引子:MusicCorp 上場#
MusicCorp 是貫穿全書的虛構案例:一家從實體 CD 零售轉型線上的公司。它的目標很明確——讓變更越容易越好——這正是微服務想解決的問題。
本章要回答的核心問題是:什麼樣的服務邊界算是好的邊界?
微服務本質上是模組化分解(modular decomposition)的一種形式,因此可以借用結構化程式設計(structured programming)時代的成熟觀念——只是多了「跨網路互動」這層額外複雜度。
三個基礎概念:資訊隱藏、內聚、耦合#
資訊隱藏(Information Hiding)#
David Parnas 1971 年提出資訊隱藏的概念——把細節盡量藏在模組(或微服務)邊界內。Parnas 認為良好的模組化應帶來三個好處:
- 改善開發時間(improved development time):可平行作業、降低增加新人的衝擊
- 可理解性(comprehensability):每個模組可獨立檢視與理解
- 彈性(flexibility):模組可獨立變更、重新組合來提供新功能
但「分模組」本身不會自動帶來這些好處——關鍵在於邊界畫得對不對。
Parnas 還說過一句精妙的話:
The connections between modules are the assumptions which the modules make about each other.
——David Parnas
模組之間的「連接」其實就是它們對彼此所做的假設(assumptions)。假設越少,連接越鬆,獨立變更就越容易。
微服務和模組的差別在於——它甚至能在不部署其他人的情況下被單獨部署,把上述三個好處放大。
內聚(Cohesion)#
對內聚最簡潔的定義:「一起變動的程式碼,住在一起。」
(The code that changes together, stays together.)
我們希望相關行為集中在同一個服務內,這樣商業需求變更時只需動一處、發佈一處。若相關功能散落在多個服務,每次發佈就得協調多個服務同時上線——既慢又危險。
