把理論放進案例#
Chapter 12 證明 balanced coupling 是貫穿所有抽象層級的自我相似原則。本章透過八個案例,從微服務一路演示到單一方法,看 balanced coupling 模型如何影響設計決策。
案例都圍繞 WolfDesk 系統,特別是
Support Case Management(SCM)這個核心子領域服務。核心子領域 → 高易變性,是後續分析的前提。
Microservices#
Case 1:事件洩漏過量知識#
Support Case Management 採用 event sourcing 實作核心子領域,所有狀態轉換都是事件。團隊把所有內部事件公開讓其他微服務訂閱,例如 Support Autopilot(用 ML 訓練自動回覆)。

Figure 13.1:Support Autopilot 訂閱 SCM 發出的所有事件
{ "eventType": "CaseCreated", ... },
{ "eventType": "CaseAssigned", ... },
{ "eventType": "CaseEscalated", ... },
{ "eventType": "CaseResolved", ... }一段時間後,每次 SCM 演化事件模型,
Support Autopilot都得協調修改——產生團隊間的摩擦。原因:SCM 是 core(高易變性)+ 跨團隊(高距離)+ 暴露內部事件模型 = model coupling。雖然 model 屬於整合強度光譜的中下段,但搭上「高易變 + 高距離」就不平衡了。此外,正確設計的微服務應為 bounded context——模型應封裝在 context 內,不該洩漏。
修正:定義整合專用事件#

Figure 13.2:SCM 改以 public/integration events 對外整合
兩個團隊共同設計給 Support Autopilot 用的整合事件:把所需資訊集中在單一事件結構:
{
"caseId": "CASE2101",
"caseVersion": 10,
"createdOn": "...",
"lastModifiedOn": "...",
"customerId": "CUST52",
"messages": [...],
"status": "RESOLVED",
"wasReopened": true,
"isEscalated": true,
"agent": "AGNT009",
"prevAgents": ["AGNT007"]
}SCM 內部仍用 private events 管理生命週期;對外則發 public events 作為整合契約。整合強度從 model coupling 降到 contract coupling,補償了高易變性 + 高距離。
Case 2:「夠好」的整合#
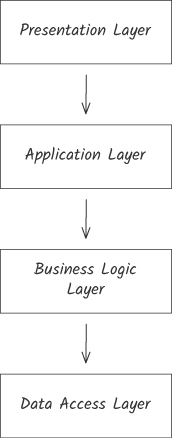
Figure 13.3:Desks 將排班變更以事件發布給 Distribution
Desks 微服務管理 help desk 與 agent 排班,是 supporting 子領域。Distribution 訂閱 Desks 發出的排班事件,事件結構直接反映 Desks 內部模型——也就是 model coupling。
整合強度與距離跟 Case 1 完全一樣,但這個設計沒有出問題。 差別在易變性:
