為何要重新討論模組化#
「95% 的篇幅在歌頌模組化的好處,幾乎沒有人說該怎麼做到。」——Glenford Myers, 1979
四十多年過去,這段觀察仍然成立。模組化是好設計的基石,但儘管出現了無數新模式、新架構與方法論,多數軟體專案依然在追求模組化的路上跌跌撞撞。本章定義「什麼是模組」、「什麼樣的系統才算模組化」,並把模組化與耦合的關係串起來。
模組化(Modularity)#
模組化的概念並非軟體獨有,「module」這個詞早於軟體設計約 500 年就存在。核心定義是:由自包含單元(modules)組成的系統。但這跟 Chapter 1「系統就是元件的集合」有什麼差別?
模組化的核心目的是讓系統能演進(evolution)——對未來尚未明確的需求保留彈性。模組化讓系統有機會以合理成本回應變化,而不會被當下需求綁死。
模組化還是個認知工具:把系統從「黑盒子」變成「一群各司其職的元件」,讓人能更清晰地理解系統如何運作。理解越深,修改、修錯、擴充的信心就越強。
模組(Module)#
「module」與「component」常被混用,但兩者不同:
- 系統由 元件(components) 組成
- 一個模組是元件,但不是所有元件都是模組
- 模組化的設計必須能透過組合、重組、替換模組來改變系統
生活中的模組範例#

Figure 4.1: 生活中的模組化系統範例
- LEGO 積木:每塊積木都是自足的單元,可以組成各式各樣的結構
- 可換鏡頭:攝影師不需要多台相機,靠換鏡頭就能適應不同拍攝條件
模組的三個基本屬性#
要描述模組,可以用三個屬性(Myers 1979):
| 屬性 | 反映什麼 | 資訊類型 |
|---|---|---|
| Function(功能) | 模組的目的 | 公開、明確 |
| Logic(邏輯) | 模組如何運作 | 隱藏於模組內部 |
| Context(脈絡) | 對使用環境的假設 | 公開但比 function 隱晦 |
設計模組時:
- Function 要在介面上清楚表達
- Logic 要被邊界隱藏起來
- Context 要讓使用者明白,否則環境變動時模組行為將出乎意料
LEGO 積木與相機鏡頭的對應#
以 LEGO 積木為例:
- Function:透過凸點與凹槽和其他積木連接
- Logic:選用足夠承重且能可靠連接的材料
- Context:玩具,要適合兒童;不適合拿來蓋真房子
以相機鏡頭為例:
- Function:捕捉特定光學特性的影像,定義可搭配哪些相機機身
- Logic:內部光學與機械的設計
- Context:支援的相機型號範圍、是否支援自動對焦等
軟體模組#
「軟體模組」是個含糊的詞——是 library?package?object?service?常見的「邏輯邊界 vs 物理邊界」之分其實並不準確。回到原始定義:
- David Parnas (1971):模組是責任分配(responsibility assignment),不是程式語句的隨意切割
- Yourdon & Constantine (1975):模組是「具有彙總識別碼的、由邊界元素界定的、語法上連續的程式語句序列」
更精煉地說,模組需符合三條件(Myers 1979):
- 實作**自包含(self-contained)**的功能
- 該功能可被任何其他模組呼叫
- 實作有可能被獨立編譯(independently compiled)