- 相關功能聚集 → 強內聚(strong cohesion)
- 相關功能散落 → 弱內聚(weak cohesion)
耦合(Coupling)#
服務鬆耦合(loosely coupled)的判斷標準:改 A 服務時,B 服務不需要跟著改。
導致緊耦合的常見錯誤:
- 整合方式選錯(例如過度暴露內部結構)
- 服務間互動過於頻繁(chatty communication)——除了效能變差外,也會把更多細節綁進對方
內聚與耦合的交互作用#
Constantine 定律(Constantine’s Law):「結構若內聚強而耦合弱,則穩定。」
——Albert Endres 與 Dieter Rombach(紀念結構化設計先驅 Larry Constantine)
對微服務而言,穩定的邊界就是獨立部署的前提。若契約(contract)不停做向後不相容(backwards incompatible)的變更,所有上游消費者都得跟著動,獨立部署便無從談起。
但有時系統某些區塊正處在劇烈變動期,邊界不可能穩定——本章後段會以 ThoughtWorks 的 SnapCI 為例討論這個情況。
耦合的型態(從鬆到緊)#
並非所有耦合都壞——有些不可避免。重點是辨識每種耦合並控制其程度。
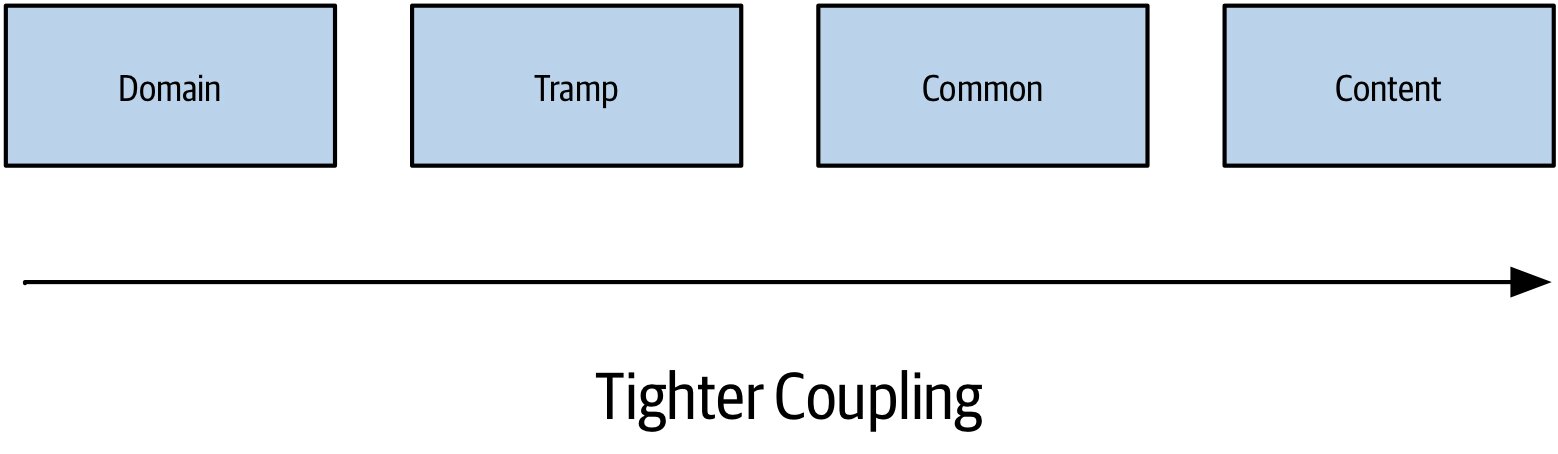
Figure 2.1:耦合型態的鬆緊光譜
1. 領域耦合(Domain Coupling)#
服務 A 因為需要服務 B 提供的功能而呼叫 B。例如 Order Processor → Warehouse 訂貨、→ Payment 收款。
- 微服務系統中幾乎不可避免
- 屬於最鬆的耦合形式
- 警訊:若一個服務依賴大量下游服務,可能代表它做得太多
- 處理原則:只分享絕對必要的資訊,傳遞最少的資料量
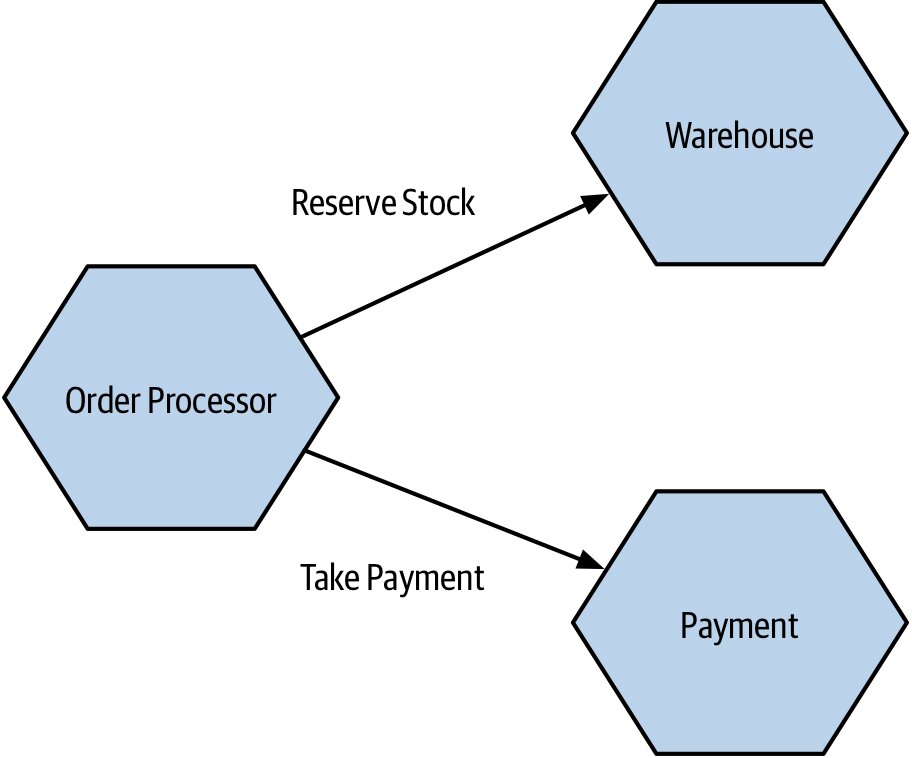
Figure 2.2:Order Processor 呼叫多個下游服務的領域耦合
順帶一提:時間耦合(Temporal Coupling)
