本章主題對應原書 2nd Edition 的第 3 章「Splitting the Monolith」(位於 Foundation 部)。在本 Hugo Book 結構中放在 Implementation 部以維持「實作篇」的整體節奏。
多數讀者面對的不是白紙——你手上很可能已經有一個運行中的單體系統,正在思考如何遷移到微服務。本章整理拆解過程中的核心心態、入手點與常見模式。
先確立目標(Have a Goal)#
微服務不是目的,達成你想要的結果才是。如果現有架構就能達到目的,根本不需要拆。
- 沒有清楚的目標 → 容易把「活動」誤認為「成果」(confusing activity with outcome)
- 也常常忘了還有別的選項:例如「想擴展系統」可能用負載平衡器多開幾台單體就解決了,比拆微服務便宜許多
- 沒有目標也代表你不知道該從哪一塊開始拆——等於蒙著眼飛行
Microservices aren’t easy. Try the simple stuff first.
確定目標後,把進度對著目標衡量,必要時果斷修正路線。
漸進式遷移(Incremental Migration)#
「If you do a big-bang rewrite, the only thing you’re guaranteed of is a big bang.」
——Martin Fowler
把單體想成一塊大理石——一次炸掉它幾乎不會有好結果,要慢慢鑿。
- 把大旅程拆成許多小步驟,每一步都能驗證、學習
- 走錯也只是小步,回頭代價低
- 漸進式同時意味著「及早交付價值」,不必等大爆炸式部署
- 標準建議:先選一兩個功能切出來、上線、檢視成效
在 production 跑之前,你不會真正體會到微服務架構帶來的那種「恐懼、痛苦與折磨」。
單體不是敵人#
- 單體式架構是合理選擇;微服務化後單體常常仍會留下,只是規模縮小
- 例:為了應付負載,把瓶頸的 10% 抽出來變微服務,剩 90% 仍跑在單體裡——這完全可接受
- 「單體 + 微服務並存」可能看起來凌亂,但真實世界的架構從來不會乾淨
- 知道何時該停手,與知道何時該動手同樣重要
只有少數情境才必須完全淘汰單體:底層技術已死、基礎設施要退役、要擺脫昂貴的第三方系統。即使在這些情境下也仍應漸進式拆解。
過早分解的危險#
ThoughtWorks SnapCI 案例(與第 2 章呼應):對 CD 工具領域熟悉的團隊,一開始就直接以微服務切,幾個月後發現邊界錯了,最後合回單體再花一年才重切出穩定邊界。
從既有單體拆解通常比從零開始用微服務容易——因為你已經摸清了領域。
從哪一塊開始拆?#
優先順序由目的決定:
| 目的 | 切入點 |
|---|---|
| 想擴展系統 | 找出限制吞吐的功能優先抽出 |
| 想縮短上市時間 | 找出變動性(volatility)最高的功能(可用 CodeScene 等靜態分析工具找熱點) |
| 想降低風險 | 別動風險最高、最關鍵的部分 |
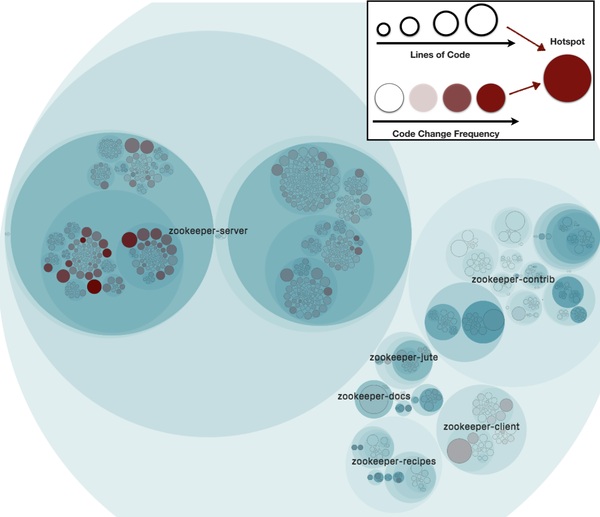
Figure 3.1:CodeScene 的 hotspot 視圖協助找出常變動的程式碼
挑選原則是兩股力量的平衡:抽取容易度 vs 抽取後的效益。
頭一兩個微服務挑「低垂果實」:影響不大、風險低、能快速建立信心與動能。如果連最容易的那塊都拆不出來,反而是訊號——也許微服務根本不適合你的組織。
按層次分解(Decomposition by Layer)#
把單一功能的拆解再切成更小的步驟。傳統 Web 三層架構提供了現成的切點:
- 使用者介面(UI)
- 後端應用程式碼
- 資料
不要只盯著後端拆。許多組織只把後端切成微服務、UI 留著沒動,最後變成另一種形式的孤島。UI 的拆分常常帶來最大的收益(第 14 章會專門討論)。
對於「後端 + 資料」這對搭檔,先拆哪個?
