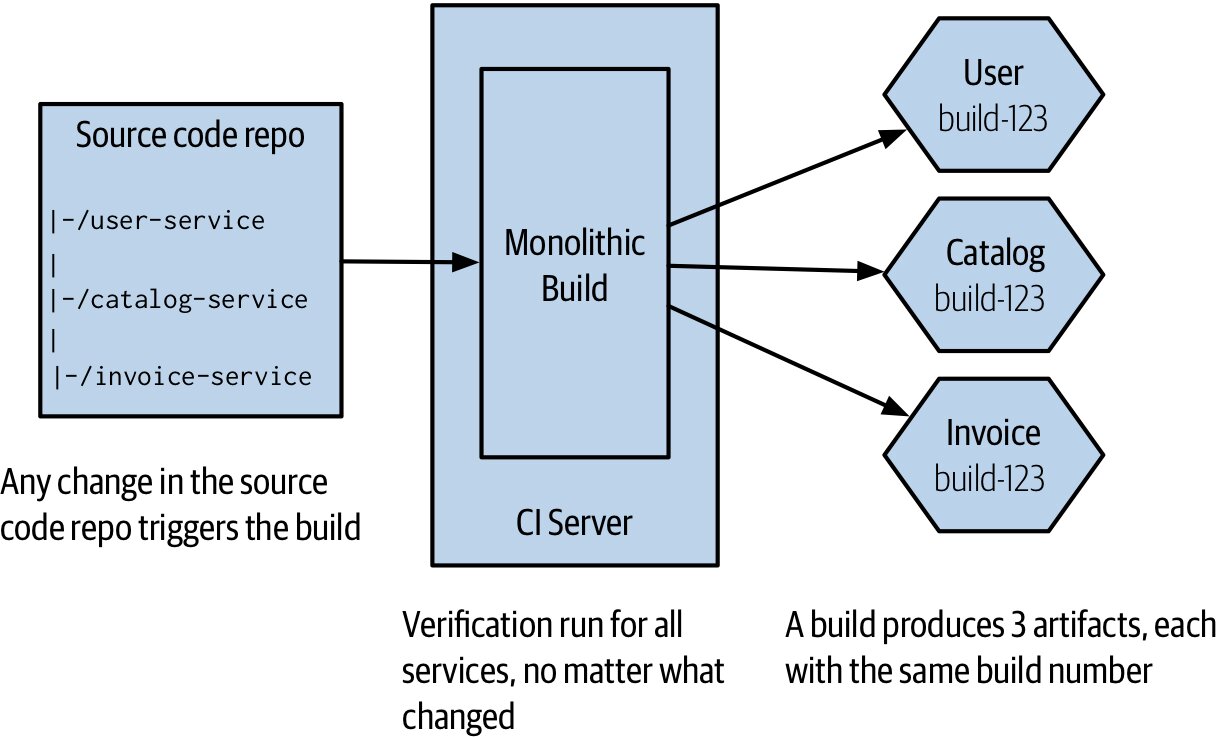
Figure 6.5:所有微服務共用單一原始碼倉庫與 CI 建置
Multi-Repo(一個微服務一個 repo)#
- 變更與 build 對應清楚
- 所有權邊界乾淨,可逐 repo 設定權限
- 跨 repo 變更需多次 commit,且 git 無法跨 repo 原子提交
- 共享程式碼透過 versioned library 引用
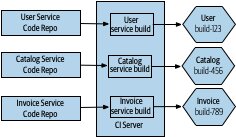
Figure 6.6:每個微服務的原始碼存放在獨立的 repo
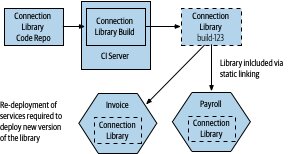
Figure 6.7:跨 repo 重用程式碼
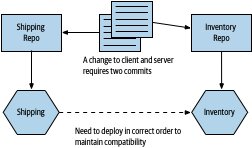
Figure 6.8:跨 repo 邊界的變更需要多次 commit
若你經常需要跨多個微服務修改,這是訊號:邊界可能切錯了,或許該合併某些服務。
Monorepo#
- 單一 repo 容納多個服務的程式碼
- 跨服務的修改可以原子提交
- 細粒度的程式碼重用更方便(只依賴單一檔案)
- Google、Microsoft、Facebook、Twitter、Uber 採用——但他們同時投入巨量工具開發
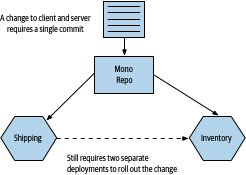
Figure 6.9:在 monorepo 中以單次 commit 同時修改兩個微服務
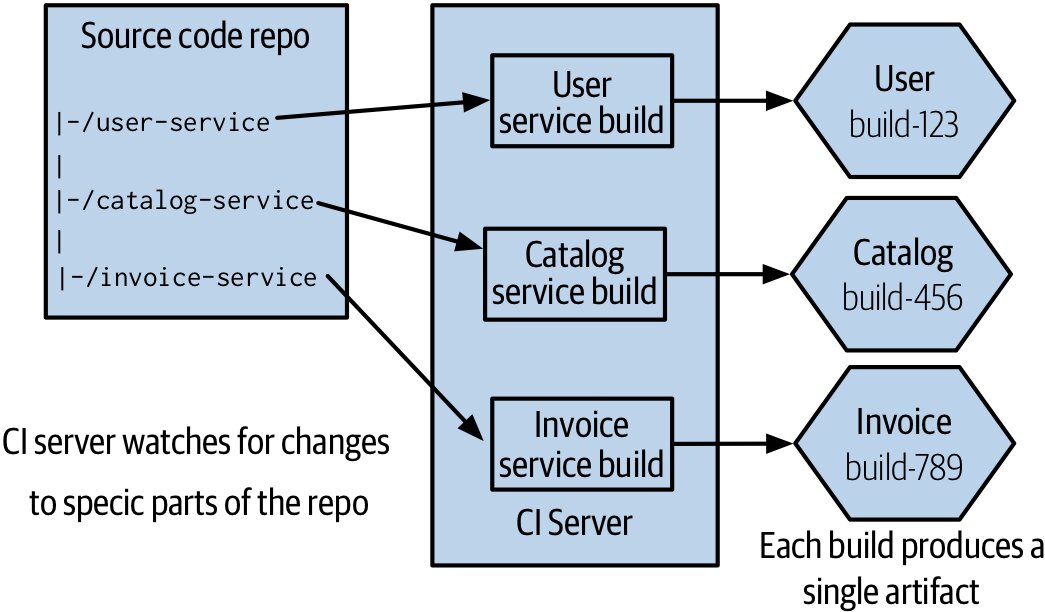
Figure 6.10:單一原始碼 repo,子目錄對應到獨立的建置
原子提交不等於原子部署!跨服務同時 deploy 仍然違反獨立可部署性原則。
挑戰:
- 大型 monorepo 需要圖式 build 工具(Bazel)
- 大型 monorepo 需要細粒度所有權控制(GitHub CODEOWNERS)
- Google 的 monorepo 有專屬 source control(Piper)、Microsoft 為 Windows 開發 VFS for Git——這些不是一般組織能負擔的
**「per-team monorepo」**是中間路線——每個團隊自己一個 monorepo,享受多數好處又避開超大規模問題。
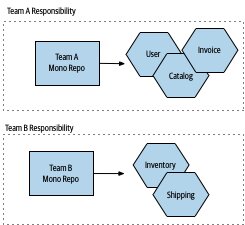
Figure 6.11:每個團隊各擁一個 monorepo 的變體
作者偏好#
- 小團隊:兩種都行
- 中大型:偏好 multi-repo
- 主要顧慮:monorepo 鼓勵跨服務變更、所有權邊界模糊、需要新工具鏈
從邏輯到實體:部署拓樸#
多執行個體與資料庫#
