許多微服務專案在通訊層出問題,往往是因為先選技術再想需求。本章先釐清通訊樣式,再讓樣式去過濾技術選擇。
行程內 vs 跨行程:根本不同#
很多人把「物件 A 呼叫物件 B」直接對應到「服務 A 呼叫服務 B」,這是危險的類比。三個面向必須重新思考:
效能(Performance)#
- 行程內呼叫的開銷可被編譯器內聯(inline)優化掉,幾乎無感
- 跨網路呼叫毫秒級起跳;資料中心內單次封包來回也是毫秒
- 行程內 1000 次方法呼叫沒問題;跨網路做 1000 次幾乎不可接受
- 參數傳遞:行程內傳指標就好;跨網路要序列化、傳輸、反序列化
- 後果:API 設計需要重新檢視;payload 大小要關注;可能要採更高效的序列化或改傳檔案路徑
開發者必須清楚自己正在做的是不是網路呼叫——抽象藏太多會埋下效能地雷。
介面變更(Changing Interfaces)#
- 行程內變更介面:IDE 可自動重構,所有呼叫者一起更新、原子上線
- 跨服務變更介面:服務各自獨立部署,向後不相容變更必須鎖步部署(lock-step deployment)或分階段過渡
錯誤處理(Error Handling)#
行程內錯誤是確定的;分散式系統有大量你無法掌控的錯誤源:網路逾時、下游不可用、容器被 OOM 殺掉……
- 多數錯誤具有**短暫性(transient)**特質——可重試
- 需要豐富的錯誤語意讓客戶端做正確處置