當 A 同步呼叫 B 時,A 與 B 必須同時在線、同時可達。這雖屬執行期問題,但隨著服務數量增加,時間耦合會嚴重限制系統可擴展性。化解方式:採用非同步通訊(如訊息代理 message broker)。第三章會更深入處理。
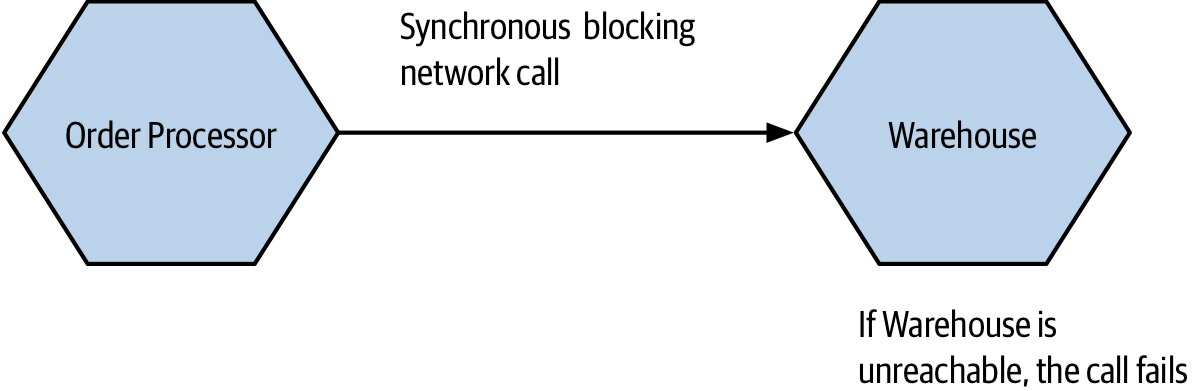
Figure 2.3:Order Processor 同步呼叫 Warehouse 造成的時間耦合
2. 穿透耦合(Pass Through Coupling)#
A 服務僅僅是把資料傳給 B,目的是讓 B 再傳給更下游的 C。
- A 不只知道 B 存在,連 C 的結構需求都得知道
- C 的契約變更會連鎖影響 A 與 B
- 屬於最具問題的實作耦合形式之一
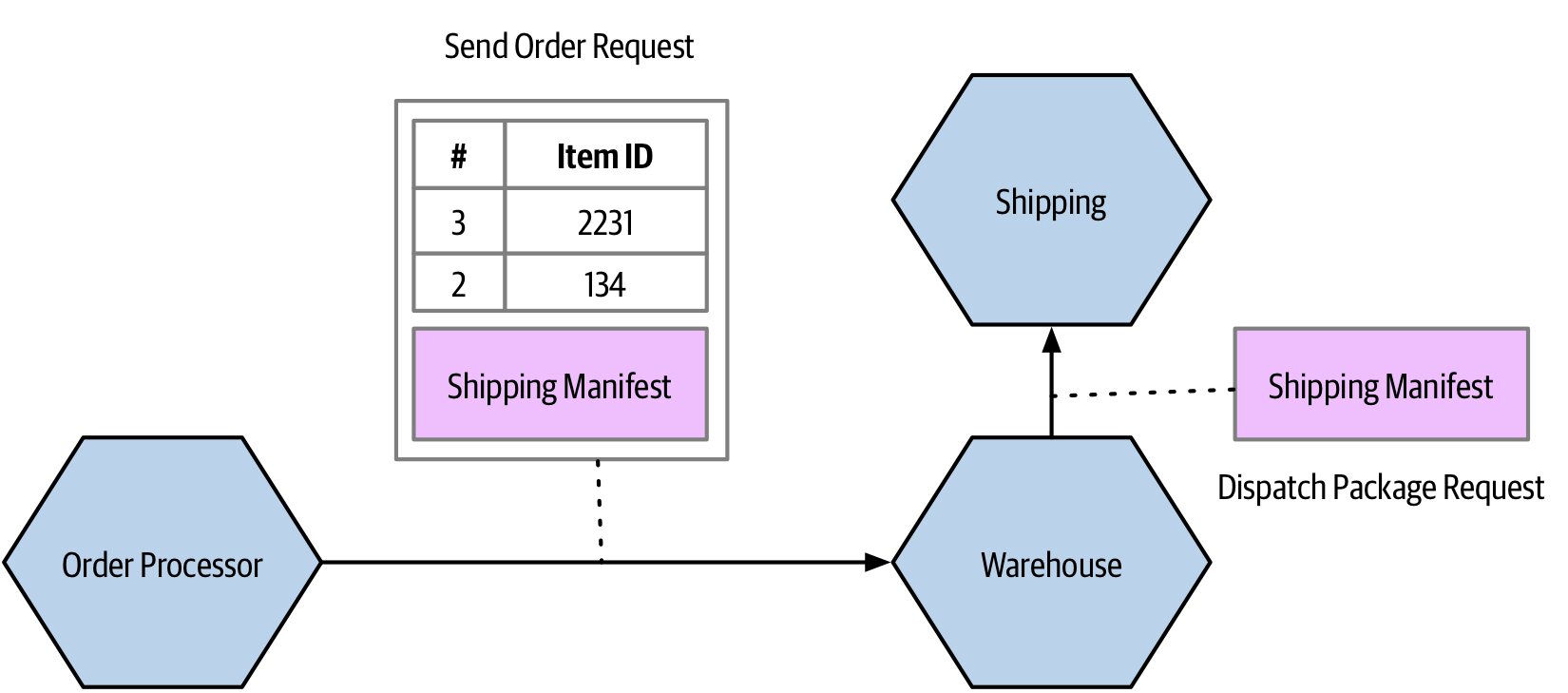
Figure 2.4:資料僅為了下游需求而被穿透傳遞的耦合
化解方式:
- 讓 A 直接呼叫 C,跳過 B(但會增加 A 的領域耦合)
- 把建構下游請求的邏輯封裝在 B 內部,A 只傳必要欄位
- 把資料當作不透明 blob 通過 B(B 不解析內容)
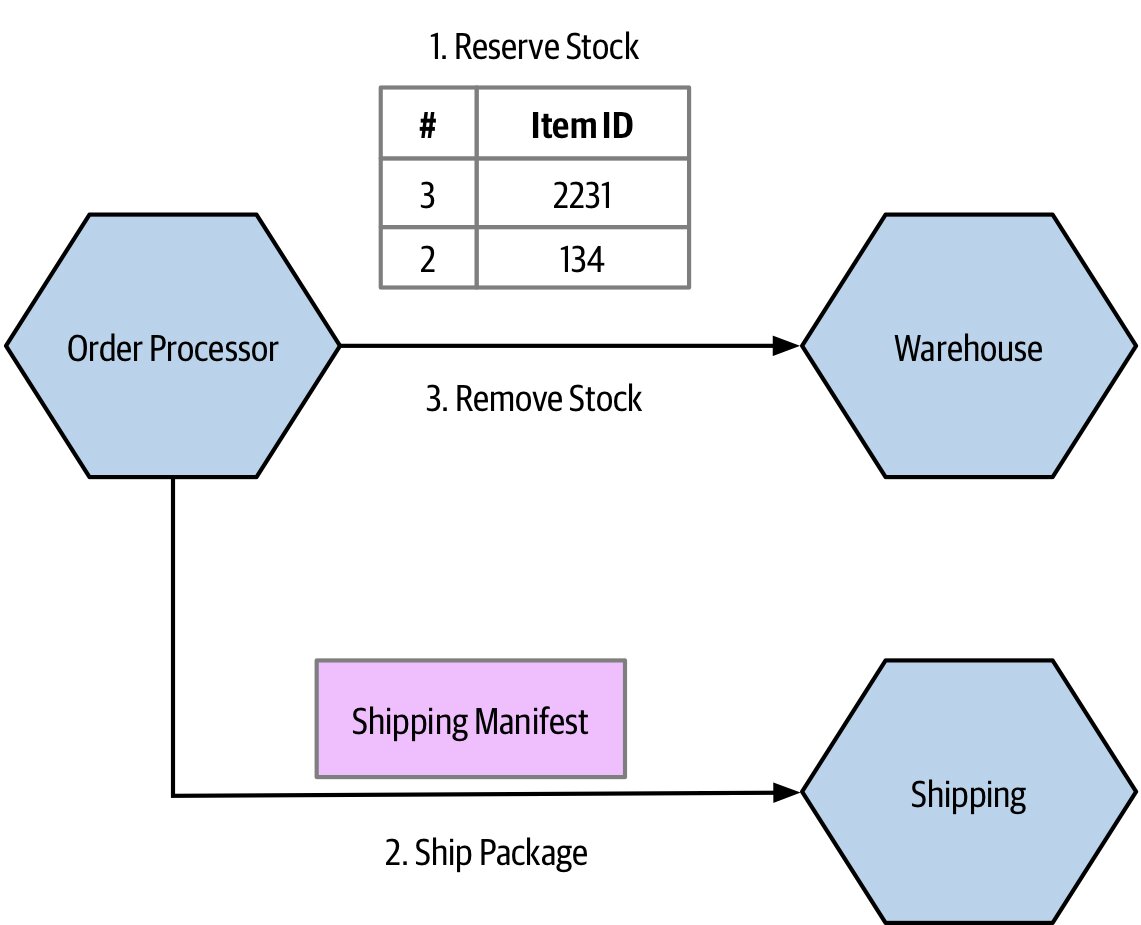
Figure 2.5:直接與下游服務溝通以避開穿透耦合
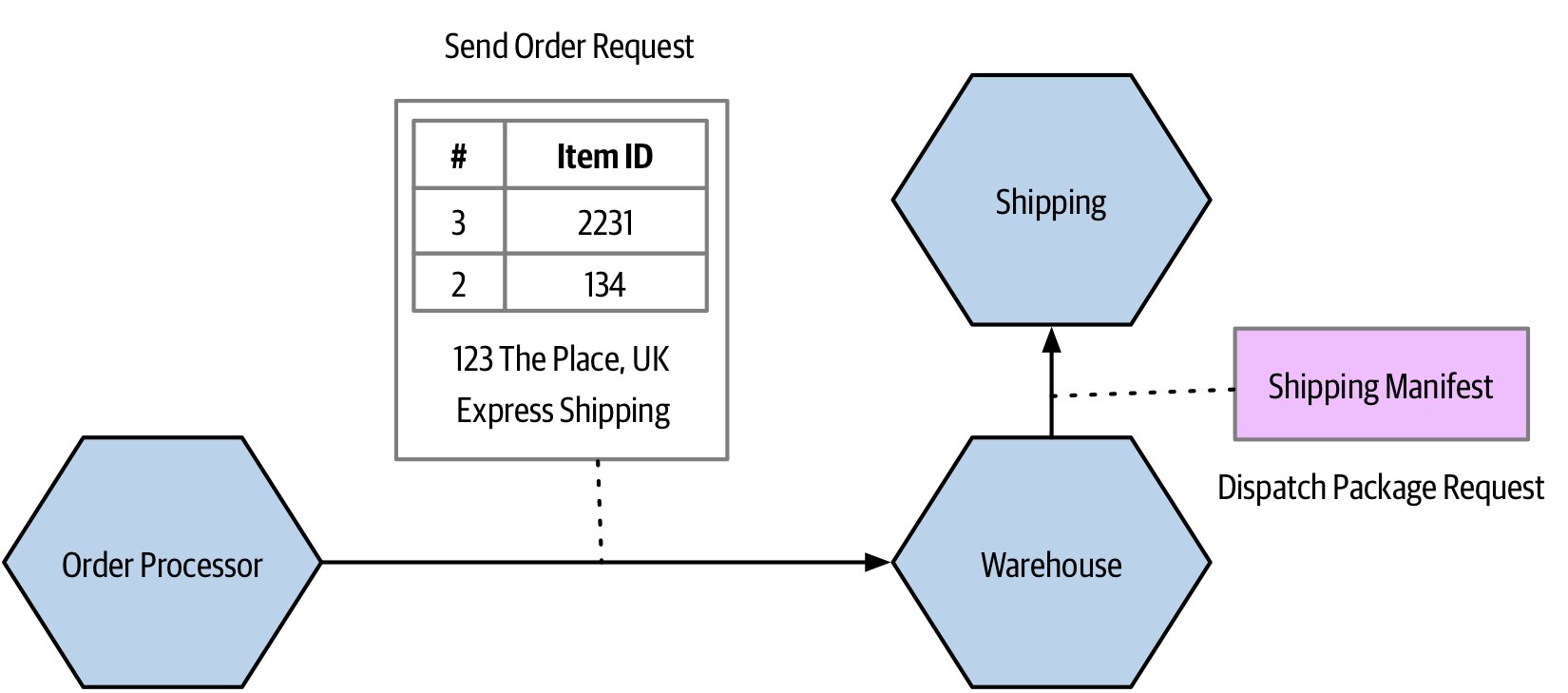
Figure 2.6:將 Shipping Manifest 的需求對 Order Processor 隱藏起來
3. 共用耦合(Common Coupling)#
兩個以上服務共享同一份資料(最常見:共享資料庫;其他形式包含共享記憶體、共享檔案系統)。
- 結構變更會同時影響所有消費者
- 共享資料很難演進
- 靜態參考資料(國家清單、貨幣代碼)通常還能接受
- 共寫共讀(讀寫操作交錯)就很危險
- 還隱含資源競爭問題:多個服務查詢同一資料庫可能拖垮共享資源
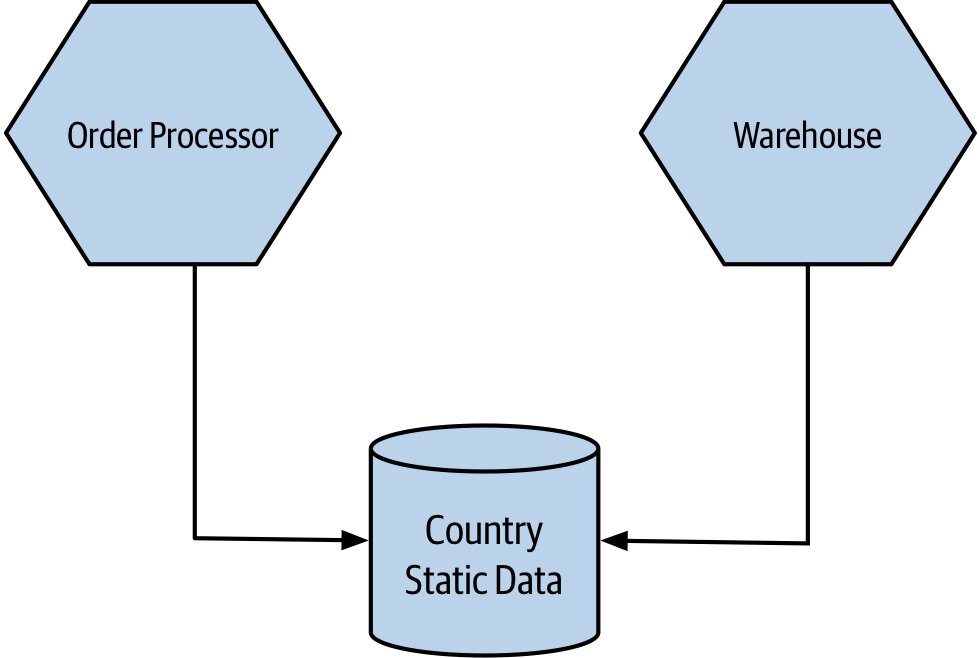