- 一個邏輯微服務 → 多個執行個體(負載平衡 + 容錯)
- 跨可用區(Availability Zone)部署是雲端標配——AWS、Azure、Google 都不為單一機器或單一可用區提供 SLA
- 同一服務的多執行個體可以共用資料庫(仍屬同一邏輯服務);違反「不共享資料庫」原則的是跨服務共享
- 雲端託管資料庫服務(如 AWS RDS)讓「每個微服務一個專屬資料庫實例」變得可行
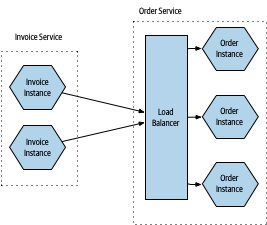
Figure 7.2:以負載平衡器將請求分配到 Order 微服務的多個執行個體
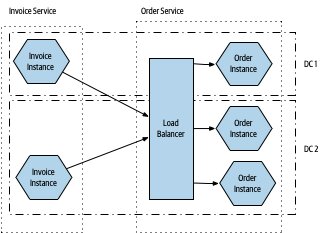
Figure 7.3:跨多個資料中心分散執行個體
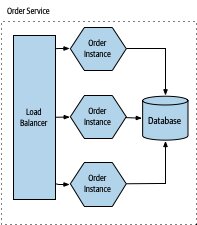
Figure 7.4:同一微服務的多個執行個體可共用資料庫
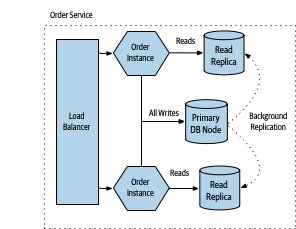
Figure 7.5:以唯讀副本(Read Replica)分散負載
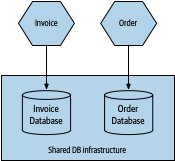
Figure 7.6:同一份實體資料庫基礎設施承載兩個邏輯隔離的資料庫
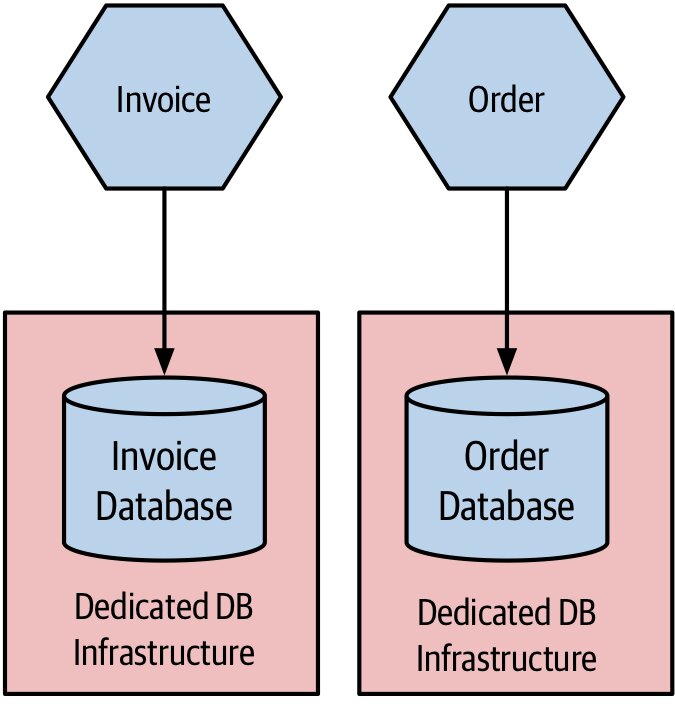
Figure 7.7:每個微服務使用各自專屬的資料庫基礎設施
環境#
- 每個環境用途不同:本機 → CI → 預發 → 正式
- 越靠近開發者,環境越輕量、回饋越快
- 越靠近正式環境,越要貼近 production
- 同一份 artifact 在不同環境可能拓樸不同(執行個體數、設定值),但artifact 本身不變
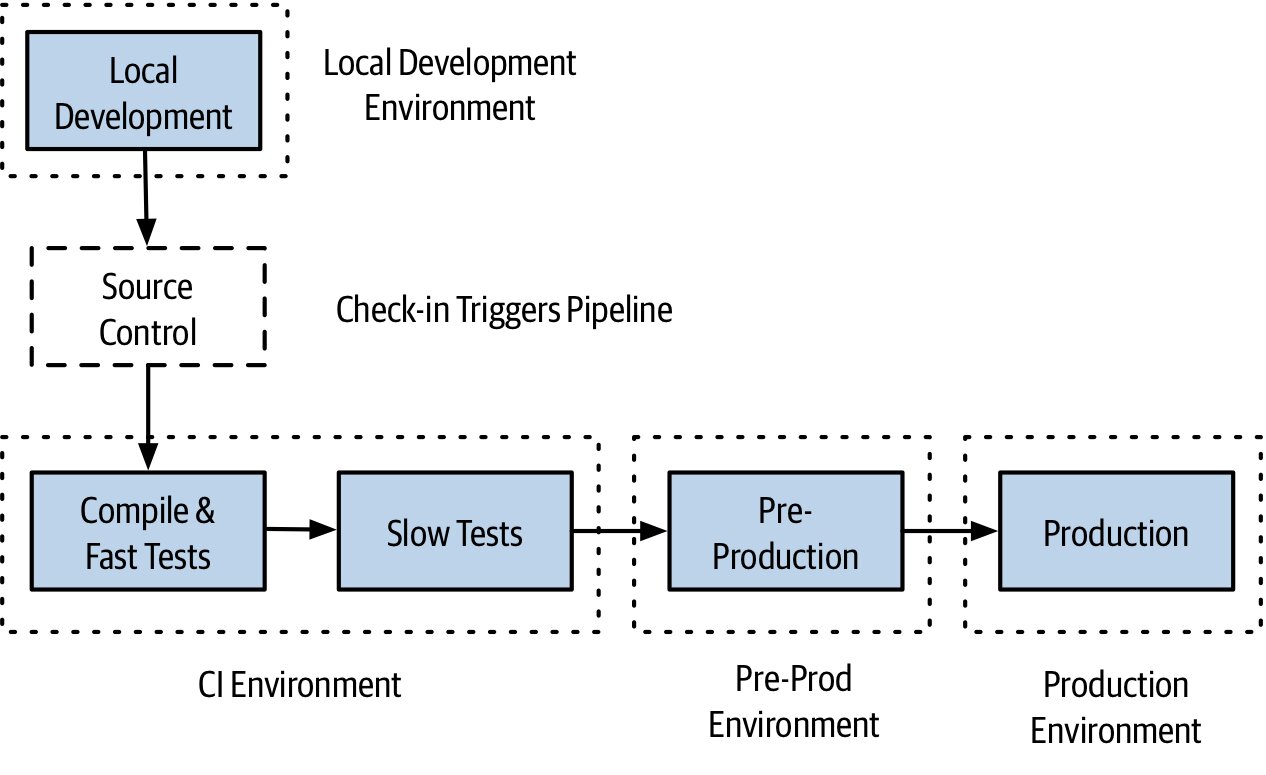
Figure 7.8:流水線不同階段使用不同的環境
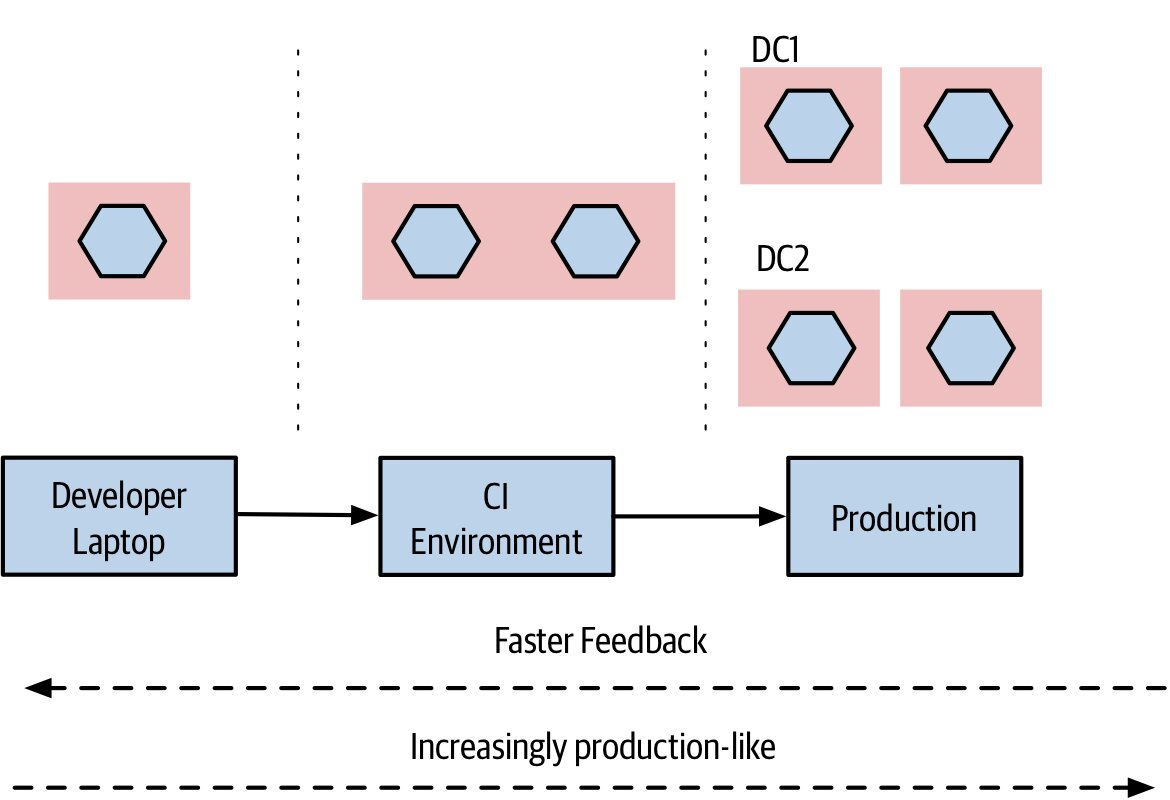
Figure 7.9:微服務在不同環境中的部署方式可以有所差異
部署的五大原則#
- 隔離執行(Isolated Execution):每個微服務有獨立資源,不互相干擾
- 聚焦自動化(Focus On Automation):手動流程隨服務數量上升而崩潰
- 基礎設施即程式碼(Infrastructure As Code):基礎設施定義可版本控制、可重現
- 零停機部署(Zero-Downtime Deployment):上版本不影響使用者
- 期望狀態管理(Desired State Management):平台自動維持指定的執行個體數與狀態
隔離執行#
「一台機器跑多個微服務」雖然 host 管理單純,但:
- 監控混亂(誰吃了 CPU?)