Desks是 supporting 子領域、低易變性,補償了高距離 + model coupling。這是 balanced coupling 的核心要旨——單看「介面類型」無法判斷設計好壞,必須三維一起評估。
Architectural Patterns(聚焦 SCM 服務內部)#
Case 3:從分層到垂直切片#
初版 SCM 採用分層架構(presentation / application / business logic / data access)。
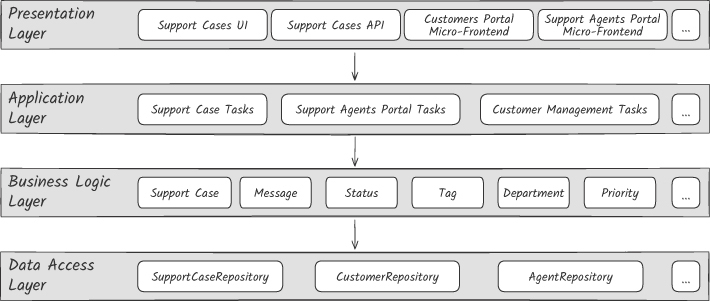
Figure 13.4:分層架構以技術職責組織元件
問題:實作任何功能都要動四層 → 跨層 functional coupling;同層內元件彼此關聯薄弱 → 同層內 local complexity。
從 SCM 服務的視角:層 = 高強度 + 高距離 → global complexity;層內 = 低強度 + 低距離 → local complexity。
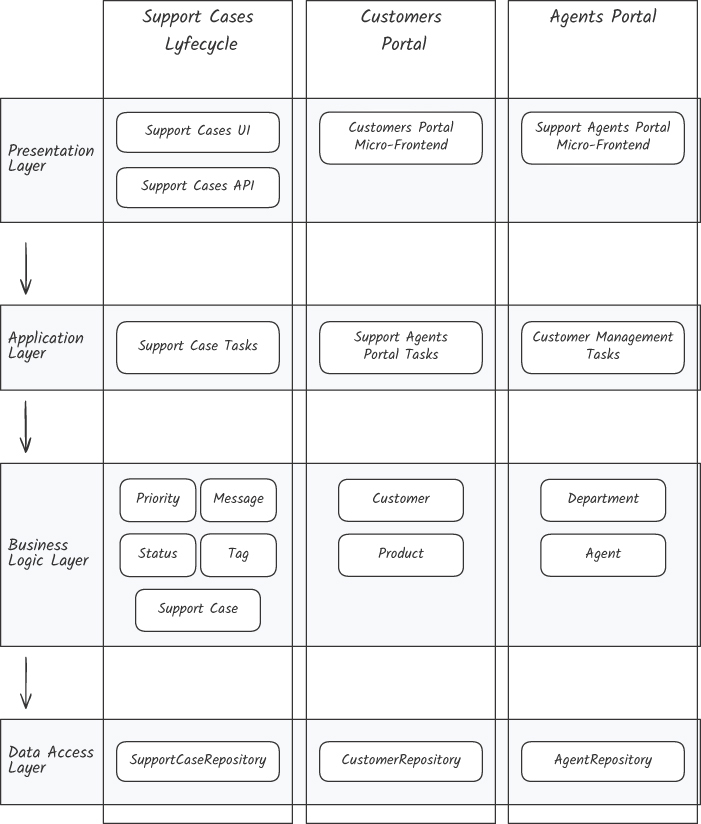
Figure 13.5:以技術職責為中心的架構容易累積複雜度
修正:垂直切片架構#
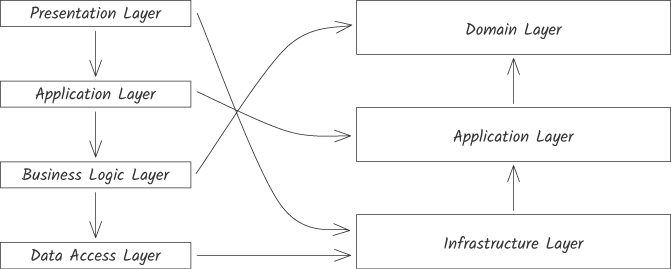
Figure 13.6:垂直切片架構
切片以「業務功能」為組織原則:每個 vertical slice 內部再分層。
結果:
- 不同切片之間 → 高距離 + 低強度(每片各自獨立)
- 同一切片內 → 高強度(功能耦合)+ 低距離
Vertical slice 也是 Chapter 12 所說的「抽象創新」——它創造了一個新的語意層級,讓人用「功能」而非「技術角色」討論服務內部。
Case 4:分層 → Ports & Adapters#
即使切了 vertical slice,Support Cases Lifecycle 切片仍有問題:domain 層為了下層 data access 的設計被迫了解過多細節(依賴向下,知識卻反向流回 domain)。
修正:依賴反轉(hexagonal / ports and adapters)#
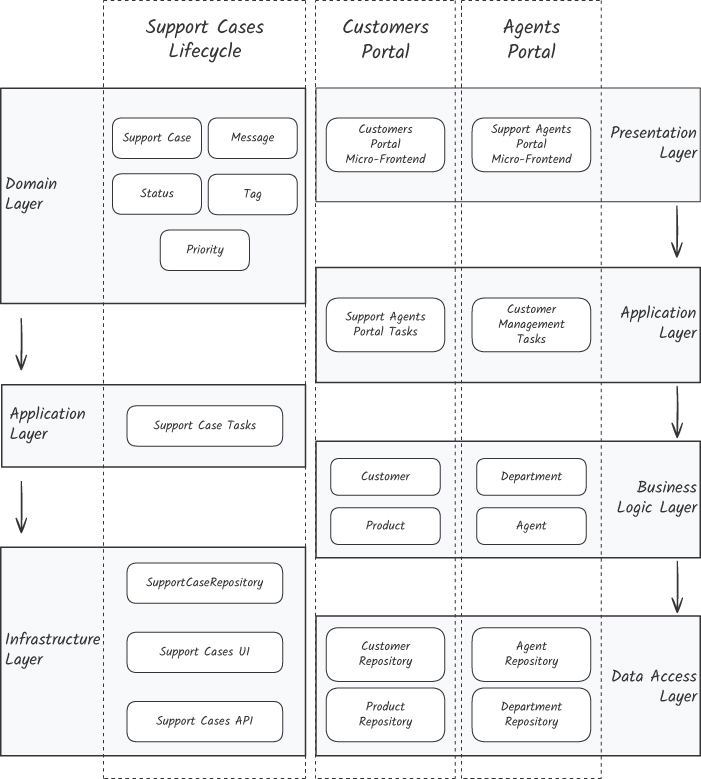
Figure 13.7:從分層架構遷移到 ports and adapters
業務邏輯 + 應用邏輯定義 ports(介面);infrastructure 提供 adapters(實作)。
namespace WolfDesk.SCM.CustomerPortal.Domain {
interface IProductRepository {
fun load(id: ProductId): Product
fun update(product: Product)
fun findAll(): List<Product>
fun findByStatus(status: ProductStatus): List<Product>
}
}
namespace WolfDesk.SCM.CustomerPortal.Infrastructure {
class PostgresProductRepository : IProductRepository { ... }
}兩個維度的耦合都被優化:
- 整合強度:domain 不再從 infrastructure 吸收任何知識
- inferred volatility 被切斷:domain 不再被 infrastructure 的易變性「傳染」