Figure 2.7:多個服務從同一資料庫存取共享的靜態參考資料
若
Order Processor與Warehouse都寫入共同的訂單表,誰負責維護有效的狀態轉換?這正是共用耦合的核心問題。
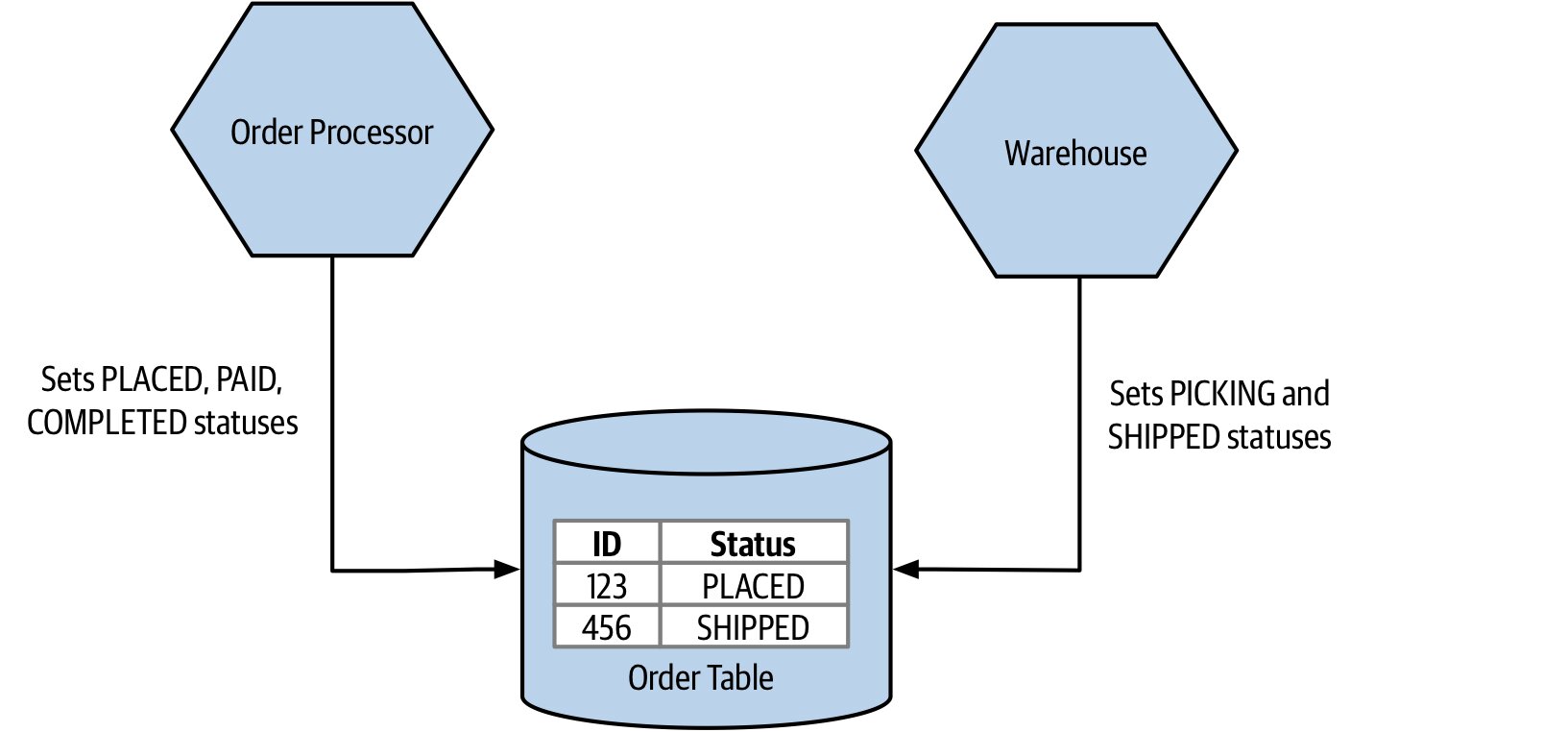
Figure 2.8:Order Processor 與 Warehouse 同時更新訂單造成的共用耦合
正確做法:讓單一服務(如 Order 服務)成為訂單狀態的唯一真相來源(source of truth)。其他服務以「請求」的形式提出狀態變更,由 Order 服務基於有限狀態機(finite state machine)決定接受或拒絕(例如禁止從 PLACED 直跳到 COMPLETED)。
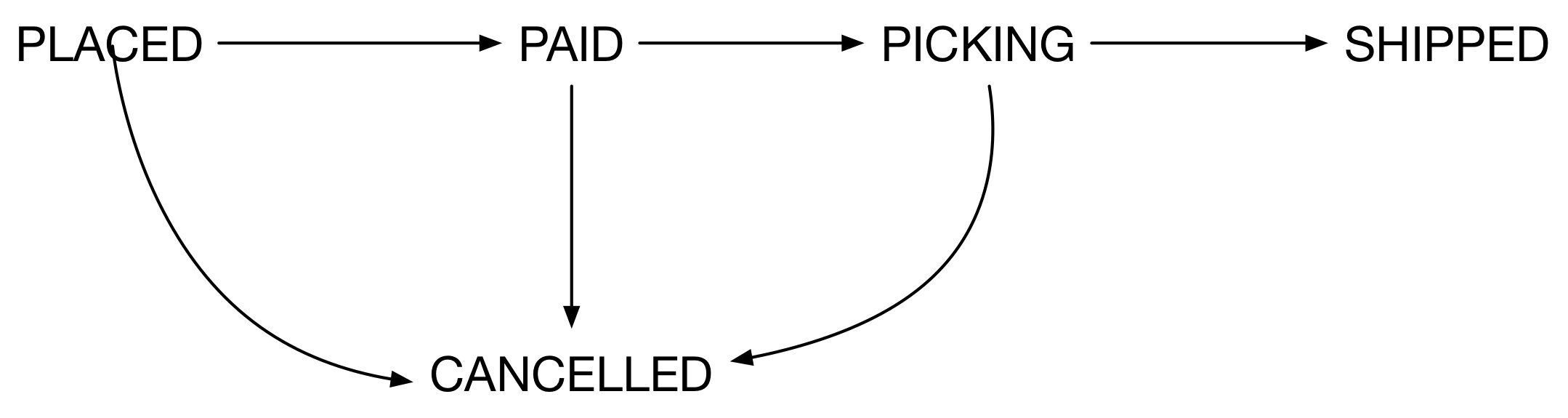
Figure 2.9:MusicCorp 訂單合法狀態轉換的概觀
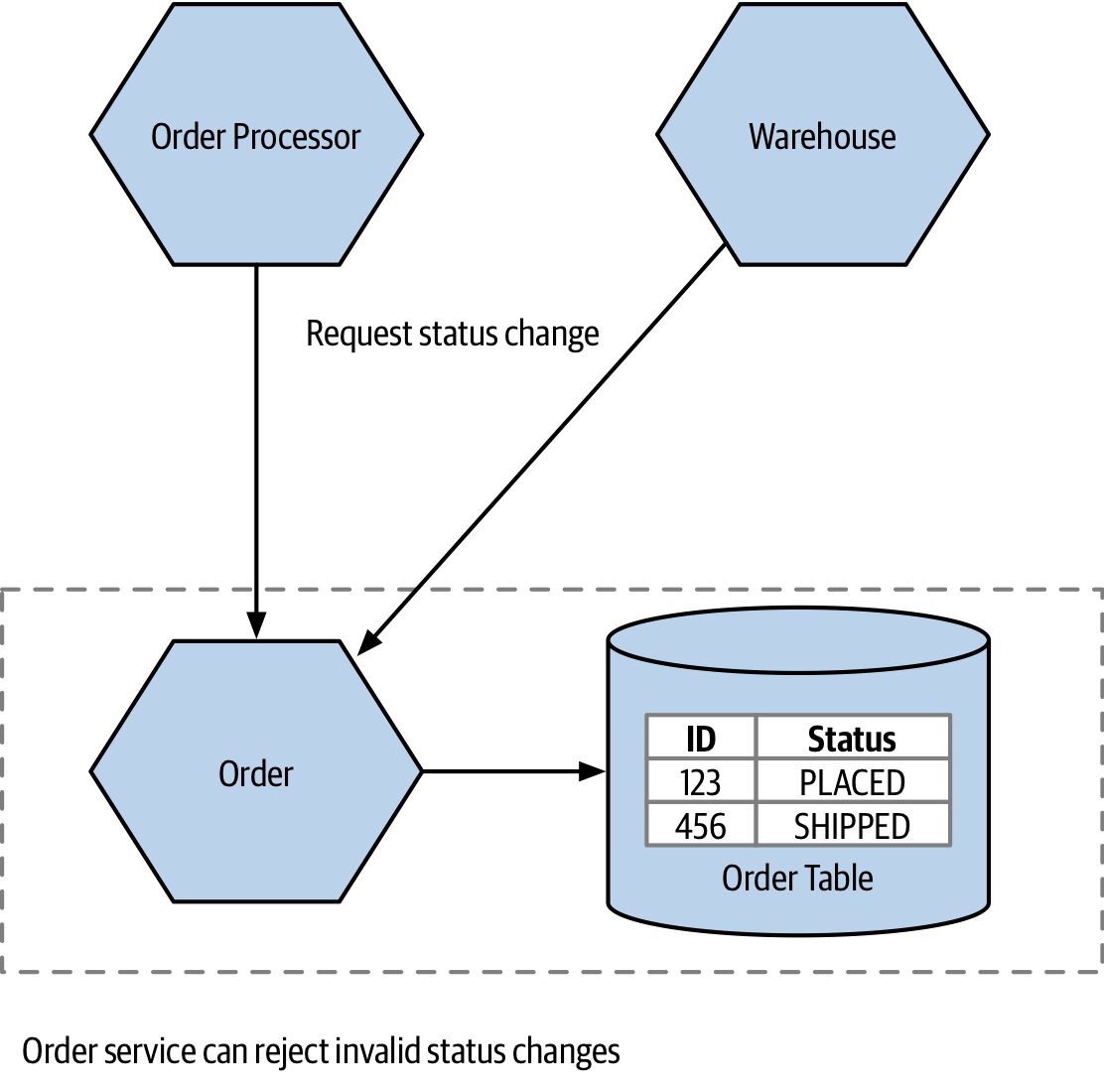
Figure 2.10:由 Order 服務統一決定狀態變更的可接受性
若一個微服務看起來只是資料庫 CRUD 操作的薄殼,代表它的內聚很弱、耦合很緊——應該屬於它的邏輯,被擠到別處去了。
4. 內容耦合(Content Coupling,又稱病態耦合)#
上游服務直接深入下游內部、修改其狀態(最常見:直接寫對方的資料庫)。比共用耦合更糟,因為:
- 共用耦合至少還承認在用「外部共享資源」;內容耦合則完全失去所有權的清晰邊界
- 資料庫結構變成隱性契約
- 資訊隱藏完全失效
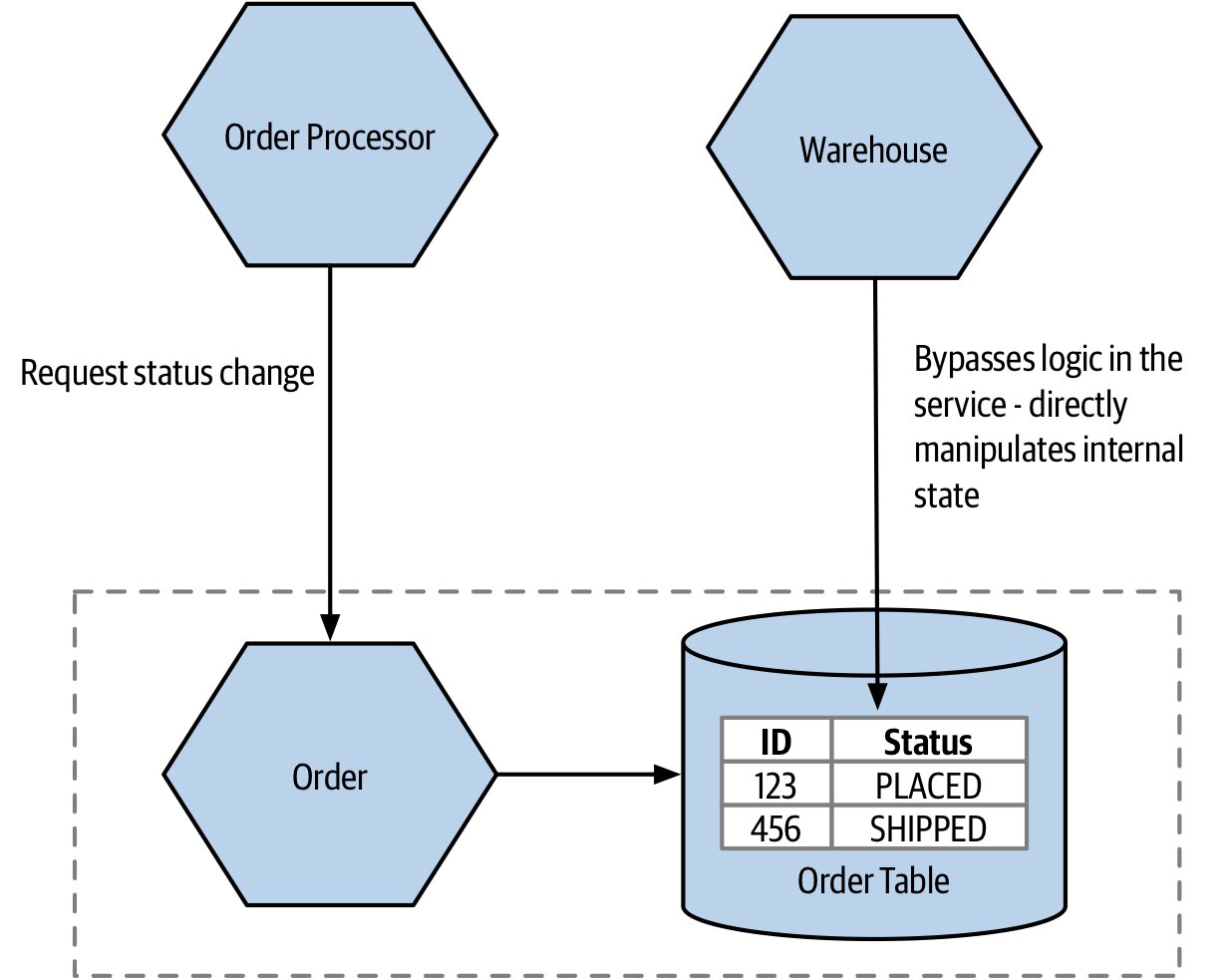
Figure 2.11:Warehouse 直接存取 Order 內部資料的內容耦合
一旦允許外部直接存取你的資料庫,資料庫就成了你對外契約的一部分——而你甚至不知道哪些欄位可以改。避免內容耦合。
領域分解之外的選擇#
領域驅動是首選,但不是唯一。以下因素可作為輔助或主要驅動:
變動性(Volatility)#
- 把變動最頻繁的部分抽出來