- 副作用難避免(Gilt 案例:單一服務暴衝拖垮其他服務)
- 部署相互干擾、依賴衝突
- 損害獨立可部署性
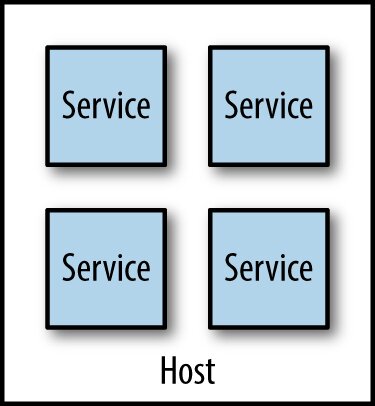
Figure 7.10:每台主機跑多個微服務
Figure 7.11:每台主機只跑一個微服務
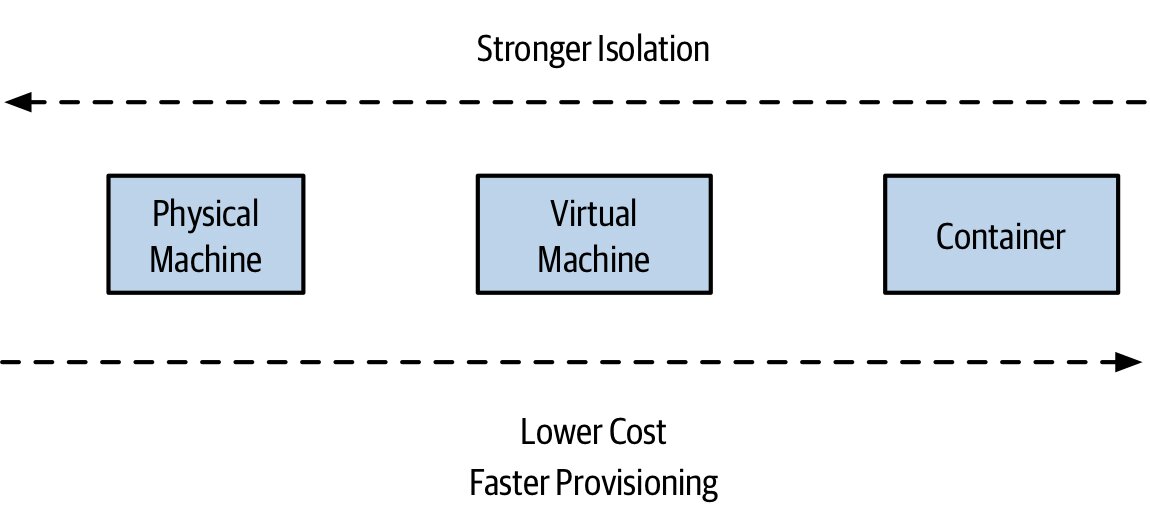
Figure 7.12:實體機、VM、容器在隔離模式上的取捨
容器讓「一服務一隔離環境」變得便宜。
自動化的力量#
- RealEstate.com.au:花了三個月把工具鏈做好,後續才能 18 個月內部署 60–70 個服務
- Gilt:2014 年達 450 個微服務,平均每位開發者管 3 個微服務
Infrastructure as Code#
- Puppet、Chef、Ansible、Terraform、Pulumi
- 環境可被版本化、被測試、可重建
- 法律與稽核情境特別有用——能精準復原某時點的環境
零停機部署#
Sarah Wells(Financial Times):零停機部署是交付速度提升最大的單一因素。發版不再需要熬夜、週末加班,疲勞越少 → 出錯越少。
實作方式:滾動升級(rolling upgrade)、藍綠部署。
期望狀態管理#
- 你只描述「我想要 4 個 instance、每個 2GB 記憶體」
- 平台負責 launch、recover、re-balance
- Kubernetes、AWS Auto Scaling Group、Nomad
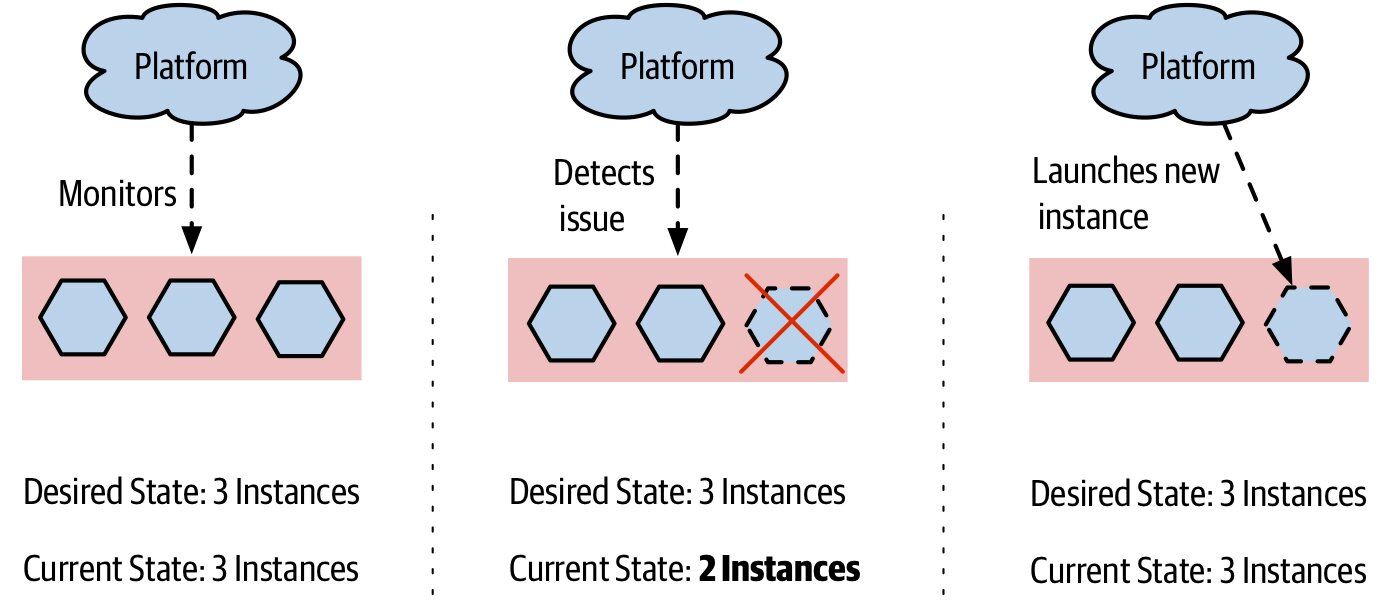
Figure 7.13:平台維持期望狀態,執行個體死掉時自動補上新的
作者親身糗事:在 AWS 下班前手動關掉 EC2,但忘了 auto scaling group 設了最小數量——結果關一台跳一台,整整玩了 15 分鐘 whack-a-mole,且依小時計費。不可忽視自動化系統的存在。
GitOps#
把 Infrastructure as Code 與 Desired State Management 合在一起:期望狀態存進 git,工具(如 Flux)自動把 git 內容套用到叢集。Kubernetes 生態的延伸。
部署選項對照#
| 選項 | 隔離 | 自動化 | 一服一機嗎? |
|---|---|---|---|
| 實體機 | 最佳 | 最差 | 浪費資源 |
| 虛擬機(VM) | 佳 | 視平台 | 可 |
| 容器 | 良好 | 強 | 預設模式 |
| 應用容器(Tomcat、IIS) | 弱 | 受限 | 多服務一容器 |
| PaaS(Heroku、App Engine) | 由平台處理 | 由平台處理 | 抽象掉 |
| FaaS(Lambda、Azure Functions) | 由平台處理 | 由平台處理 | 函數為單位 |
實體機#
幾乎已被淘汰。資源浪費、難以隔離、難以自動化。
虛擬機#
- 隔離強,但 hypervisor 本身吃資源
- 切越細邊際效益越低(Type 2 虛擬化)
- 雲端託管 VM(AWS EC2、Azure VM)+ Auto Scaling Group → 可實作期望狀態管理
- Netflix 是最有名的 EC2 大規模微服務案例