- HTTP 是好範例:4xx 表示請求問題(不重試)、5xx 表示伺服端問題(如 503 Service Unavailable 可重試、501 Not Implemented 重試也沒用)
通訊樣式總覽#
先決定樣式,再選技術。把 Kafka 拿去做請求/回應、用 SPA 框架蓋傳統網站,都是「先選技術」的後果。
| 樣式 | 說明 |
|---|---|
| 同步阻塞(Synchronous Blocking) | 呼叫者送出請求後阻塞等回應 |
| 非同步非阻塞(Asynchronous Non-Blocking) | 送出後可以繼續做其他事 |
| 請求/回應(Request-Response) | 期待對方回覆結果 |
| 事件驅動(Event-Driven) | 發佈事件,誰收聽誰反應 |
| 共用資料(Common Data) | 透過共用儲存交換資料 |
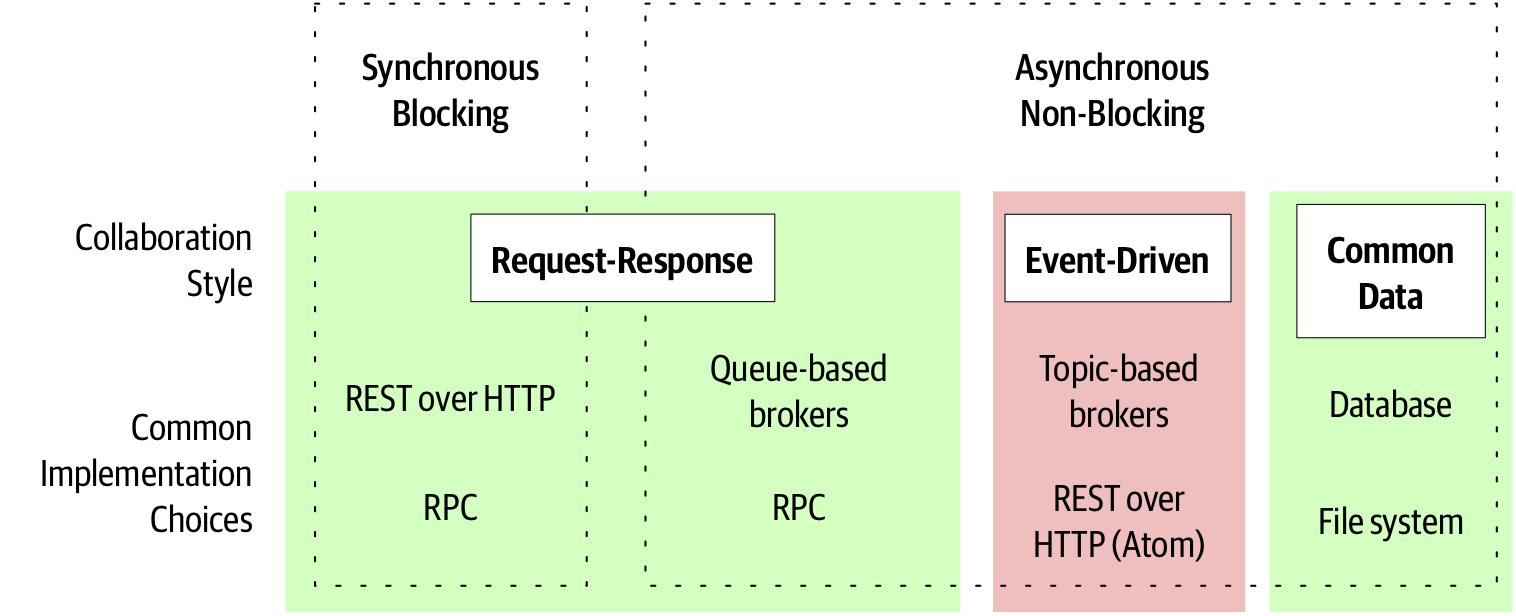
Figure 3.1:微服務間不同通訊樣式與對應實作技術
決策路徑:
- 同步還是非同步? 同步幾乎必然走請求/回應
- 若選非同步:再判斷是事件驅動、非同步請求/回應、還是共用資料
事件驅動本質是非同步;請求/回應則同步、非同步皆可。
同步阻塞(Synchronous Blocking)#
優點#
- 心智模型熟悉,從單體系統過來最直覺
- SQL 查詢、HTTP API 呼叫多半都是這種風格