- 適合「縮短上市時間(time to market)」為主要目標的場景
- 切忌把它推到極端(如 Bimodal IT)——避免把難改的東西丟進「穩定區」逃避
作者反對 Gartner 提出的雙模 IT(Bimodal IT):把系統分成「Mode 1(記錄系統)」與「Mode 2(創新系統)」。實務上,數位轉型常需要兩者一起變動,這種分類往往演變成「慢」與「更慢」。
資料(Data)#
- 個資(Personally Identifiable Information, PII)、PCI 信用卡資料等需嚴格管控的資料應隔離
- PaymentCo 案例:把處理完整信用卡資料的服務放進「紅區(red zone)」(需 PCI Level 1 稽核),其他服務在「綠區(green zone)」豁免稽核
- 關鍵:信用卡資料絕對不能流到綠區,否則隔離失效
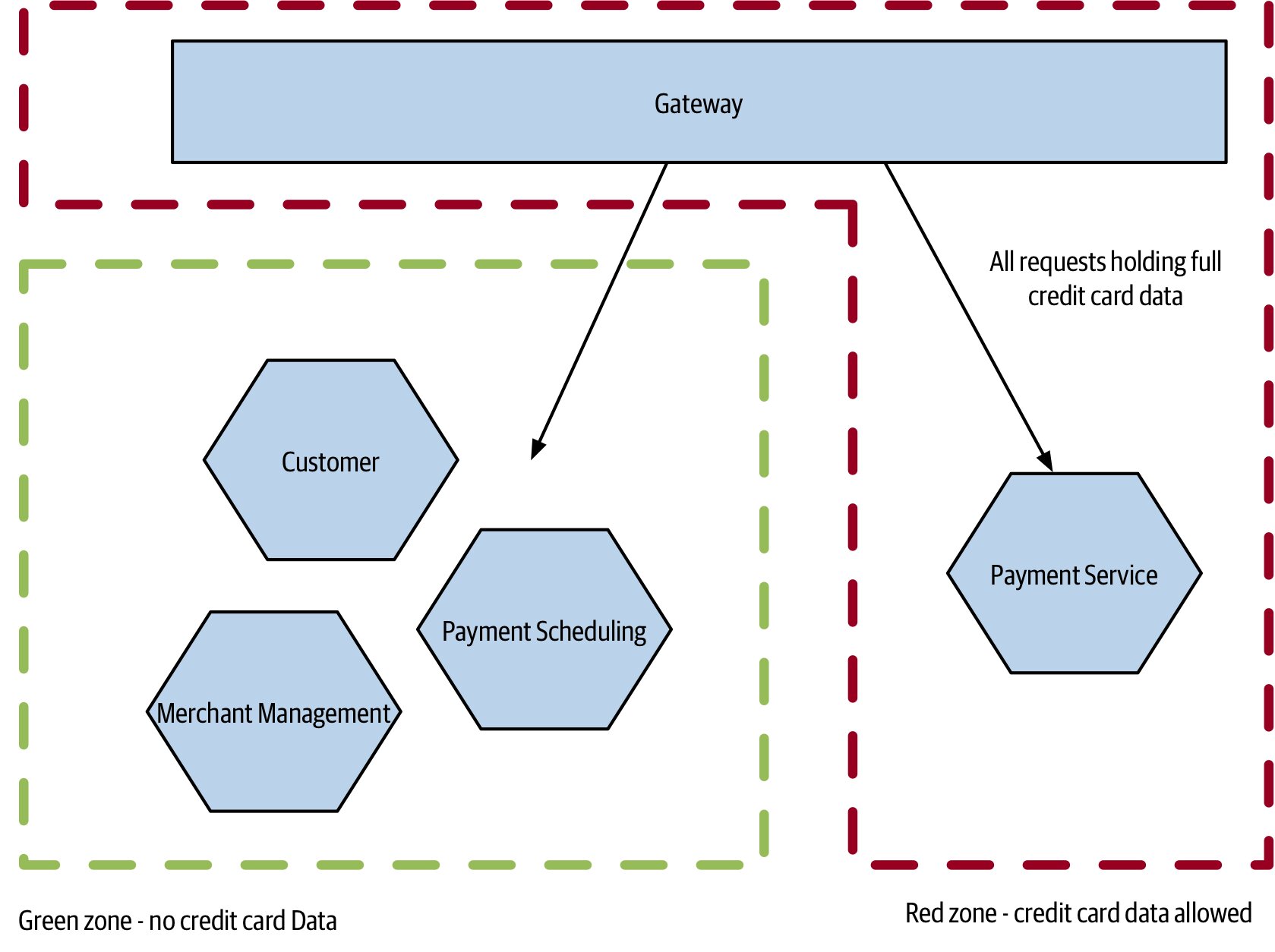
Figure 2.12:PaymentCo 以信用卡處理範圍切割服務以縮減 PCI 稽核範圍
技術(Technology)#
- 不同部分需要不同執行環境(如部分功能用 Rust 換取效能)
- 但不可變成傳統三層式那樣以技術切水平層
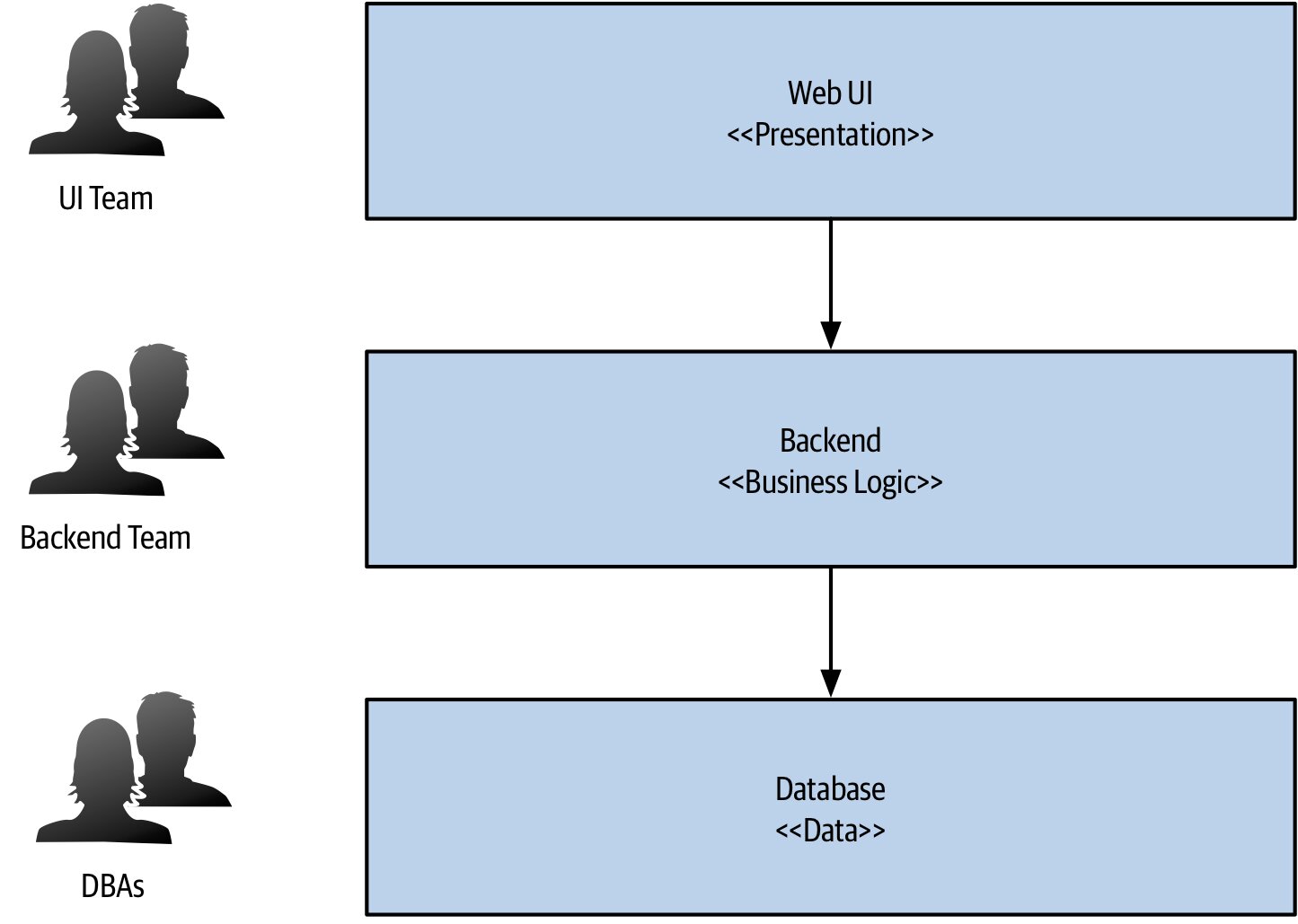
Figure 2.13:傳統三層式架構常受技術邊界驅動
組織(Organizational)#
- 康威定律已決定一切:跨多隊共擁的服務注定低效
- 切記:要做的是垂直切片(業務功能的端到端切片),而非水平切片(技術層)
- 加州反例:客戶把系統按地理切,前端留加州、後端 RPC 倉儲層搬到巴西,結果兩邊每次都要一起改、介面 chatty 又脆弱——作者稱之「洋蔥架構(onion architecture)」,每剝一層都讓人想哭
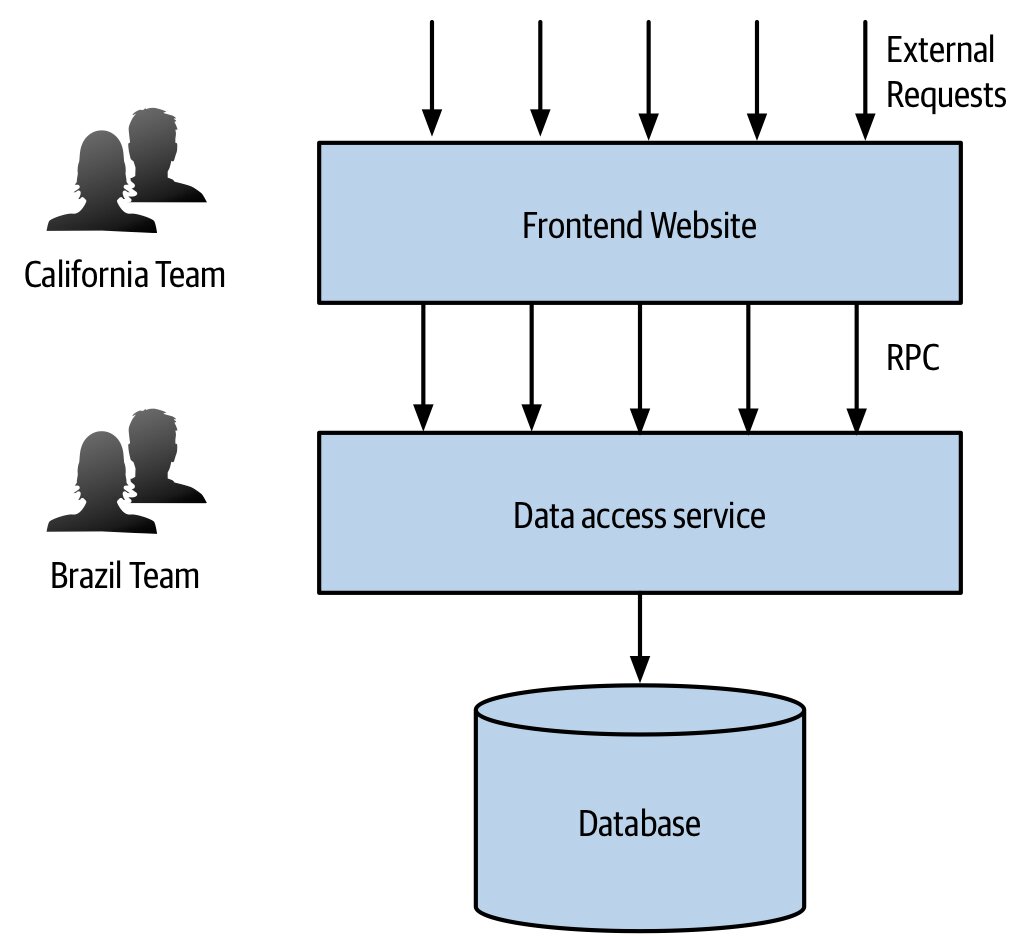
Figure 2.14:服務邊界被技術接縫切開的反例
微服務內部分層(layering inside)OK,但用層當作微服務或團隊所有權的邊界(layering outside)不行。