容器#
Linux 容器共用核心,沒有 hypervisor 開銷;啟動秒級、密度高、輕量
Windows 容器較重(Nano Server > 1GB),但支援 process isolation 與 Hyper-V isolation 兩種模式
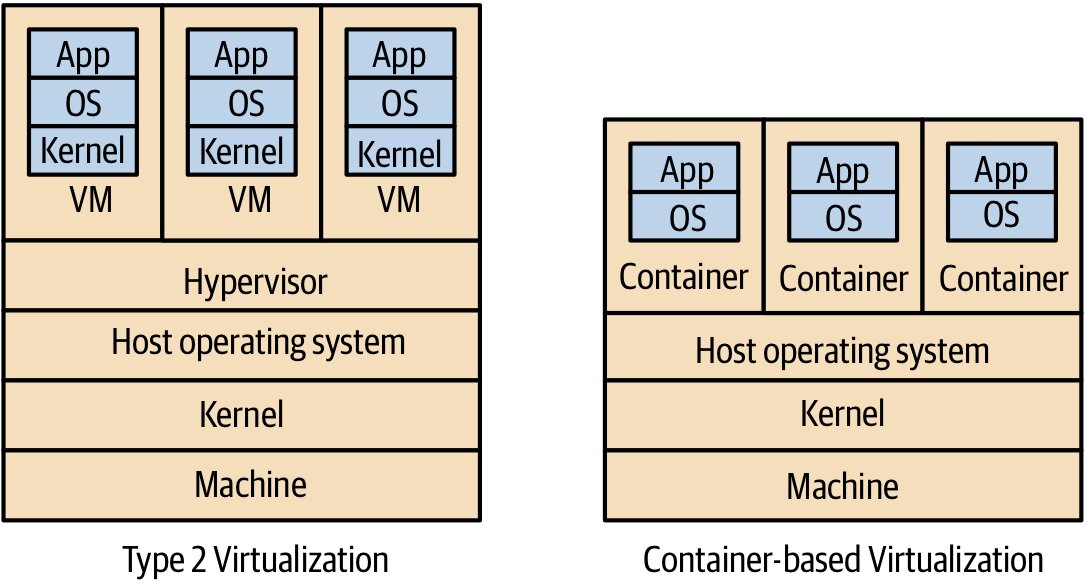
Figure 7.14:標準 Type 2 虛擬化與輕量級容器的比較
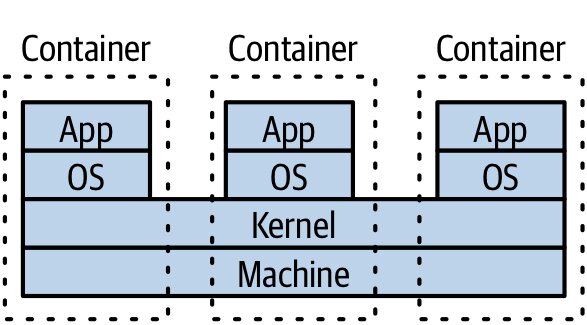
Figure 7.15:同一台機器上的容器通常共用相同核心
優點:
- 啟動快、密度高、隔離夠用
- Docker image 抽象掉內部技術,部署層工具一致
- 開發機可以跑跟生產相同的容器映像
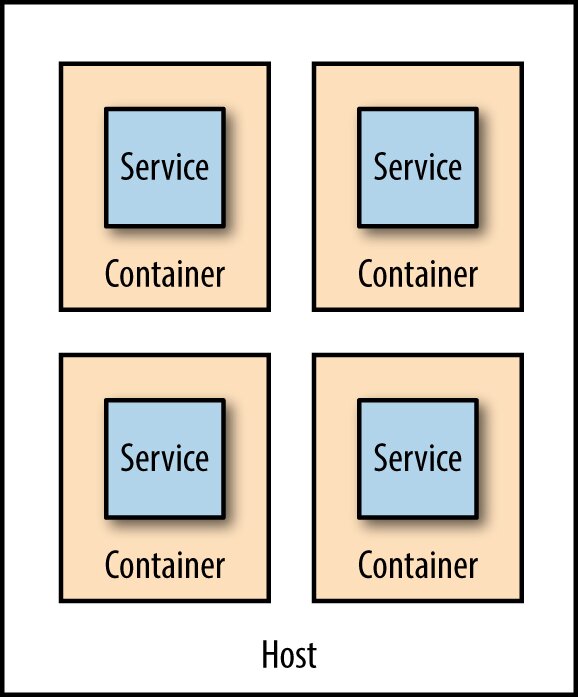
Figure 7.16:服務各自跑在獨立容器中
注意:
- 容器隔離不如 VM 嚴格——若需運行不可信第三方程式碼,要再評估
- 「容器跨多機管理」必須搭配編排器(Kubernetes)
應用容器(Application Container)#
- 多個應用塞進同一個 Tomcat / IIS / Weblogic
- 共享 JVM 等 runtime 看似省資源
- 但限制技術選擇、生命週期管理難、缺乏隔離
- 作者建議避免
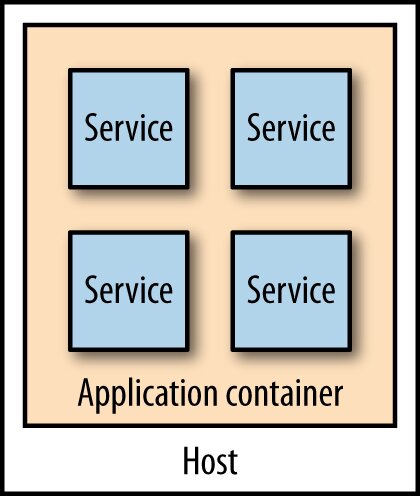
Figure 7.17:在同一個應用容器中運行多個微服務
PaaS#
- Heroku、Google App Engine、AWS Beanstalk、Netlify
- 平台幫你處理絕大多數運維瑣事
- 缺點:限制較多;越「聰明」的 PaaS 越容易在邊緣案例出錯
FaaS#
AWS Lambda 2014 開啟 FaaS 時代。函式平時休眠,被觸發(HTTP、訊息、檔案到達)時執行,結束即關閉。沒被執行就沒費用。
優點:
- 自動高可用、自動擴縮容
- 大幅減少運維負擔
- 對低/不可預測流量極友善
限制:
- 語言選擇受限
- 資源(CPU、IO)只能透過記憶體間接調控
- 執行時間上限(AWS Lambda 15 分鐘、GCP 9 分鐘)
- 無狀態(除非搭配資料庫或 Azure Durable Functions)
- 冷啟動(JVM、.NET 較嚴重;Go、Python、Node 較不顯著)
- 動態擴展可能反而打爆下游(Bustle 的 Redis 案例)
FaaS 與微服務的對應#
- 一服務一函式:保留微服務作為部署單位,內部需做請求分派
- 一聚合一函式:把單一服務拆成數個函式,但對外仍以單一服務呈現
- 再細就要小心:把每個狀態轉換拆成獨立函式會碰到 Saga 等級的一致性問題,得不償失
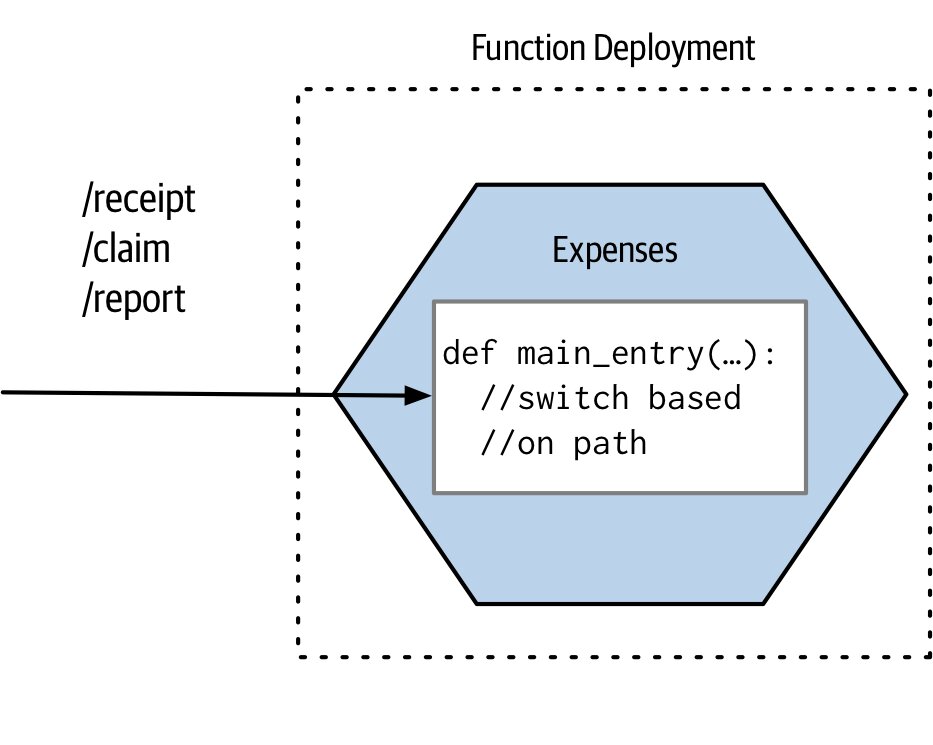
Figure 7.18:Expenses 服務以單一函式實作
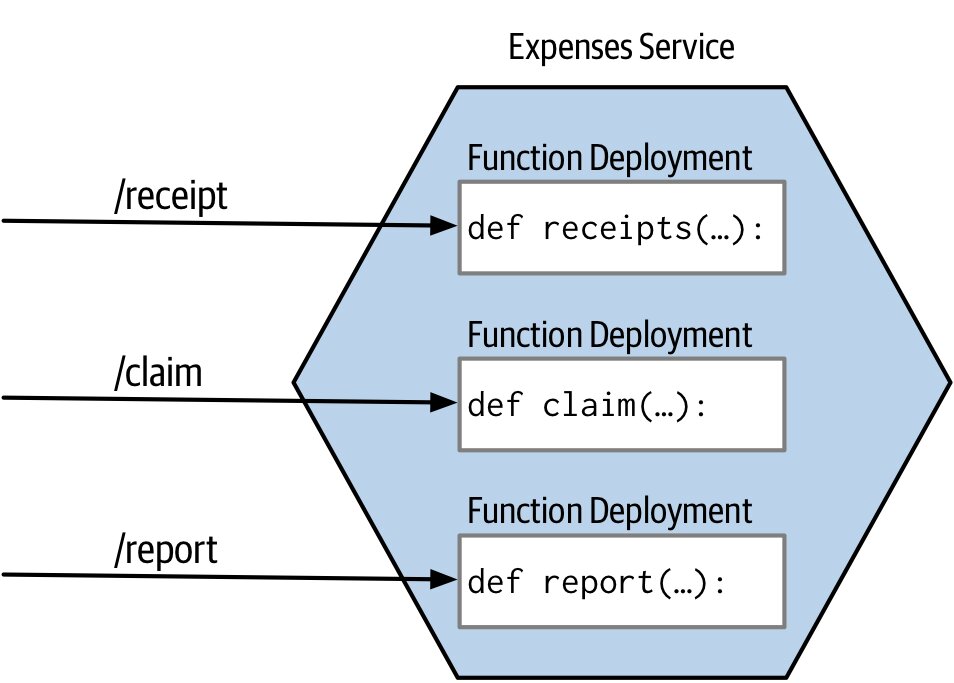
Figure 7.19:Expenses 服務拆成多個函式,每個處理一個 aggregate
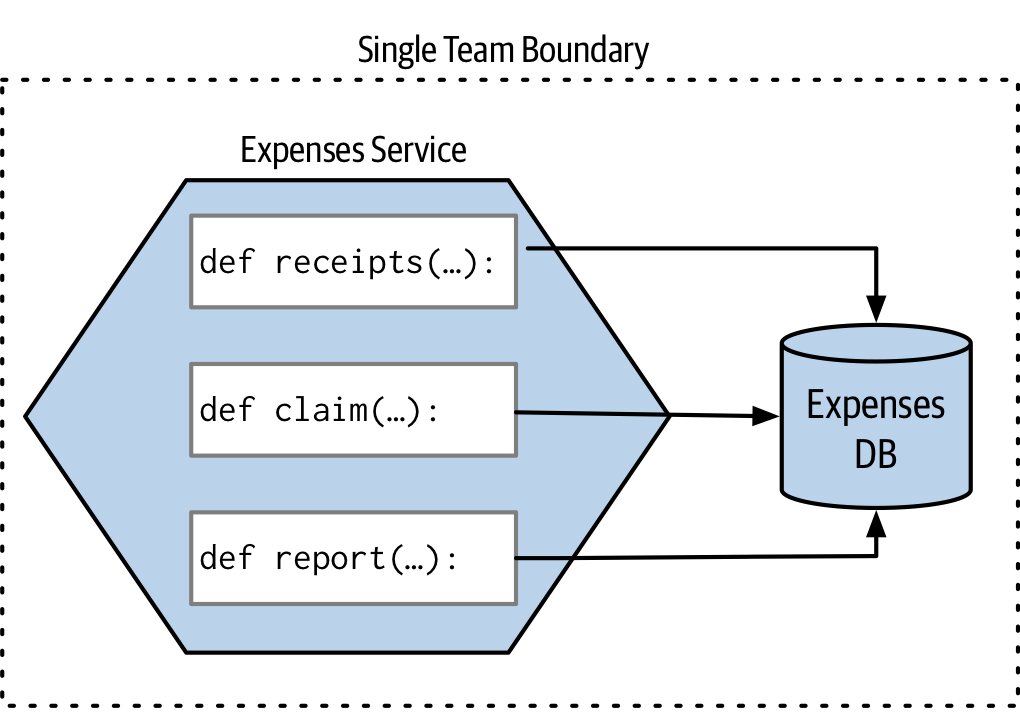
Figure 7.20:不同函式共用同一資料庫,邏輯上仍屬同一微服務