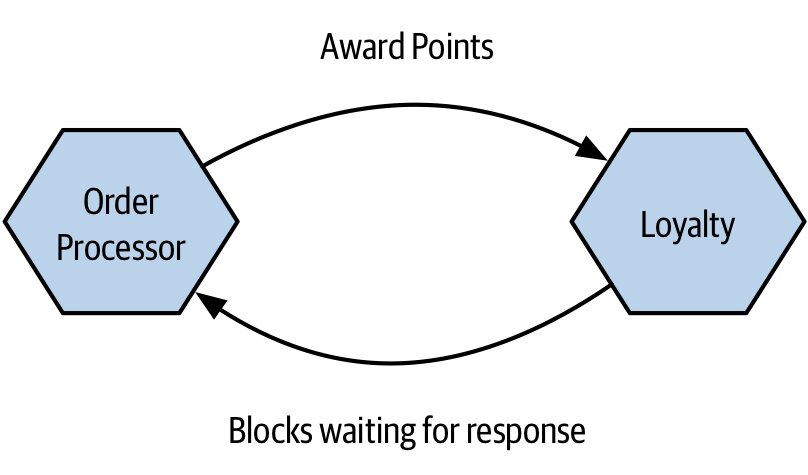
Figure 3.2:Order Processor 同步呼叫 Loyalty 並阻塞等待回應
缺點#
- 與時間耦合綁定:下游必須在線
- 下游慢,上游就一起慢
- 容易引發級聯失敗(cascading failure)
同步呼叫鏈一長就麻煩:
Order Processor → Payment → Fraud Detection → Customer,任何環節有狀況整條鏈就掛掉,且開著的網路連線會大量累積,導致連線耗盡、網路擁塞。
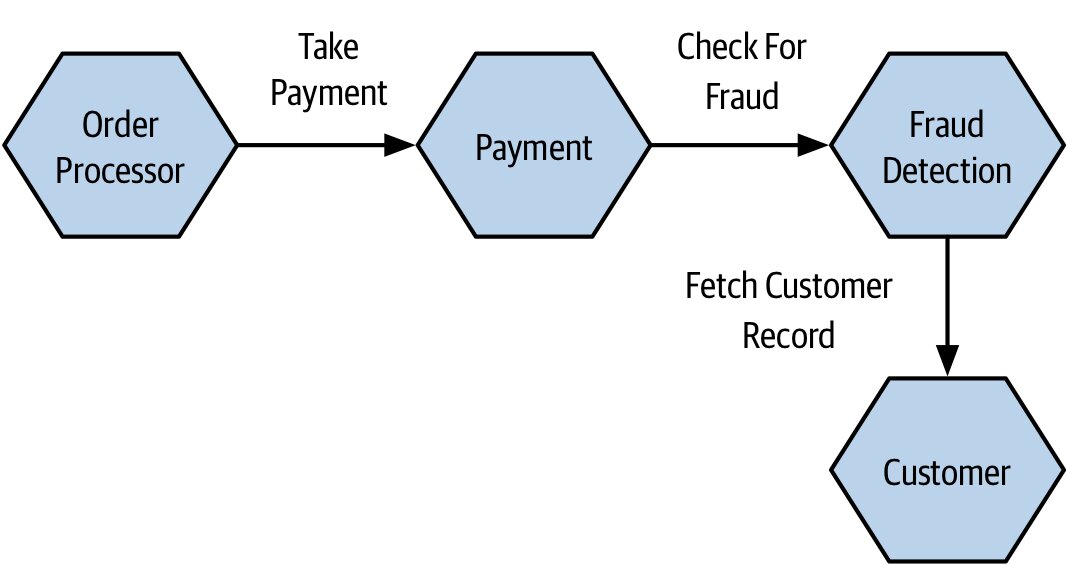
Figure 3.3:訂單處理流程中同步檢查可疑詐欺行為
適用情境#
- 簡單的微服務拓樸,初期可接受
- 鏈路變長時要思考重組——例如把詐欺偵測(Fraud Detection)移出主流程改為背景作業,縮短關鍵路徑
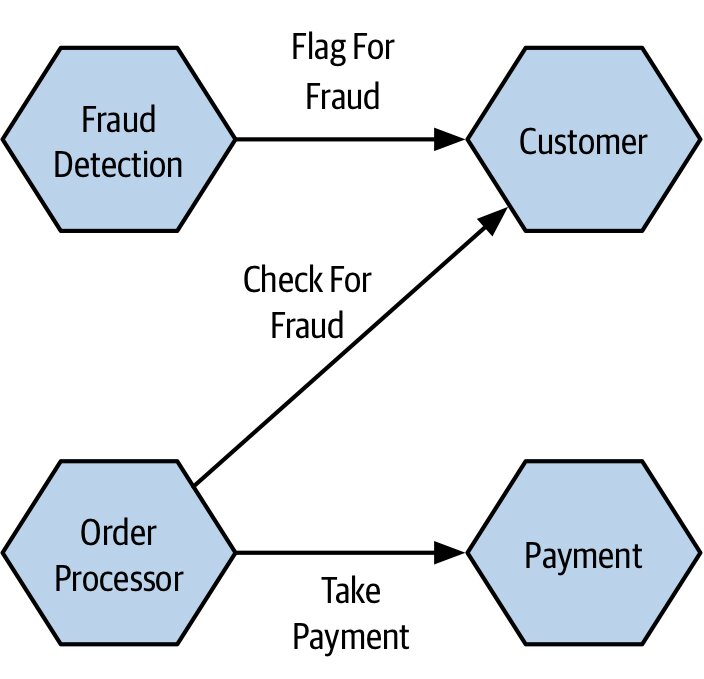
Figure 3.4:將詐欺偵測改為背景作業以縮短呼叫鏈
非同步非阻塞(Asynchronous Non-Blocking)#
主要三種子模式:
- 共用資料通訊
- 請求/回應
- 事件驅動
優點#
- 時間解耦:呼叫端與接收端不必同時在線
- 適合長時間執行的工作。例如
Order Processor通知Warehouse出貨,揀貨包裝可能要好幾小時——同步阻塞顯然不可行