不同目的,不同驅動#
微服務不是目的,採用它必須是出於有意識的決策,要解決明確的問題。「不同的目的,導致不同的驅動因素」——你的目標決定哪一種分解方式最合適。
實務上常混用模型(mixing models):以領域為主,但若 Warehouse 內部一部分要 C++、另一部分要 Kotlin,就再依技術切。固守單一規則只會讓你變成教條派。
領域驅動設計(DDD)的最小集合#
領域驅動設計(Domain-Driven Design, DDD)由 Eric Evans 提出,全貌請見其著作;想看實作可參考 Vaughn Vernon 的《Implementing Domain-Driven Design》。本節僅整理在微服務脈絡下最常用的幾個概念。
通用語言(Ubiquitous Language)#
程式碼中應使用領域使用者真正在用的語言。
- 反例:作者在某全球銀行做企業流動性(corporate liquidity)專案,產品經理談的是「haircut」「end-of-day sweep」,但程式碼裡只有抽象的「arrangement」(號稱「IBM 銀行模型」可表達任何銀行操作)。每次溝通都要翻譯,業務分析師疲於奔命
- 把真實業務語言寫進程式碼,新進開發者拿到使用者撰寫的故事卡,能直接理解並動手
聚合(Aggregate)#
聚合是真實領域概念的代表(Order、Invoice、Stock Item 等)。
- 通常具有生命週期,可實作為狀態機(state machine)
- 應作為自包含單位處理:狀態與狀態轉換邏輯放在一起
- 一個聚合由一個微服務管理(單一微服務可管多個聚合)
- 外部請求變更聚合時,聚合應有權拒絕——理想實作中讓非法狀態轉換根本不可能發生
- 跨服務聚合關係可用 URI 等識別字參照
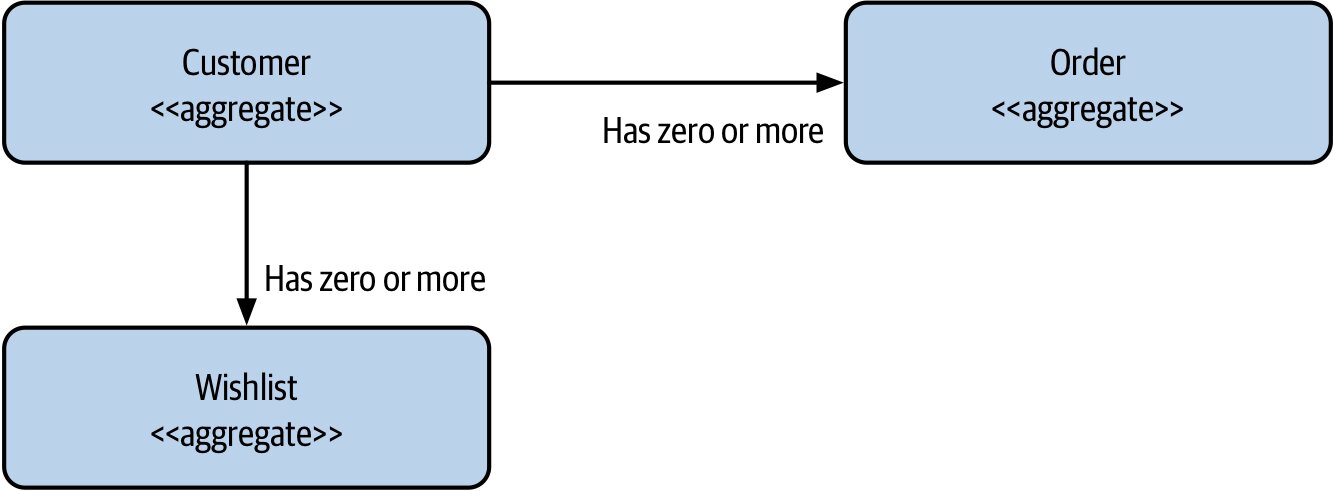
Figure 2.15:一個 Customer 聚合可關聯多個 Order 或 Wishlist 聚合