Code First(先拆程式碼)#
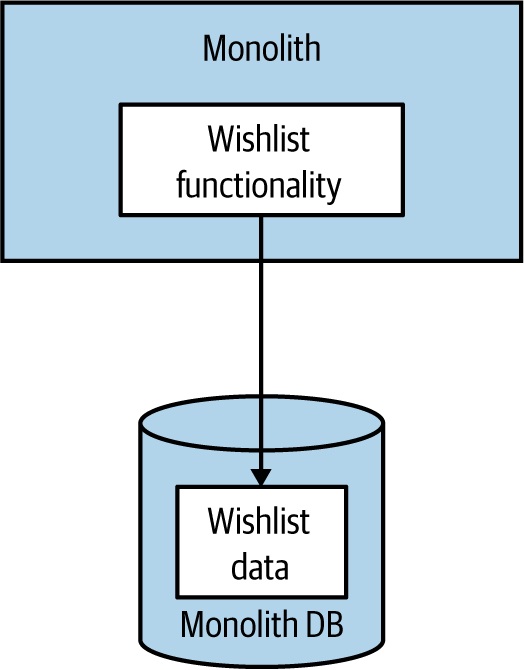
Figure 3.2:Wishlist 程式碼與資料原本在單體中
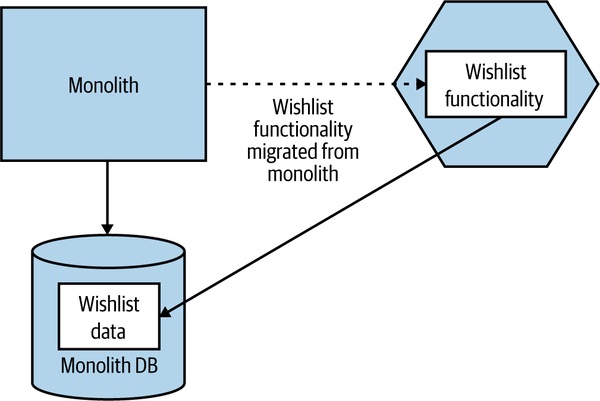
Figure 3.3:先把 Wishlist 程式碼拆出微服務,資料暫留單體資料庫
- 多數團隊的選擇——短期效益最大
- 程式碼比資料容易拆
- 若程式碼拆不乾淨,可以中止;不必再去動資料庫
- 風險:程式碼拆完才發現資料拆不出來,就麻煩了——所以動手前要先沙盤推演資料怎麼拆
Data First(先拆資料)#
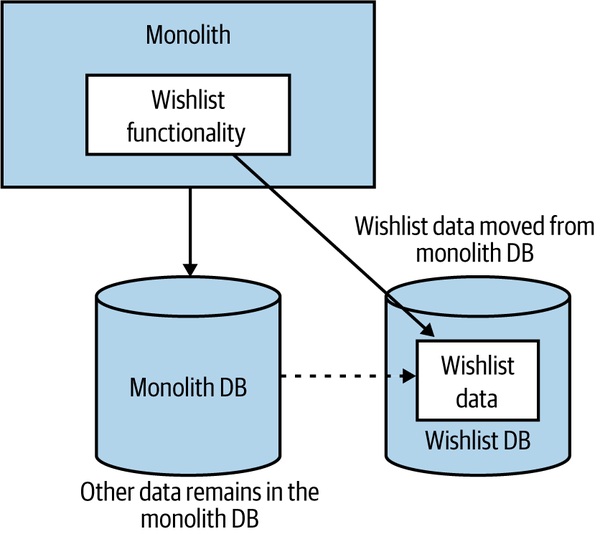
Figure 3.4:先把 Wishlist 對應的資料表拆出來
- 較少見,但能先把不確定性最高的部分擺平
- 強迫你先面對資料完整性、跨資料庫交易等難題
- 完成後再拆程式碼相對輕鬆
常用的分解模式#
絞殺榕模式(Strangler Fig Pattern)#
由 Martin Fowler 命名,靈感來自寄生於老樹外的絞殺榕——新系統從外圍逐步取代舊系統。
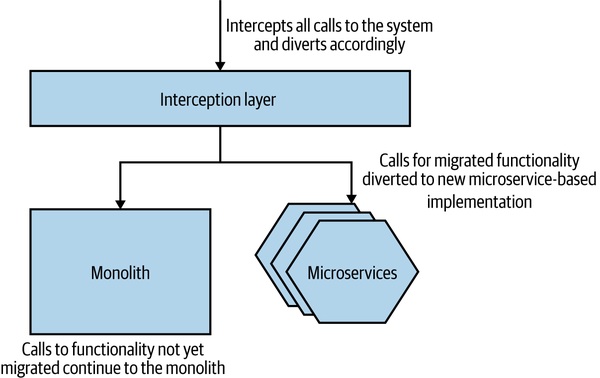
Figure 3.5:Strangler Fig 模式概覽
- 在單體前面攔截呼叫
- 已遷移的功能 → 路由到新微服務
- 未遷移的功能 → 仍由單體處理
- 最大優點:通常完全不用動單體本身——它甚至不知道自己被「包」起來了
平行執行(Parallel Run)#
把同一筆請求同時打到舊版與新版,比對結果。