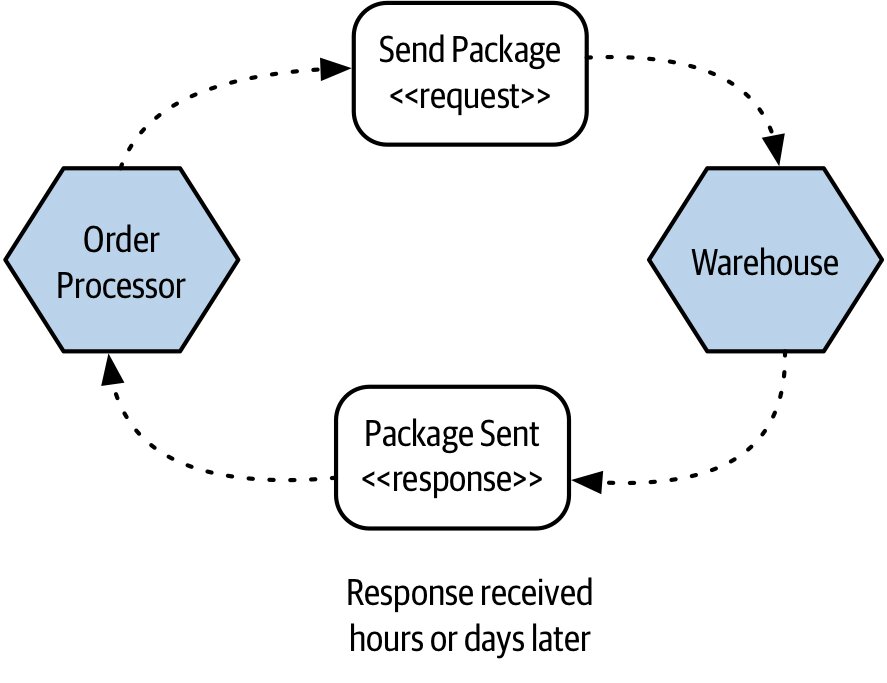
Figure 3.5:Order Processor 以非同步方式啟動包裝與出貨流程
缺點#
- 心智負擔:複雜度與選擇都更多
- 各種 async 風格、訊息技術讓你選到頭暈
- 容易踩各種非同步特有的坑
async/await不一定真的非同步JavaScript 的
async/await在程式碼層讓你以同步方式撰寫,但await本身會阻塞當前流程。底層或許非同步,呼叫端的視角依然是同步阻塞。
適用情境#
- 長時間執行的工作
- 難以重組的長呼叫鏈
- 高吞吐情境
共用資料通訊(Communication Through Common Data)#
A 把資料寫到某共用位置,B 之後讀取。本質上是非同步。
實作#
- 持久化儲存:檔案系統、資料庫、分散式記憶體
- 接收方需要**輪詢(polling)**或被通知有新資料
- 兩種典型場景:
- 資料湖(Data Lake):原始格式上傳,下游自行處理(耦合最鬆)
- 資料倉儲(Data Warehouse):結構化、推資料的服務需了解 schema
- 單向流動最容易理解;多服務同時讀寫共享資料庫則回到第 2 章「共用耦合」的危險區
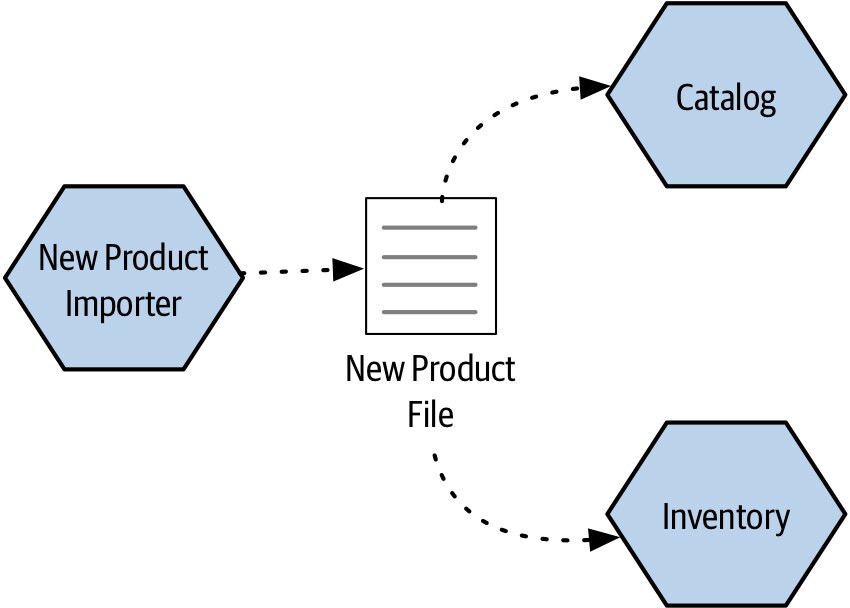
Figure 3.6:一個微服務寫出檔案供其他微服務使用