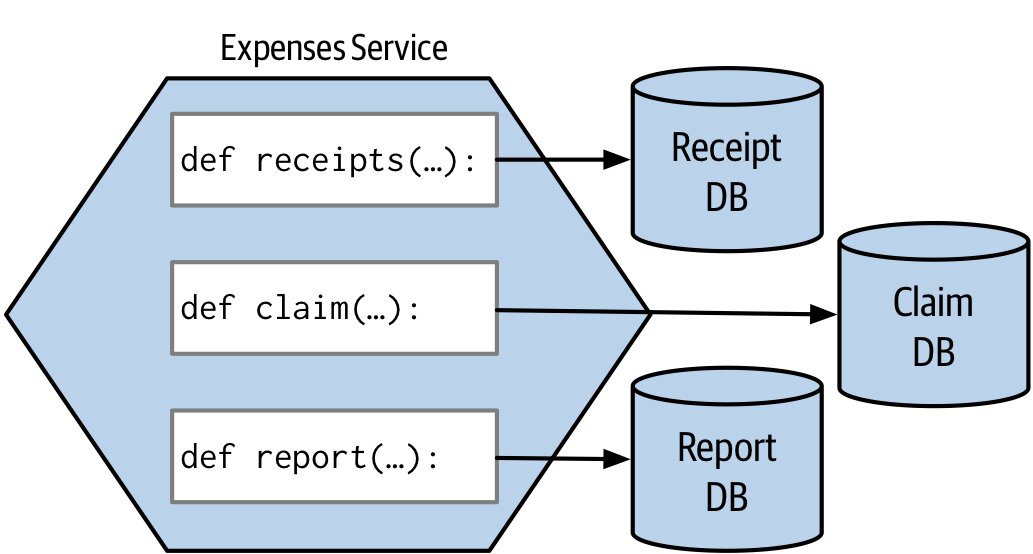
Figure 7.21:每個函式各自擁有獨立的資料庫
該選哪一種?#
Sam 的部署選擇三條規則:
- 沒壞就別修(If it ain’t broke, don’t fix it)
- 盡可能把責任交給平台:能用 PaaS / FaaS 就用,把時間留給產品
- 容器化是 isolation 與成本之間的好折衷——多數人最終會走向 Kubernetes
別陷入「Kubernetes 或一無所有」的迷思。
Kubernetes 與容器編排#
為什麼需要編排器?#
容器跨多台機器運行時,需要工具決定:
- 哪個容器跑在哪台機器
- 失敗時自動補位
- 期望狀態維持
Kubernetes 在這場競賽中勝出(其他選手:Mesos、Nomad、Docker Swarm Mode、AWS ECS)。
核心概念精簡版#
| 概念 | 說明 |
|---|---|
| 叢集(Cluster) | 一組節點 + 控制面(Master) |
| 節點(Node) | 跑工作負載的機器 |
| Pod | 部署的最小單位;可包含 1+ 容器(通常 1 個,sidecar 例外) |
| Service | 邏輯端點,把流量路由給對應的 Pod |
| ReplicaSet | 期望狀態:要幾個 pod、什麼資源 |
| Deployment | 套用變更、滾動升級、回滾 |
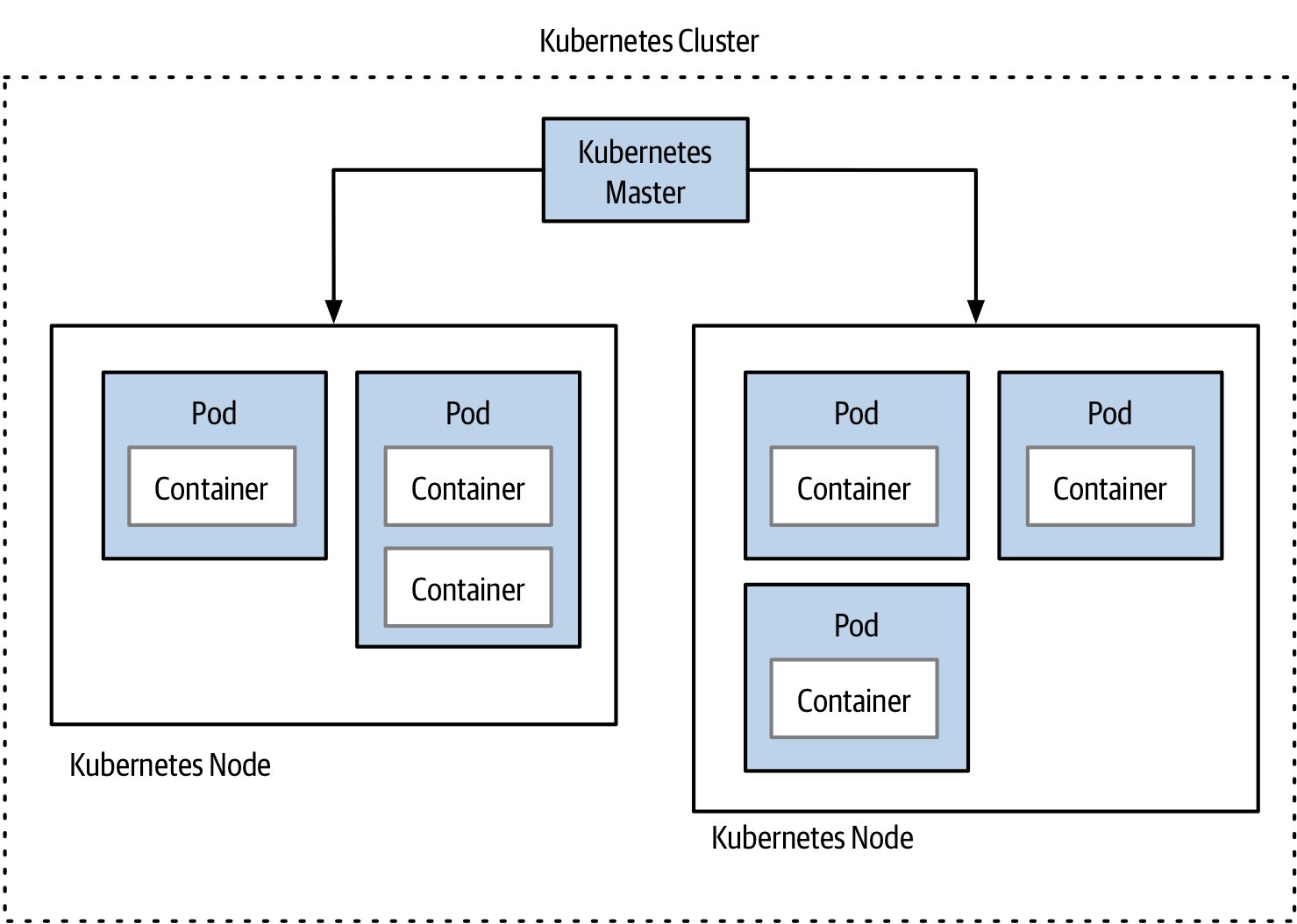
Figure 7.22:Kubernetes 拓樸的簡要概覽
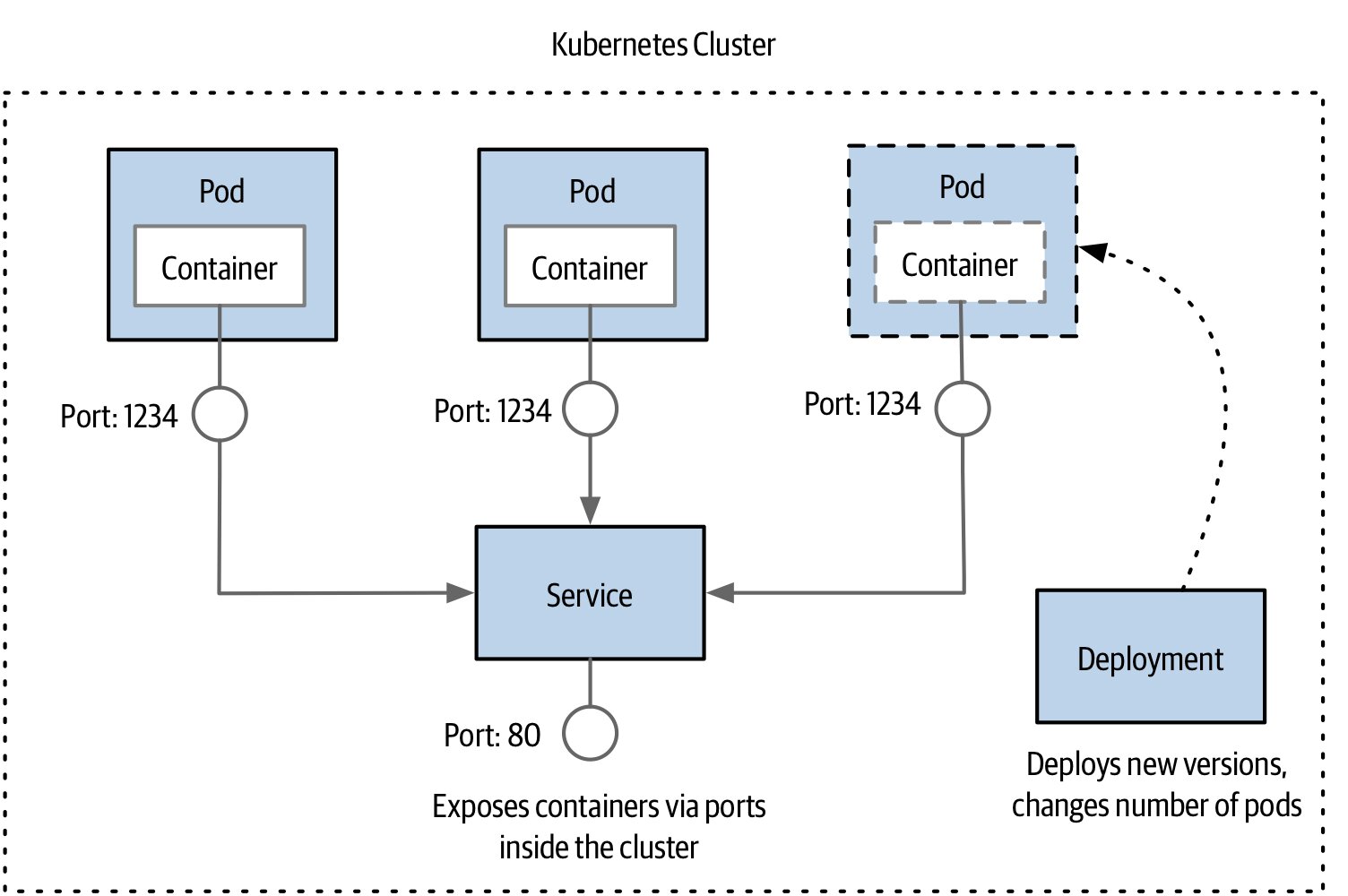
Figure 7.23:Pod、Service 與 Deployment 之間的協作
Kubernetes 的「Service」與微服務的 service 完全是兩碼事——Kubernetes 中你不直接部署 service,而是部署 pod 對應到 service。命名容易混淆。
多租戶與聯邦#
- 單叢集池化資源效率最高,但 Kubernetes 多租戶能力有限
- 解法 1:採用 OpenShift 等加值平台
- 解法 2:聯邦多叢集(Federation)——但跨叢集調度成本高
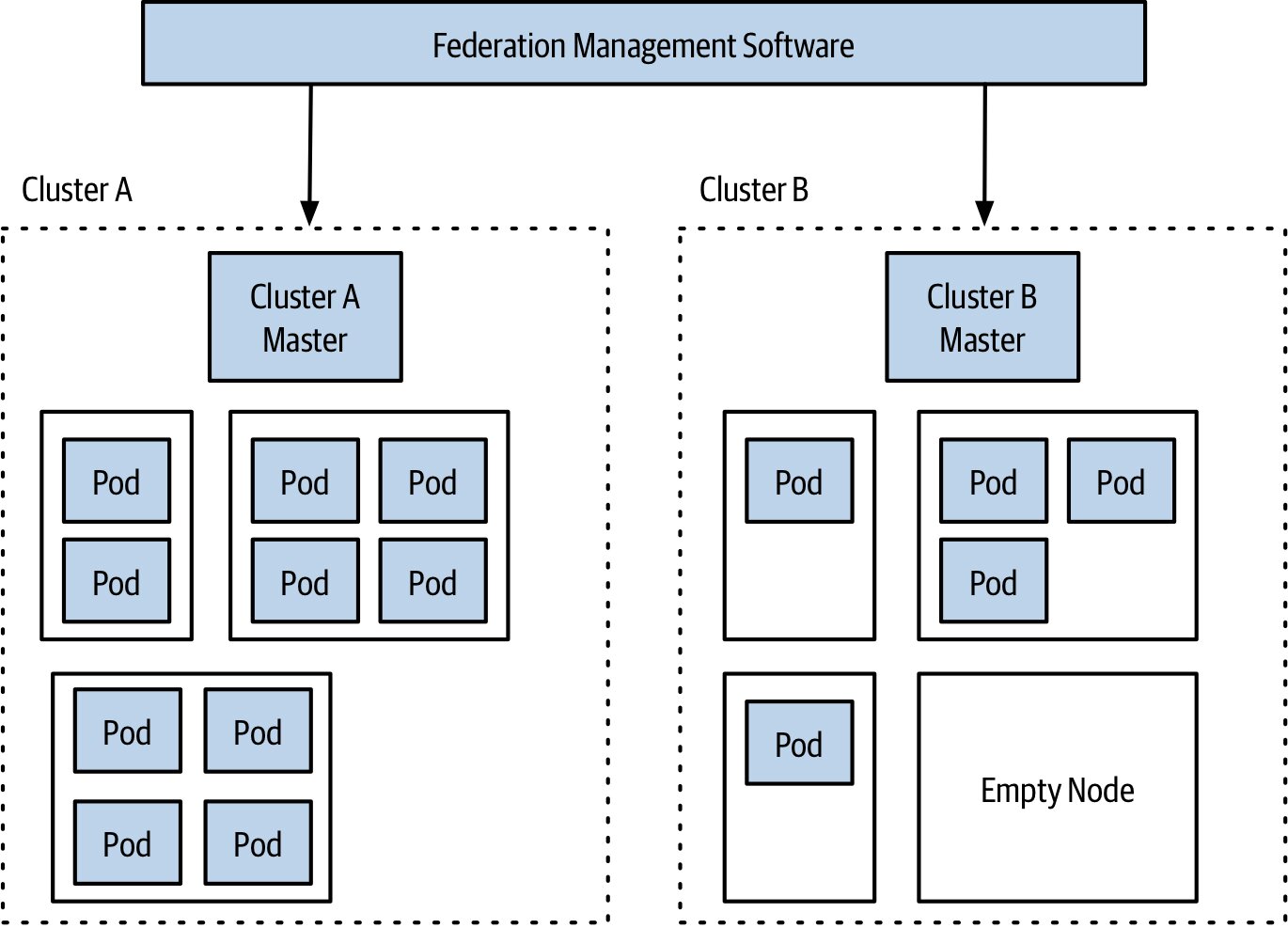
Figure 7.24:Kubernetes 中聯邦(Federation)的範例
平台 vs 可攜性#
Kubernetes 並非開箱即用的「平台」——多數團隊還要加上 service mesh、訊息代理、log aggregation 才能變成可用平台。
跨 Kubernetes 叢集的可攜性「理論上」存在,但實務上你的應用可能依賴自家平台的特定組合,搬家依然痛苦。
Helm、Operator、CRD#
- Helm:Kubernetes 的「套件管理員」,主管初始安裝
- Operator:管理生命週期(升級、備份、維運)
- CRD(Custom Resource Definition):自訂 Kubernetes 物件,與原生 CLI / RBAC 整合
Knative#
把 FaaS 體驗帶到 Kubernetes 上,但綁定 Istio。作者認為仍不夠成熟;保守組織可考慮 OpenFAAS。