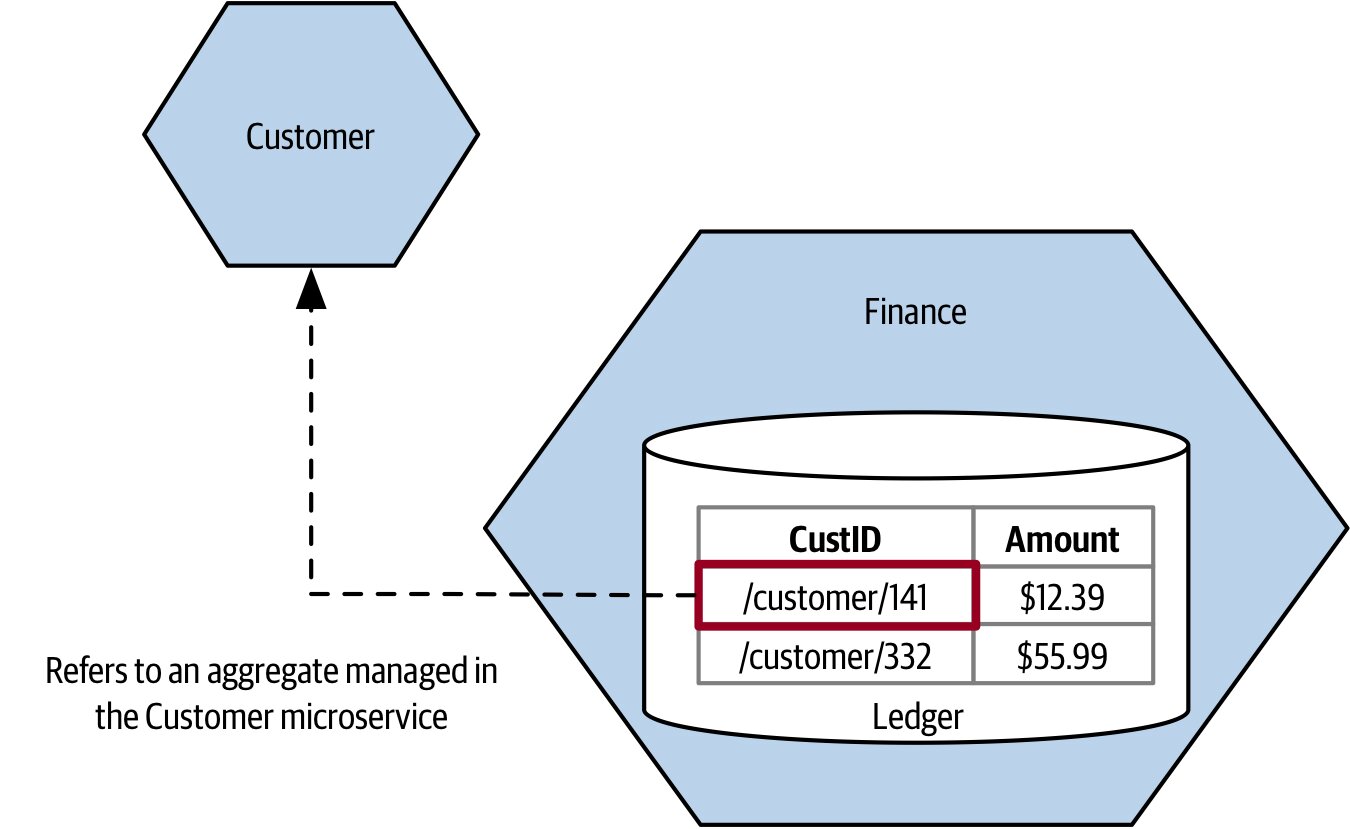
Figure 2.16:跨微服務的聚合關聯實作方式
限界上下文(Bounded Context)#
限界上下文通常對應到組織內較大的邊界,內部承擔明確的責任。
- 隱藏實作細節:倉儲部用什麼堆高機,與財務部無關
- 包含一或多個聚合,部分聚合對外暴露、部分純粹內部使用
- **共享模型(shared models)**可在不同上下文有不同名稱與意義
- 例如:在財務部叫
customer,在倉儲叫recipient(同一人在兩個情境扮演不同角色)
- 例如:在財務部叫
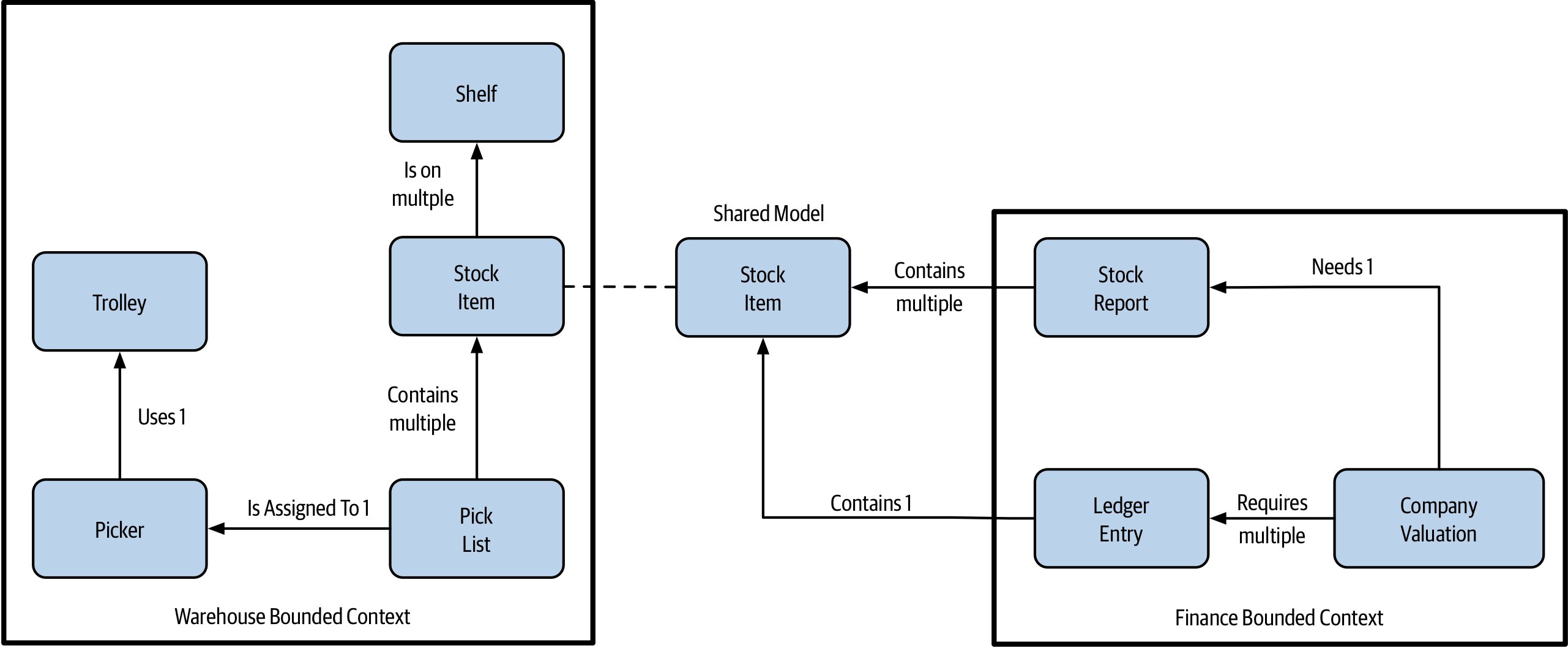
Figure 2.17:財務部與倉儲共享但意義不同的模型
- 對外暴露的
Stock Item可以只包含數量,倉儲內部則保留貨架位置;命名可改成Stock Count以區分內外
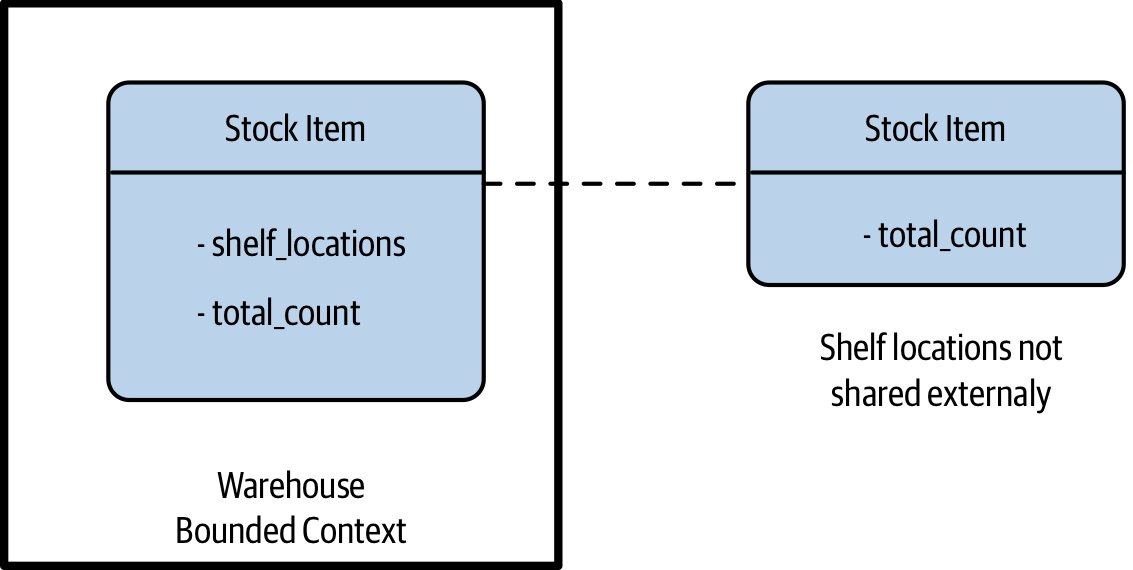
Figure 2.18:共享模型可選擇隱藏不應對外揭露的資訊
聚合與限界上下文如何對應到微服務?#
- 起步階段:以整個限界上下文作為一個微服務,數量少、好管理
- 熟悉之後:再沿著聚合邊界把大服務拆小
套娃結構:Turtles All the Way Down#
限界上下文內部可以再切出更細的限界上下文。例如倉儲可進一步分成「訂單揀貨」「庫存管理」「進貨」。
內部拆分可以對外隱藏:對外仍呈現為單一
Warehouse微服務,內部則拆成Inventory、Shipping。這也是資訊隱藏的延伸——內部結構未來再變動,消費者不需要知道。
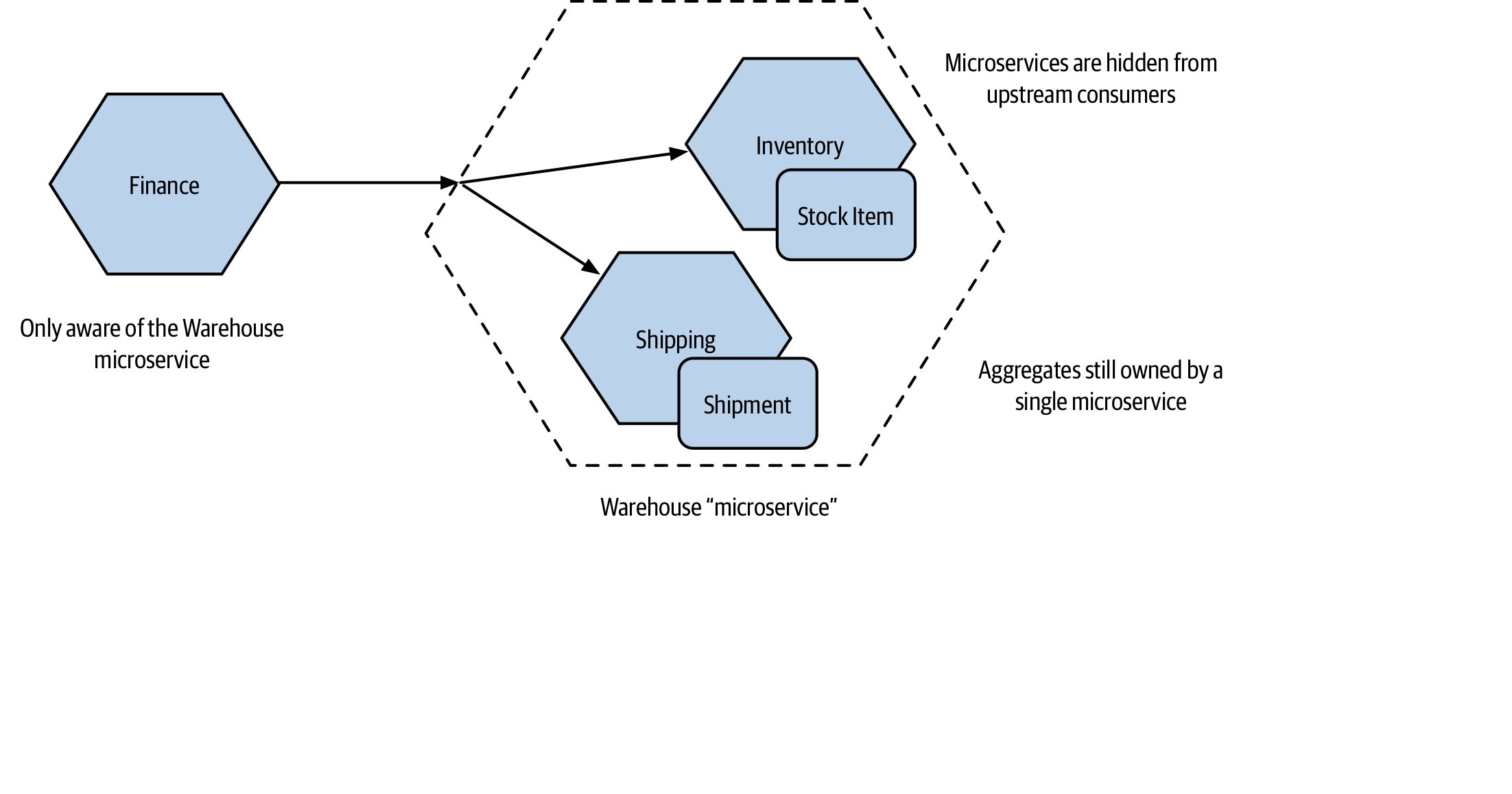
Figure 2.19:Warehouse 內部進一步拆成 Inventory 與 Shipping 微服務
這種套娃結構同時也是測試上的利器:對外只 stub 粗顆粒 API,內部多個服務可一起跑端到端測試。
過早分解的危險#