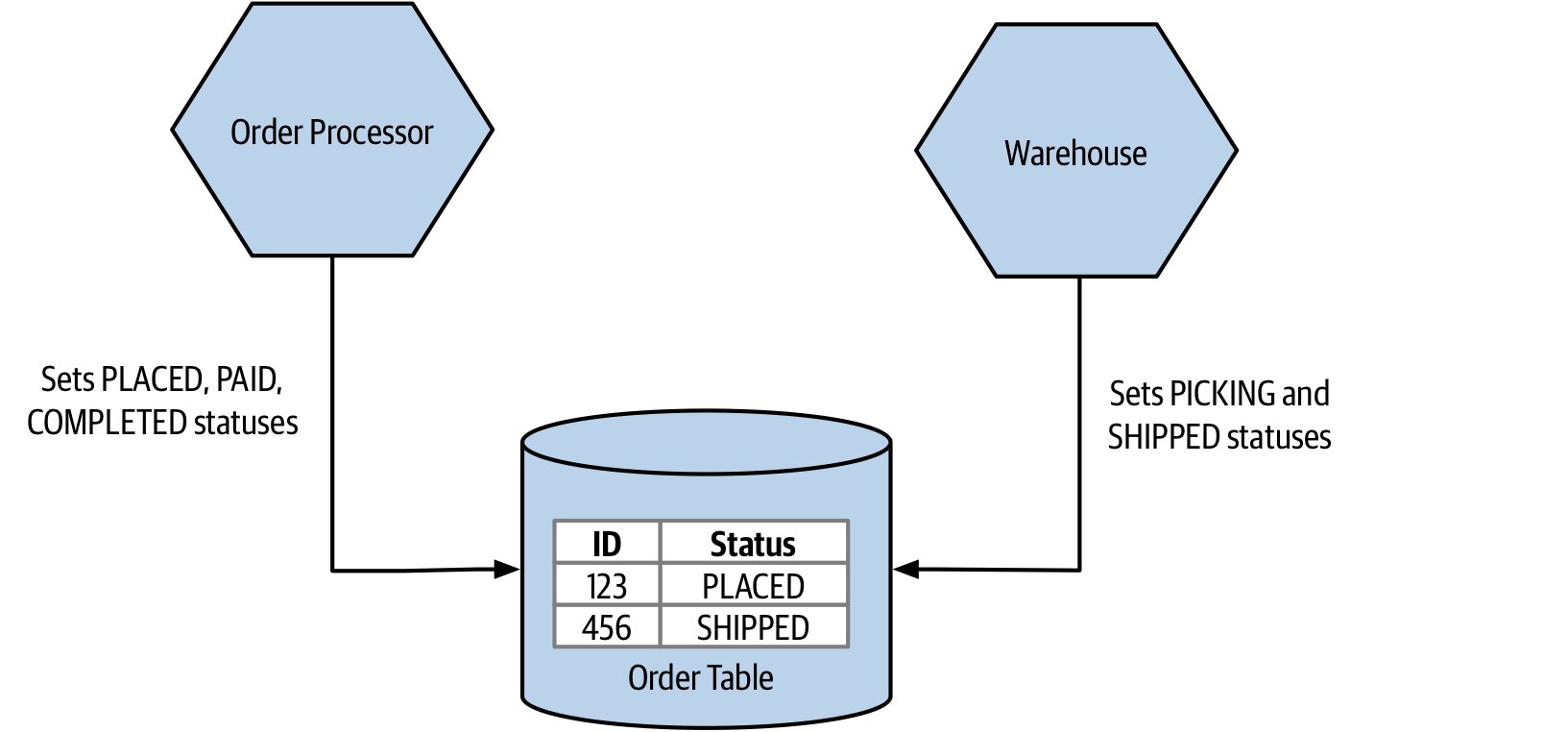
Figure 3.7:共用耦合範例—Order Processor 與 Warehouse 共同更新同一筆訂單
優點#
- 技術門檻低,能讀寫檔案/資料庫就能做
- 可橋接老舊系統(mainframe、COTS)
- 大量資料傳輸不是問題
缺點#
- 通常是高延遲,輪詢拖慢回應
- 共用儲存本身成為耦合源
- 通訊韌性受限於底層儲存
適用情境#
- 與舊系統互通
- 大批量資料交換(GB 級檔案、百萬列載入)
請求/回應(Request-Response)#
呼叫者送請求,期待回應。可同步或非同步實作。
同步實作#
- 開連線、送請求、阻塞等待回應
- 接收端不需了解誰呼叫它
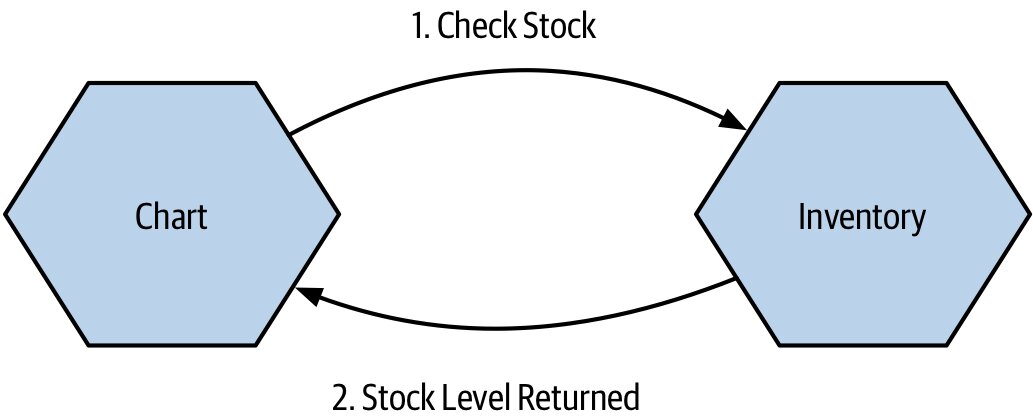
Figure 3.8:Chart 微服務向 Inventory 詢問庫存量
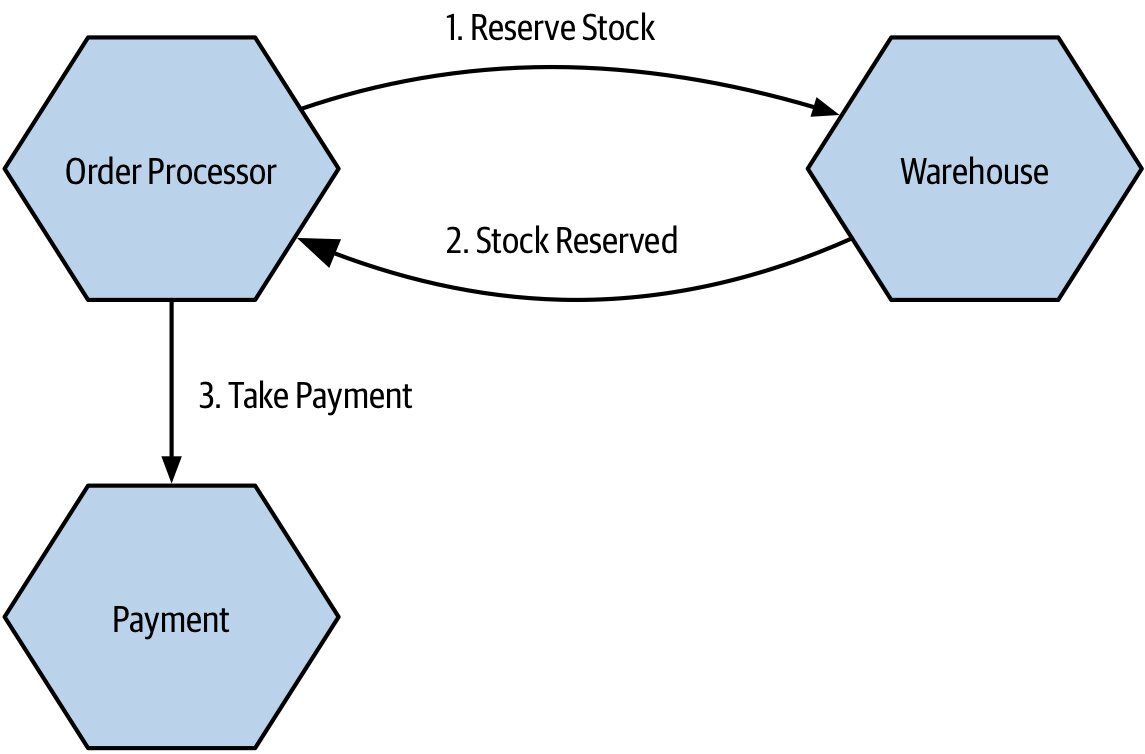
Figure 3.9:Order Processor 需先確認庫存可保留才能收款
非同步實作#
- 透過訊息代理(message broker)排隊
- 接收端需知道回覆要送回哪裡(透過 reply queue 或訊息中的 reply-to 欄位)
- 上游收到回應時,需要把它與原始請求對應起來——通常把狀態存資料庫,回應到達時重新載入