該不該用 Kubernetes?#
- 自架很難——大型企業常外包專業團隊管 cluster
- 能用雲端託管就用託管(GKE、EKS、AKS)
- 若主要需求只是部署微服務,FaaS 或 PaaS 可能更合適
- 小團隊只有少數微服務:Kubernetes 是 overkill,即使是託管版
別因為「大家都用 Kubernetes」就跟風——這跟「為了用微服務而用微服務」一樣危險。
漸進式交付(Progressive Delivery)#
核心觀念:把「部署」與「發佈」拆開
——Jez Humble
- 部署(Deployment):把版本安裝到某環境
- 發佈(Release):讓使用者能用某功能
拆開兩者,就能在生產環境驗證軟體可運作但不暴露給使用者。
《Accelerate》一書研究指出:發佈頻率高的組織,失敗率反而更低。「快速發佈、低失敗率」是同一件事,不是取捨。
藍綠部署(Blue-Green Deployment)#
- 舊版(藍)執行中,新版(綠)並列上線
- 確認新版健康後,把流量切過去
- 出問題就切回,使用者無感
Feature Toggle / Flag#
- 把已部署但尚未發佈的功能藏在 toggle 後面
- 配合 trunk-based development,可隨時 commit 半成品
- 細粒度版本:依使用者群組決定看不看得到(搭配 canary)
- 工具:LaunchDarkly、Split——但作者建議從一個設定檔開始,需求成熟再升級
- 推薦深入閱讀 Pete Hodgson 的《Feature Toggles》
金絲雀發佈(Canary Release)#
名字源自礦坑用金絲雀偵測有毒氣體:先讓一小群使用者用新版,沒問題再擴大比例。
- 比例可手動調整(最早期作者一週逐步放大)
- 自動化工具如 Spinnaker 可依錯誤率動態調整流量
平行執行(Parallel Run)#
- 同一請求同時打到舊版與新版
- 比對結果(GitHub 開源 Scientist 工具)
- 只取信任的版本回應——避免「寄兩封確認 email」這種副作用
- 在巨石轉微服務時特別有用
起步建議:先把部署與發佈分開,再從藍綠/feature toggle 切入;產品經理也要了解這些技巧才能參與決策。
測試(Testing)#
微服務化把「測試」這件事推到新層級:行程內的方法呼叫變成跨網路呼叫,跨服務的功能驗證從來不是免費的。本節整理測試類型、取捨,以及在生產環境做測試的合理性。
測試類型:Brian Marick 象限#
Brian Marick 提出(後由 Lisa Crispin 與 Janet Gregory 在《Agile Testing》中發揚)的測試象限把測試分成四類:
- 縱軸:面向技術(technology-facing) vs 面向業務(business-facing)
- 橫軸:支援開發 vs 批判產品
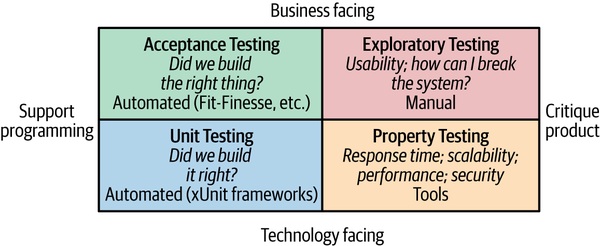
Figure 9.1:Brian Marick 測試象限
趨勢是把重複性測試自動化,騰出人力做手動探索測試(manual exploratory testing)——後者重點在「發現」,把測試員從重複勞動中解放,專注在自動化難以涵蓋的創意驗證。