- 對關鍵業務遷移特別有用
- GitHub 開源的 Scientist 工具是常見實作
功能旗標(Feature Toggle)#
允許「開/關」某項功能,或在新舊兩個實作之間切換。
- 與 strangler fig 配合:在 HTTP proxy 層加 toggle,可隨時切回舊實作
- 推薦深入閱讀 Pete Hodgson 的《Feature Toggles (aka Feature Flags)》
資料拆解的麻煩#
把資料庫拆開後,會遇到下列幾類問題。
效能(Performance)#
關聯式資料庫的 join 又快又方便,幾乎成了開發者的本能。拆成微服務後,join 操作必須從資料層搬到應用層。
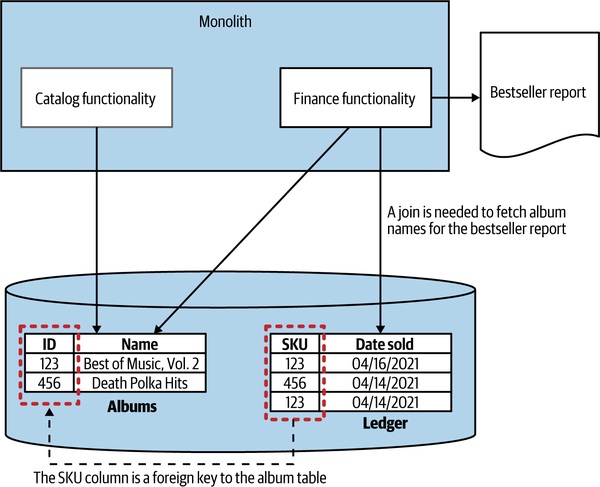
Figure 3.6:單體資料庫中跨表 join 取得銷售報表
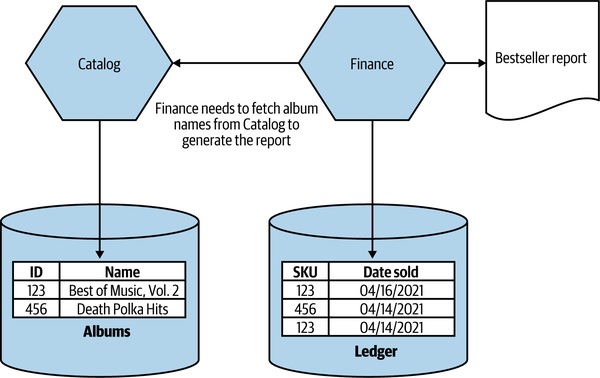
Figure 3.7:把 join 換成跨服務呼叫
- 例:MusicCorp 月度暢銷 CD 報表,原本一條 SQL 直接 join
Ledger與Albums;拆成Finance與Catalog兩服務後,要先查Ledger、再批次呼叫Catalog - 緩解:批次查詢(bulk lookup)、快取(caching)
資料完整性(Data Integrity)#
跨資料庫無法用外鍵(foreign key)強制完整性。常見「容忍模式(coping patterns)」:
- 軟刪除(soft delete):標記為已刪除而非真正刪除