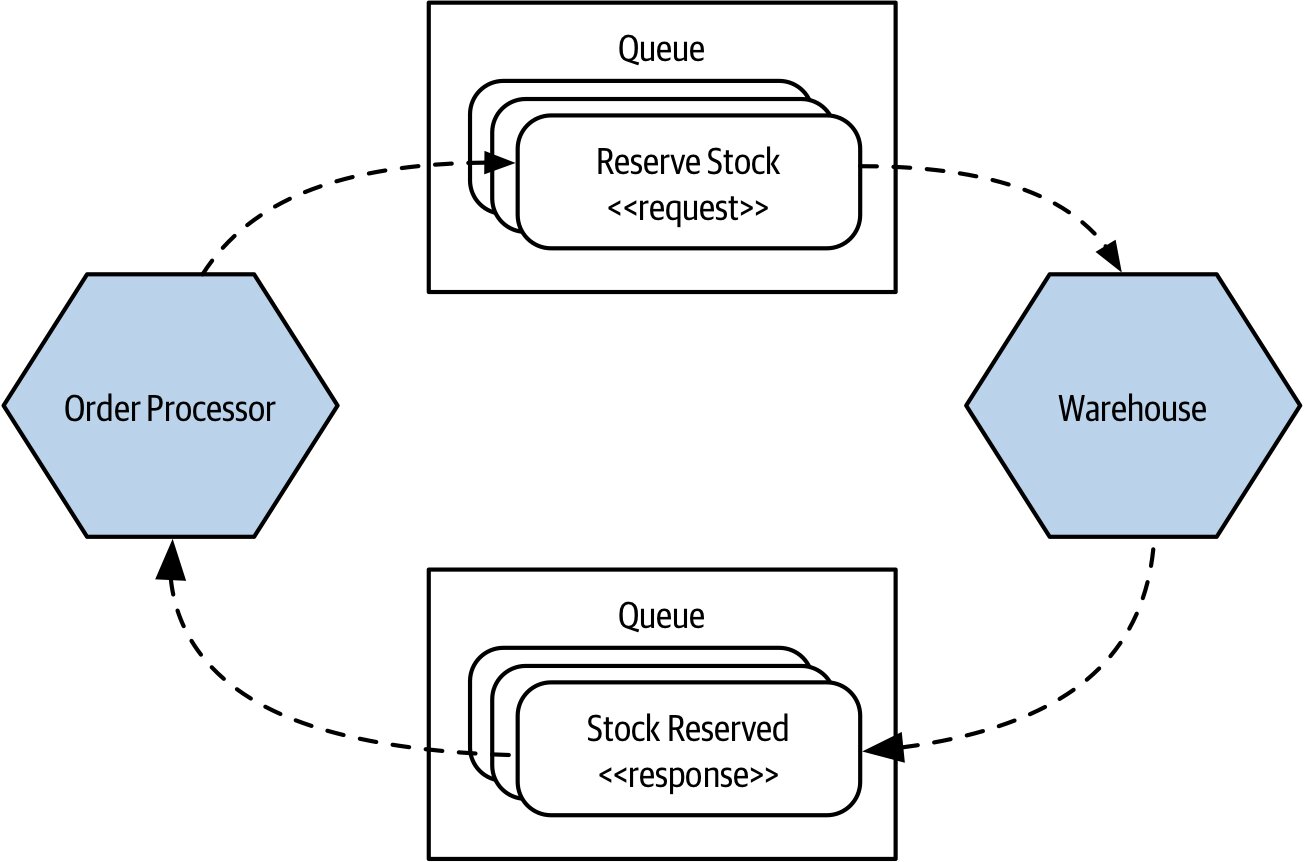
Figure 3.10:使用佇列傳送庫存保留請求
平行 vs 序列:需要打三家供應商價格時,平行呼叫總延遲 = 最慢那家;序列呼叫總延遲 = 三家相加。能平行就平行。
指令 vs 請求#
作者偏好「請求(request)」而非「指令(command)」。指令暗示必須執行;請求允許下游依自身邏輯拒絕。微服務應有權拒絕無效請求。
適用情境#
- 需要對方回應才能繼續處理
- 需要知道是否成功以做補償動作(如重試)
事件驅動(Event-Driven)#
服務發佈事件——某件已發生事實的陳述。發佈者不知道、也不需要知道誰會收聽;收聽者各自反應。
事件驅動是責任反轉:請求/回應模式下是「
Warehouse命令Notifications寄信」;事件驅動模式下變成「Warehouse廣播事件,Notifications自己決定要不要寄信」。這種責任分散與「自治團隊」的組織思維非常契合。
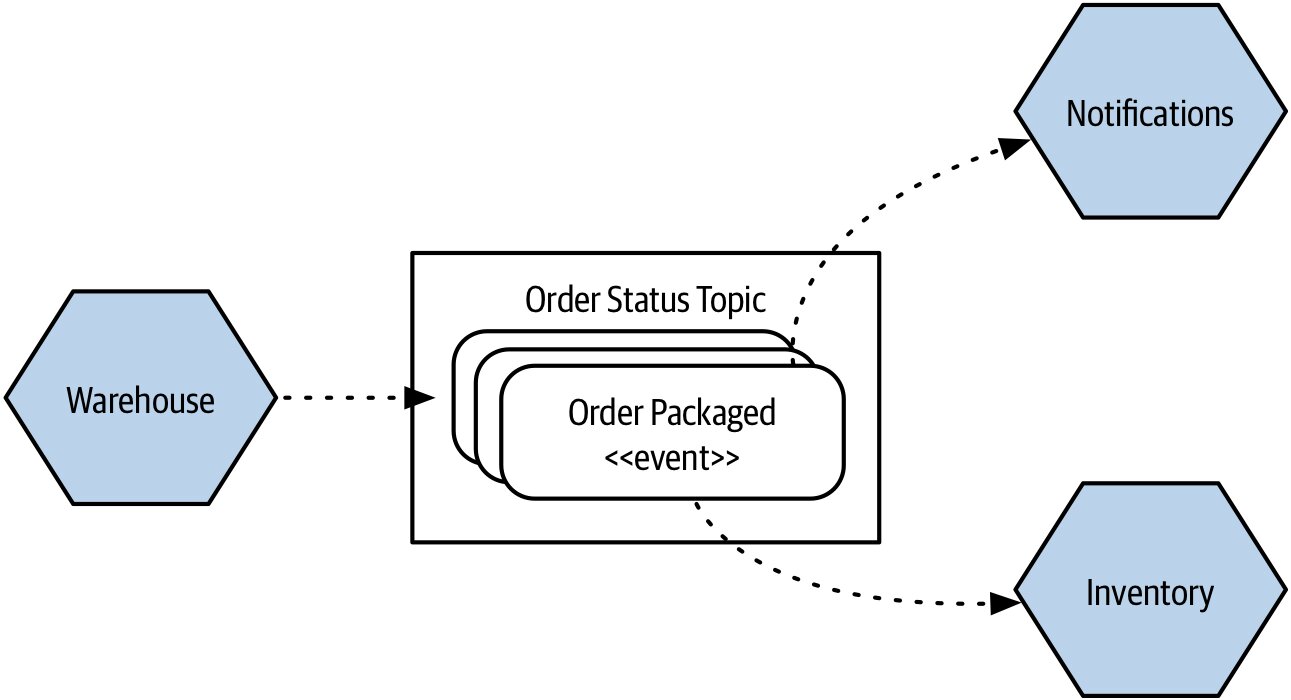
Figure 3.11:Warehouse 發出事件供下游微服務訂閱
事件 vs 訊息#
- 事件(Event):已發生事實的陳述(內容/語義)
- 訊息(Message):傳輸載體
- 廣播事件時,把事件包進訊息送出;訊息是介質,事件是 payload
實作#