- 同時,介面(ports)作為整合契約 → strength 從 functional 降到 model / contract,距離也被「拉開」(因為依賴反轉)
不同 vertical slice 可以選用不同的架構模式——這也是 vertical slice 的彈性。
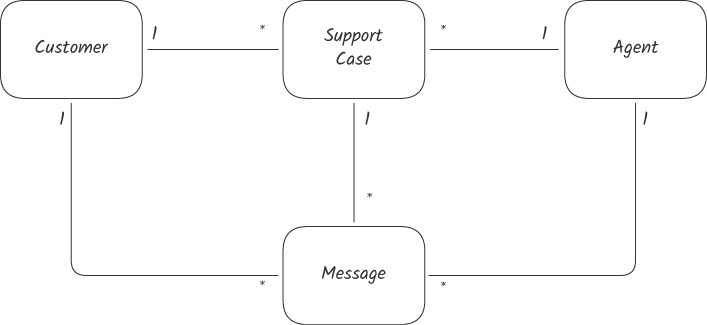
Figure 13.8:垂直切片架構讓每個切片自選模式
Business Objects#
Case 5:Entities 與 Aggregate#
最初 SupportCase、Message、Customer、Agent 之間都是雙向 one-to-many,搭配 ORM 提供「任何物件都能在同一 transaction 提交」的彈性。
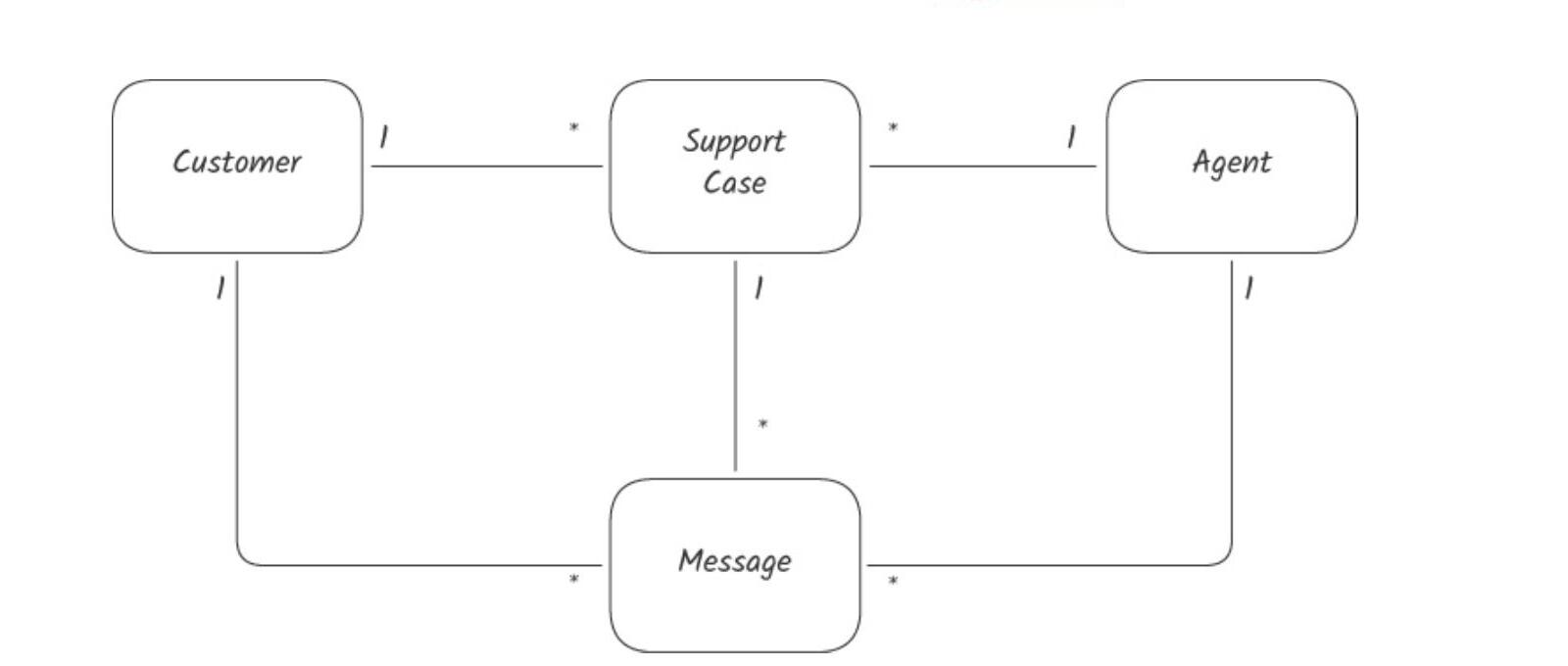
Figure 13.9: SupportCase、Customer、Agent、Message 四個類別的關係
class SupportCase {
private var openedBy: Customer
private var assignedAgent: Agent
private val messages: MutableList<Message>
}
class Customer {
private val openedCases: MutableList<SupportCase>
}
class Agent {
private val assignedCases: MutableList<SupportCase>
}兩個問題:
- 工程師「過度走訪」物件圖,引發效能問題
- 「能在同一 transaction 提交」也代表「可以分開提交」——例如「在 SLA 時間內未回覆才能升級」這個應該是原子操作的規則,被分成兩步執行時,會被剛好擠進來的回覆 message 影響
整合強度分析:
SupportAgent↔Customer↔SupportCase之間沒有業務上的 transactional 要求 → 不該允許 transactional couplingSupportCase↔Message之間有 transactional 要求 → 設計應該強制它
修正:DDD Aggregate#
class SupportCase {
private val openedBy: CustomerId
private val assignedAgent: AgentId
private val messages: MutableList<Message>
}
class Message {
private val customer: CustomerId
private val agent: AgentId
}Aggregate 把功能耦合(transactional)的實體拉近距離,把弱耦合的實體推遠(只用 ID 引用)。
這恰好對應 balanced coupling:強度高 → 距離低;強度低 → 距離高。
Case 6:以「功能」而非「技術角色」組織程式碼#
最初的目錄結構:
WolfDesk
└── SupportCaseManagement
└── SupportCases
└── Domain
├── Entities/
│ ├── SupportCase.cs
│ ├── Message.cs
│ ├── Priority.cs
│ ├── Status.cs