- 複製需要的欄位到本地(如把 album name 複製進 Ledger);要決定如何同步後續變更
交易(Transactions)#
- 過去靠單一 ACID 交易維持一致性的習慣不再適用
- 直覺反應是用分散式交易——但成本高、保證又不如預期,第 6 章會深入分析
- 替代方案:Saga(同樣在第 6 章);簡單但帶來新的複雜度
工具(Tooling)#
- 程式碼有 IDE 重構支援;資料庫沒有
- 主流做法:版本化的 delta 腳本,依序冪等執行
- 推薦工具:Flyway、Liquibase;作者過去也曾參與開發 DBDeploy
報表資料庫(Reporting Database)#
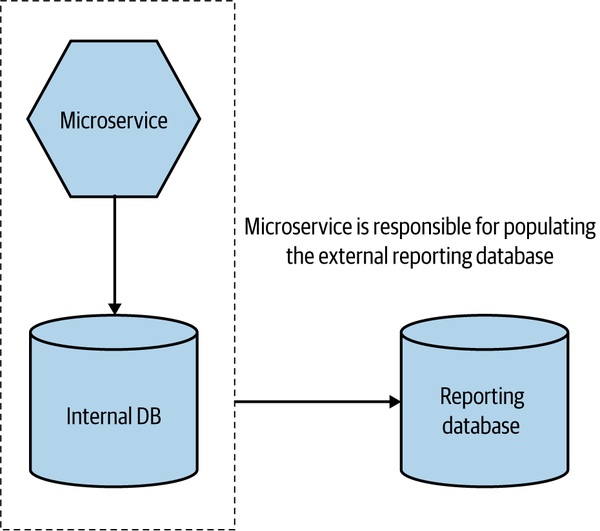
Figure 3.8:以專屬的報表資料庫對外暴露資料
當外部需要 SQL 查詢、巨型 join 或現成報表工具時,提供一個為外部存取量身訂做的資料庫:
- 微服務負責把內部資料推送到這個外部資料庫
- 仍要堅守資訊隱藏:只暴露必要欄位
- 結構可能與內部完全不同(甚至用不同型別的資料庫)
- 報表資料庫是契約的一部分,由微服務團隊維護其相容性
小結#
- 開拆之前先確立清楚的目標
- 漸進式遷移:每一小步都可以驗證、學習、回頭
- 不要妖魔化單體;單體與微服務並存常常是長期狀態
- 從變動性高、容易抽取的功能起手,建立動能
- 資料拆解伴隨效能、完整性、交易等新挑戰,要事先沙盤推演
- 推薦延伸閱讀:Sam Newman《Monolith to Microservices》(O’Reilly, 2019)