- 訊息代理(如 RabbitMQ、Kafka):處理發佈訂閱、消費者狀態追蹤;複雜但功能完整
- HTTP + ATOM:用 feed 形式發佈事件;客戶端輪詢;HTTP 規模化能力佳但低延遲不好
「笨中間件、聰明端點(dumb middleware, smart endpoints)」——別讓 ESB 之類的中間件積累過多邏輯。Queue 本身單純,被廠商包裝後會慢慢長成怪物。
若已有可靠的訊息代理,直接用它做發佈訂閱。若用 ATOM 的成本越拉越高(例如要實作競爭消費者模式 Competing Consumer),就別執著於沉沒成本,回頭採用代理。
事件該包含什麼?#
- 只放 ID
Notifications收到「客戶建立」事件後,仍須回頭呼叫Customer取得 email、姓名- 增加領域耦合
- 大量訂閱者同時回問來源,會把來源服務打爆
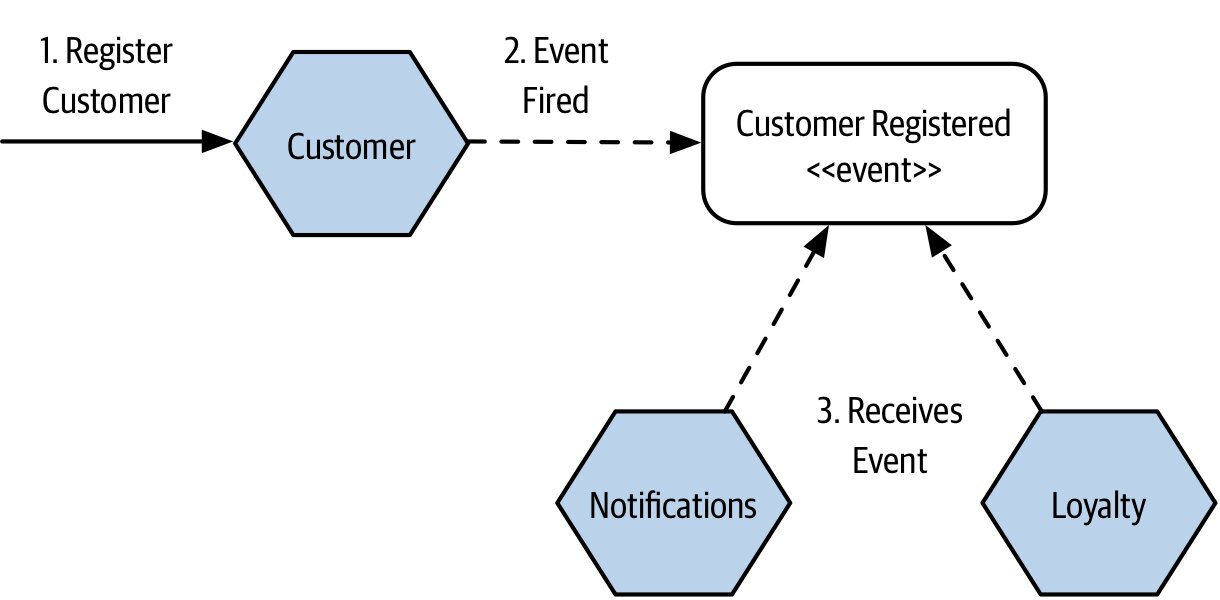
Figure 3.12:新客戶註冊時 Notifications 與 Loyalty 收到事件
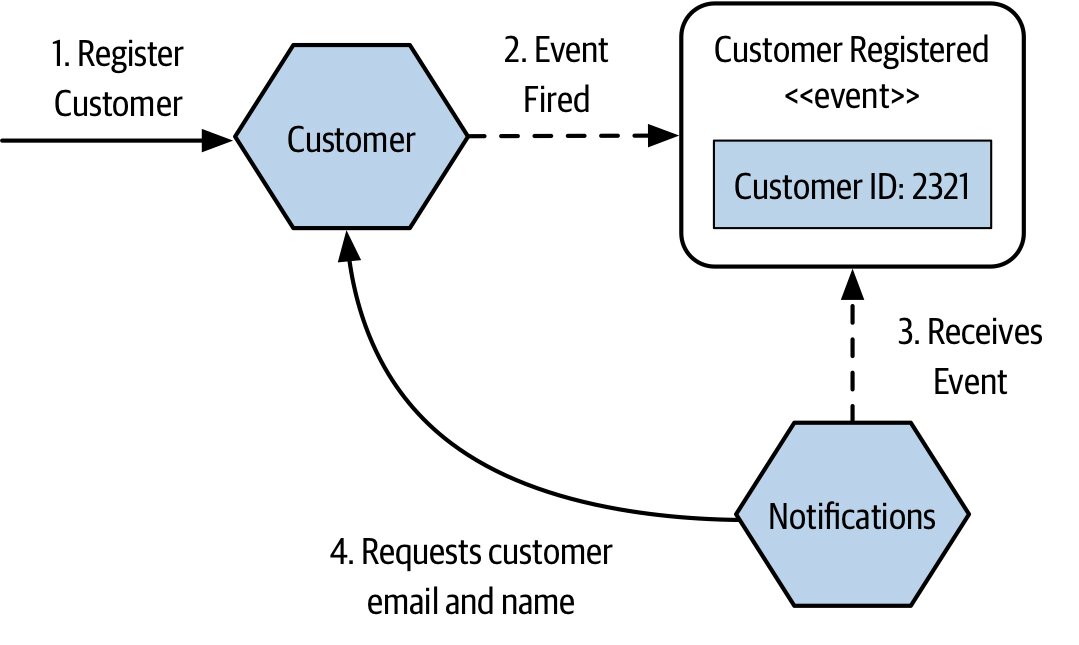
Figure 3.13:Notification 需另向 Customer 取得事件中沒有的資訊
- 完整資訊(作者偏好)
- 把你願意透過 API 分享的所有資訊放進事件
- 接收者更自給自足、耦合更鬆
- 事件可同時作為歷史紀錄,配合事件溯源(event sourcing)使用