│ ├── MessageBody.cs
│ └── Recipient.cs
├── Events/
│ ├── CaseInitialized.cs
│ ├── MessageReceived.cs
│ ├── CaseResolved.cs
│ └── CaseReopened.cs
├── Factories/
│ ├── SupportCaseFactory.cs
│ └── MessageFactory.cs
└── Repositories/
└── ISupportCaseRepository.cs同資料夾內的檔案彼此不太一起變,反而要連動修改的檔案分散在多個資料夾——典型的「低強度 + 低距離 = local complexity」與「高強度 + 高距離 = global complexity」並存。
修正:依功能組織#
WolfDesk
└── SupportCaseManagement
└── Domain
└── SupportCases
├── Events/
│ ├── CaseInitialized.cs
│ ├── CaseResolved.cs
│ └── CaseReopened.cs
├── ISupportCaseRepository.cs
├── SupportCase.cs
├── Status.cs
├── Priority.cs
└── Messages/
├── Message.cs
├── MessageBody.cs
├── MessageFactory.cs
├── MessageReceived.cs
└── Recipient.cs把功能耦合的檔案拉近、無關的檔案分開,同時降低 local 與 global complexity。
Methods#
Case 7:Divide and Conquer#
SupportCase 早期版本塞了無關的方法(送 email、SMS):
class SupportCase {
fun createCase(...) { }
fun assignAgent(...) { }
fun resolveCase(...) { }
fun logActivity(...) { }
fun scheduleFollowUp(...) { }
fun sendEmailNotification(...) { }
fun sendSMSNotification(...) { }
}導入 ports & adapters 後,notification 介面被抽到 domain layer,實作放在 infrastructure:
namespace WolfDesk.SCM.Domain.Cases {
interface INotificationProvider {
fun sendEmail(email: Email)
fun sendSMS(phone: PhoneNumber, message: SMS)
}
}但
sendEmail與sendSMS之間沒有任何共享知識——只是「都是通知」。把它們再切開,符合 Interface Segregation Principle:
namespace WolfDesk.SCM.Domain.Cases.Notifications {
interface IEmailNotificationProvider { fun send(email: Email) }
interface ISmsNotificationProvider { fun send(phone: PhoneNumber, message: SMS) }