測試金字塔(Test Pyramid)#
Mike Cohn 在《Succeeding with Agile》提出。原始分層:單元測試(Unit)、服務測試(Service)、UI 測試。本章把 UI 測試改稱端到端測試(end-to-end test)。
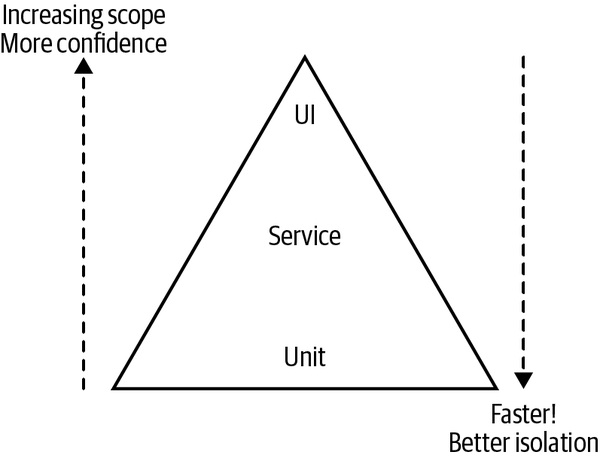
Figure 9.2:Mike Cohn 的測試金字塔
往金字塔頂走 → 測試範圍變大、信心變高,但回饋變慢、失敗時難以定位;往金字塔底走 → 測試範圍縮小、回饋變快、失敗精準到單一行程式碼。
經驗法則:愈往下層,數量愈多(一個量級)——例如 4000 unit / 1000 service / 60 end-to-end。
反模式:測試雪錐(test snow cone / 倒金字塔)——下層測試極少,主力都在大範圍測試,於是 build 慢、回饋慢、build 容易長期掛紅。
各層測試的範圍#
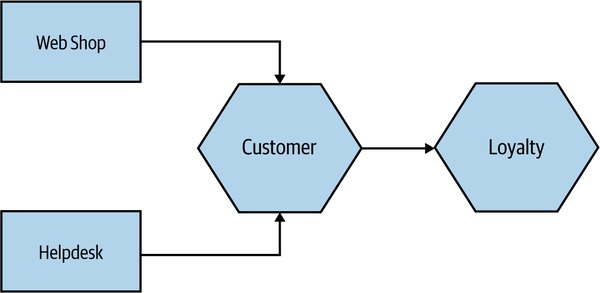
Figure 9.3:MusicCorp 系統部分元件用於說明測試範圍
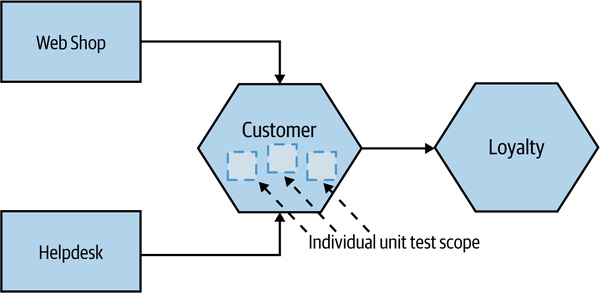
Figure 9.4:Unit 測試範圍——單一函式/類別
- 單元測試(Unit Test):單一函式或方法呼叫;不啟動微服務、不外連網路;TDD 與 property-based testing 都產出這類測試
- 服務測試(Service Test):跨過 UI,單獨對一個微服務進行測試;下游協作者用 stub 取代
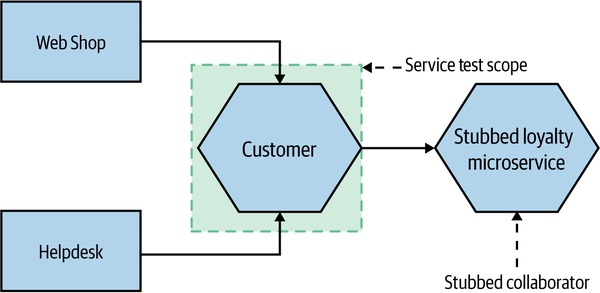
Figure 9.5:Service 測試範圍——單一微服務 + stub 下游
- 端到端測試(End-to-End Test):對整個系統運作;通常透過瀏覽器驅動 GUI
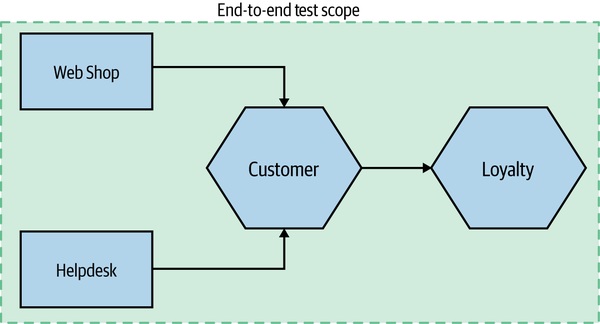
Figure 9.6:End-to-end 測試範圍——整個系統
「整合測試(integration test)」這個詞在不同團隊有不同意義(從兩個服務間互動到完整端到端),本章避免使用,請讀者依上下文對應到本章用詞。
實作 Service Test:Stub 與 Mock#
- Stub:對已知請求回傳固定回應;不在意被呼叫幾次
- Mock:除回傳值外還會驗證呼叫是否真的發生;過度使用會讓測試變脆弱
- 一般偏好 stub 多於 mock;但需要驗證副作用時 mock 仍有用
- Gerard Meszaros 把 stubs、mocks、fakes、spies、dummies 統稱「測試替身(Test Doubles)」
mountebank(Brandon Byars 開源):可程式化的 stub/mock 伺服器,支援 TCP/HTTP/HTTPS/SMTP,可以單一實例假扮多個下游服務。Capital One 也用它做大規模效能測試。
限制:不支援訊息協定的 stub——對訊息流要看 Pact。
端到端測試的麻煩#
該對哪個版本測?#

Figure 9.7:把端到端測試放在單一服務管線末端的天真做法
天真做法是把端到端測試放在每個服務管線末端,但會遇到:
- 應該對哪個版本的其他服務測?