- 但事件變成對外契約的一部分,刪欄位會破壞外部消費者
- 需注意敏感資料(PII、信用卡)是否該擴散——可考慮分視域通訊(Split Horizon Communication)
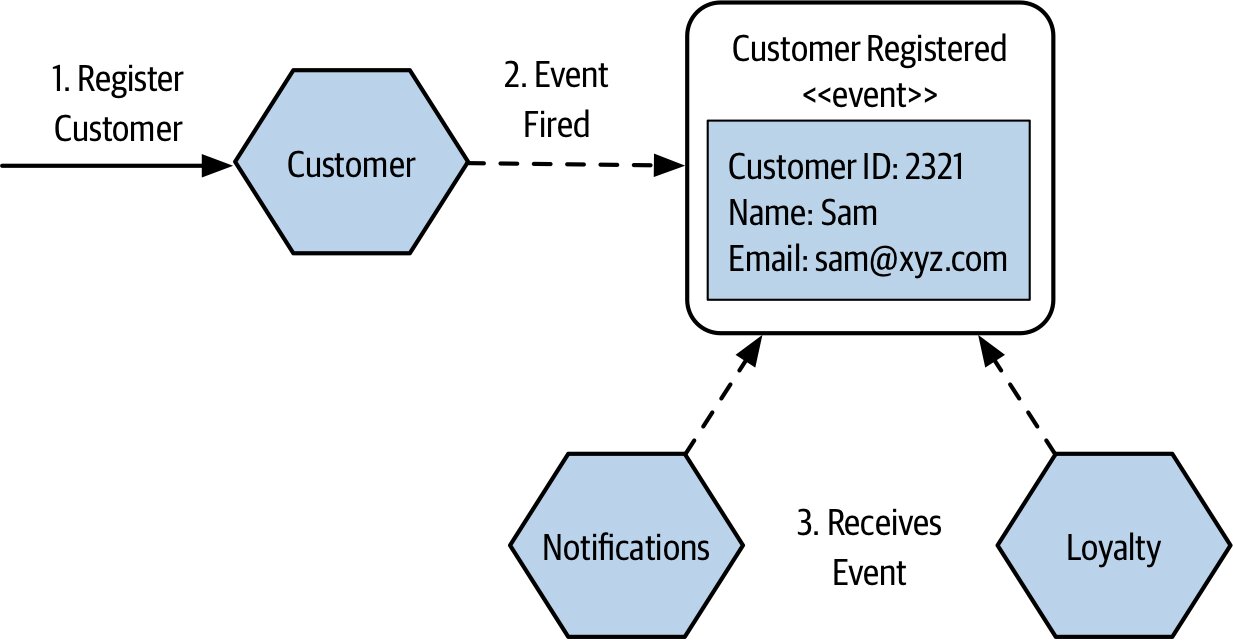
Figure 3.14:事件含完整資訊讓接收方無需再呼叫來源服務
警示:「真的成功了嗎?」#
2006 年作者銀行專案的經驗:採用 Competing Consumer,但訊息有 bug 導致 worker 一個個爆掉;交易型佇列又把訊息歸還,下一個 worker 接到也死。Martin Fowler 稱此為「災難性的故障轉移(catastrophic failover)」。
教訓:
- 設定最大重試次數
- 建立死信佇列(dead letter queue)/ 訊息醫院(message hospital)
- 提供 UI 檢視與重送失敗訊息
- 採用**關聯 ID(correlation ID)**追蹤跨服務請求
- 監控比同步系統更重要
小結#
- 通訊樣式沒有單一正解;先看情境再選樣式,再從樣式過濾技術
- 同步阻塞簡單但易引發級聯失敗
- 非同步解耦時間,但複雜度提高
- 事件驅動讓系統最鬆耦合,但帶來新一類陷阱:訊息中毒、重試風暴、難以追蹤
- 推薦延伸閱讀:Hohpe & Woolf 的《Enterprise Integration Patterns》