}ISP 用 balanced coupling 重新表述:「沒有共享知識的方法之間,距離應該被拉開」。
Case 8:Code Smells#
class SupportCase {
fun trackCustomerEmail(email: Email, departments: IDepartmentRepository) {
val message = Message.fromEmail(email)
messages.append(message)
if (agentAssigned) {
val department = departments.getDepartment(...)
val sla = department.SLAs[priority]
replyDueDate = DateTime.Now.add(sla)
}
}
}步驟一:抽出方法#
if (agentAssigned) 那段邏輯與「處理新 email」毫無共享知識,且其他生命週期階段也可能用到——抽成獨立方法 setReplyDueDate。
步驟二:把 model coupling 降為 contract coupling#
抽出後仍有 department.SLAs[priority]——這是 model coupling(呼叫端知道 SLAs 是個字典)。改成方法呼叫:
val sla = department.getSLA(priority)介面從「暴露字典結構」變成「提供 GetSLA 方法」,呼叫端不再依賴
Department的內部實作——還順便讓Department有空間處理「找不到 SLA 該怎麼辦」這類業務問題。
步驟三:抽出 Domain Service#
進一步問:SupportCase 真的需要知道「SLA 是依部門算的」嗎?若未來規則改成依輪班計算呢?
class SupportCase {
private fun setReplyDueDate(slaService: CalcSLA) {
replyDueDate = slaService.calcDueDate(...)
}
}把 SLA 計算邏輯抽成 Domain Service——
SupportCase只專注於支援案件的生命週期。distance 拉開,知識被進一步封裝。
重點整理#
本章刻意「重複」——不論是微服務、垂直切片、ports & adapters、aggregate、目錄結構、方法重構,每個案例都在做同一件事:
- 強度高 → 縮短距離
- 強度低 → 拉開距離
- 易變性高 → 不容忍複雜度
這就是 balanced coupling 作為自我相似原則的證據——所有架構模式、設計模式、設計原則都共享同一條規律。
進一步思考#
可以試著用 balanced coupling 模型分析下列題材,會發現它們本質都在處理同一件事:
- Event-driven architecture、分散式系統
- DDD 的策略性與戰術性模式:open-host service、published language、anti-corruption layer、value objects、core/supporting 子領域的不同建模方式
- 設計原則:Dependency Inversion、Liskov Substitution、DRY、Law of Demeter
- Refactorings 與 code smells