- 多個管線各自跑同樣的端到端測試 → 浪費資源 + 重複努力
較佳模式是**多管線扇入(fan-in)**到共享的端到端測試階段:
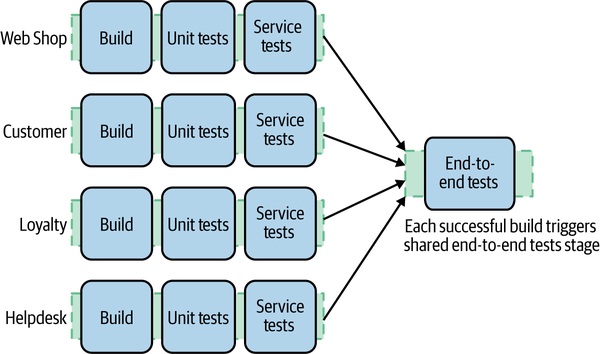
Figure 9.8:多管線扇入到共享端到端測試階段
不穩定與脆弱(Flaky and Brittle)#
隨著測試範圍變大,移動部件越多 → 測試越不穩定(flaky)。網路抖動、下游沒起來、競態條件……都會造成失敗,但失敗未必跟功能本身有關。
- Diane Vaughan 稱此現象為「偏差正常化(normalization of deviance)」——人會習慣失敗、把它當成正常,最後對紅燈麻木
- Martin Fowler 主張:找出 flaky 測試 → 修不好就先移出測試套件處理;不要讓它腐蝕對整個套件的信任
誰來寫端到端測試?#
- 無主管理 → 沒人在意紅燈、測試雪錐越長越大
- 指定特定團隊負責特定 e2e 測試(Emily Bache 提到的做法)→ 仍會被其他團隊改動連帶弄壞,難以根治
- 專屬測試團隊 → 災難:寫測試的人離產品越來越遠,回饋週期拉長
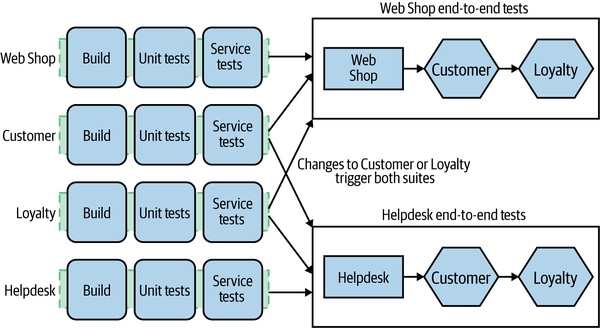
Figure 9.9:把 e2e 測試套件依職責切片,由不同團隊負責
達到一定組織規模後,跨團隊 e2e 測試本身就是反模式——應該用其他機制取代。
跑多久?堆積問題、Metaversion#
- 大型 e2e 套件可能跑一整天甚至六週(作者親身經歷)
- 跑慢 + 不穩定 → 修復需數小時,期間 commit 持續堆積(The Great Pile-Up)
- 出現「我們把這幾個服務一起測過了,乾脆把它們一起發版本號?」的念頭就糟了——Brandon Byars:「Now you have 2.1.0 problems.」Metaversion 等於放棄獨立部署性
共用測試環境會綁住獨立測試能力。《Accelerate》研究指出:高效能團隊更傾向在不需共享環境的條件下隨時測試。
替代方案:契約測試與消費者驅動契約(CDC)#
Schema 比對能抓結構性破壞,但抓不到語意性破壞(行為改變但結構未變)。CDC 正是為此而生。
怎麼做#
- 消費端寫契約測試(contract test):描述對外部服務的期望
- 把契約交給生產端,生產端在自己的 build 中執行這些契約
- 失敗時,生產端立刻知道哪個消費端會被影響——可以選擇修正、或啟動破壞性變更協商流程
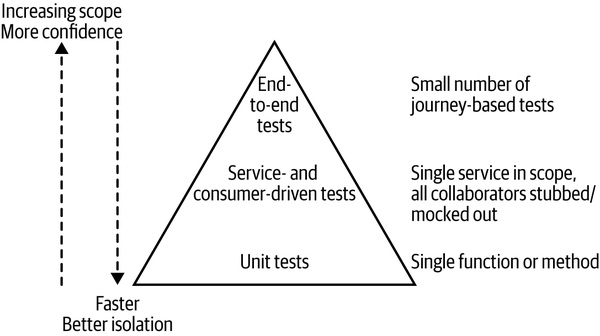
Figure 9.10:把消費者驅動契約測試整合進測試金字塔
工具#
- Pact:原本 RealEstate.com.au 內部工具,現開源;支援 JVM、JS、Python、.NET,HTTP 與訊息協定皆可
- 在消費端用 DSL 定義期望 → 啟動本地 Pact server → 產生 JSON 契約檔
- 生產端用此檔驅動實際呼叫並驗證回應
- Pact Broker 集中管理契約版本、追蹤誰使用誰
- Spring Cloud Contract:JVM 生態專用
在敏捷世界,user story 被視為「對話的占位符」——CDC 也是。它把「服務 API 該長什麼樣」的對話程式碼化;當契約破裂,就是該對話的時候了。
該不該完全捨棄端到端測試?#
大規模長期跑微服務的團隊,多數最終都減少甚至完全移除預發 e2e 測試,改用 schema、CDC、生產測試、漸進式發佈等替代機制。
把 e2e 測試當作「練習用的輔助輪」——熟練 CDC 與生產驗證後,可以拆掉。
生產環境測試(Testing in Production)#
過去測試集中在預發環境;但模型再周全也漏接得了。生產才是真正測試品質的地方——而且許多測試你已經在做了,只是沒意識到。
常見類型#
- Ping check / 健康檢查:最簡單的生產測試
- 冒煙測試(Smoke Test):部署完還沒釋出給使用者前,驗證部署成功
- 金絲雀發佈(Canary Release):本質就是「拿小群使用者測試新版本」
- 注入假使用者行為:以假帳號下單、註冊,驗證真實流程是否運作
如何安全做生產測試?#
- 部署與發佈分開(見前文「漸進式交付」),測試在「已部署但未釋出」狀態最安全
- 注入假行為時要避開副作用:別真的扣款、寄信、出貨
MTBF vs MTTR#
- 平均失敗間隔時間(Mean Time Between Failures, MTBF):希望多久才壞一次
- 平均修復時間(Mean Time to Repair, MTTR):壞了後多快復原
多數團隊只投資減少失敗(提高 MTBF),卻幾乎不投資加快修復(降低 MTTR)。在某些情境下,改善 MTTR 比堆更多測試更划算——例如把監控做好 + 快速回滾的能力。
兩者間的平衡取決於:失敗的真實成本 vs 投資測試的成本。新創驗證 idea 階段甚至可以完全跳過預發測試,先讓真實使用者反饋指引方向。
跨功能測試(Cross-Functional Testing)#
「非功能性需求(non-functional requirements)」其實涵蓋很多功能性的東西——Sarah Taraporewalla 改稱跨功能需求(Cross-Functional Requirements, CFR)。例如:延遲、可承載使用者數、無障礙性、資料安全。
- 多數 CFR 只能在生產才真正驗證
- 仍可用測試逐步逼近:例如效能測試
- CFR 可逐微服務設定:付款服務的可用性要求遠高於音樂推薦
- 常與**服務水準目標(Service-Level Objective, SLO)**一起追蹤
效能測試(Performance Test)#
微服務架構中,單次呼叫鏈長度大幅增加,任一節點變慢都拖累整體。效能測試比單體系統時代更重要。
實作要點:
- 從關鍵端到端旅程開始;之後再用小範圍測試補強瓶頸
- 逐步加壓:模擬使用者數從少到多,觀察延遲變化
- 環境盡量貼近生產(資料量、機器規格);偏差太大會產生 false positive/negative
- 跑得慢 → 通常每日跑子集、每週跑全集
- 重點是真的要看結果,並對 SLO 設定明確目標——很多團隊跑了卻沒人看數字
韌性測試(Robustness Test)#
驗證熔斷器(circuit breaker)、超時重試、多執行個體故障容錯等機制。實作較難,需要人為製造網路超時等異常。共用韌性元件(如 service mesh 的熔斷功能)尤其值得這類測試。
開發者體驗#
服務多了之後,要在開發機上跑全部變得不可能。「在雲端開發」可解決資源問題,但網路延遲讓回饋週期變慢,作者不推薦。
正確做法:開發者只跑自己團隊負責的微服務,其他全部 stub 掉。如果需要跑數十個服務才能開發,根本問題是所有權設計錯了(第 15 章會深入)。
小結#
- CI 不是裝個工具就好;持續交付要把每次提交都當候選版本
- Trunk-based development + feature flag 是現代主流
- 一個 artifact 從頭用到尾;環境差異外部化
- Multi-repo 比 monorepo 容易擴展,但小團隊兩者皆可
- 部署五原則:隔離執行、自動化、IaC、零停機、期望狀態管理
- 容器是大多數場景的最佳折衷;Kubernetes 雖普及但不是強制
- FaaS 在合適場景下能大幅降低運維負擔
- 漸進式交付(藍綠 / feature toggle / canary / parallel run)讓「快速發佈」與「低失敗率」可以兼得
- 測試金字塔:愈往下層數量愈多;避免測試雪錐
- 用 schema + CDC(消費者驅動契約測試)取代大部分跨團隊端到端測試
- 部署與發佈分開後,生產環境本身就是最佳測試場所
- 思考 MTBF vs MTTR 的取捨——加快修復常常比堆更多測試更划算
- 跨功能需求(CFR)越早關注越好;效能測試別等到上線前才做