ThoughtWorks 的 SnapCI 案例:團隊本來就熟悉 CD 工具領域(曾做過 Go-CD),便信心滿滿地一開始就拆成多個微服務。幾個月後發現邊界完全錯誤,最後合回單體,又花一年才重新切分出穩定邊界。
從既有單體拆出微服務通常比一開始就用微服務容易得多——因為你已經摸清領域。
以業務概念溝通#
服務間的訊息也應使用業務語言,而非技術語言。可以把跨服務的訊息想像成組織內傳遞的「表單」。
事件風暴(Event Storming)#
由 Alberto Brandolini 提出的協作式工作坊,用來共同建構領域模型。
重點是讓技術與非技術利害關係人一起在同一空間建模,避免架構師關門造車。
後勤準備#
- 把所有領域代表(使用者、領域專家、產品負責人)找到同一個空間(疫情前是實體、疫情後可能是線上)
- 提供大牆面或大張紙,方便貼便利貼
- Brandolini 建議拿走椅子,逼大家站起來——背痛者可能無法照辦
流程概要#
- 步驟 1:找出領域事件(domain events)(橘色便利貼)
- 系統中真正發生的事實,例如「Order Placed」「Payment Received」
- 步驟 2:找出指令(commands)(藍色便利貼)
- 由人類做出、會引發事件的決定,協助辨識系統邊界與關鍵角色
- 此階段技術人應「聽」而非主導,避免既有實作扭曲對領域的認知
- 步驟 3:辨識聚合(黃色便利貼)
- 從事件中找名詞——「Order Placed」中的 Order 就是潛在聚合
- 把相關事件與指令圍繞聚合排列
- 步驟 4:聚合分群成限界上下文
- 通常會貼合組織結構
這個方法產出的領域模型既可拿來做事件驅動系統(event-driven),也可拿來實作 request/response 系統。
小結#
- 好的微服務邊界 = 強內聚 + 鬆耦合 + 穩定
- 領域是首選分解依據,但不是唯一;變動性、資料、技術、組織都可能是合理因素
- DDD 的聚合與限界上下文,是把領域對應到服務最有效的工具
- 起步先粗、再逐步拆細;對既有單體做拆解通常比從零開始用微服務更安全
- 別忘了,微服務本身不是目的,解決真正的問題才是