邊界是「物理的」還是「邏輯的」並非重點。重點是它封裝了一份明確功能,且具有獨立編譯的潛力。 在這個定義下,service、library、namespace、package、object、class,甚至個別函式都可能是模組。
模組是層層巢套的——「It’s turtles all the way down」。微服務系統的微服務若是有效模組,那這些微服務內的 namespace、object、function 也可以各自是模組。
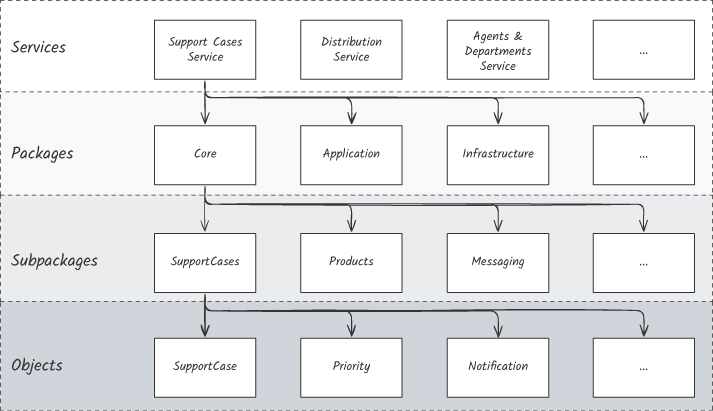
Figure 4.2: 階層式模組設計(層層巢套)
軟體模組的 Function、Logic、Context#
- Function:透過公開介面對外暴露
- Service:REST API 或 pub/sub 訊息
- Object:公開方法與成員
- Namespace / package:成員所實作的功能集合
- Function 本身:名稱與簽章
- Logic:實作功能所需的所有設計與程式碼,包括內部資料庫、訊息匯流排等基礎設施
- Context:執行環境的需求與假設
- 特定 runtime 版本
- CPU / memory / 網路頻寬要求
- 假設呼叫方已通過授權
有效模組:資訊隱藏#
任意把系統切成幾塊並不會自動帶來模組化。Parnas 在 1960 年代末就觀察到這個問題:
「他們希望(a)把切好的部分湊起來就會運作,(b)改動只會限制在單一模組內。但這兩件事都沒發生。原因是『分得很糟』。那些模組的介面非常複雜,幾乎每次改動都會影響到很多模組。」——David Parnas, 2023 年寫給作者的信
Parnas 提出資訊隱藏(information hiding) 作為指引:有效的模組會隱藏「決策」。當決策需要重新考量時,變更只會影響到「藏」住該決策的那個模組。
模組就是抽象(Abstraction)#
抽象的目的是「同等程度地代表多個事物」。例如「車」這個詞,不需要指定品牌、型號、顏色——刪去個別差異,保留共通本質。
抽象越廣,越穩定(共享細節越少 → 變動可能性越低)。
著名的 CustomerRepository 範例:
interface CustomerRepository {
fun load(id: CustomerId): Customer
fun save(customer: Customer)
fun findByName(name: Name): Collection<Customer>
fun findByPhone(phone: PhoneNumber): Collection<Customer>
}這個介面只關注「能做什麼」,背後可以是 RDB、document store,甚至是 polyglot persistence 的組合。即使不換 DB,對 findByName 內部查詢、新增索引、調整 schema 等變動,呼叫端也不該受影響。
Edsger Dijkstra (1972):「抽象的目的不是含糊,而是創造一個新的語意層級,讓人在那裡能絕對精確地溝通。」
例如把「car」抽象成「vehicle」可能太廣——除非你真的要納入機車與巴士。
深模組(Deep Modules)#
John Ousterhout 在 A Philosophy of Software Design 中提出視覺啟發法:把模組畫成矩形,底邊代表 function(介面),面積代表 logic(實作)。矩形越「深」,模組越能藏住知識。
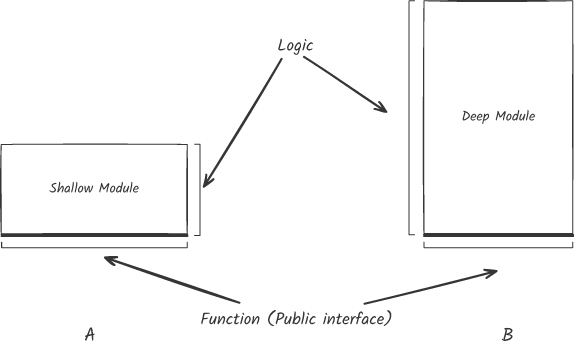
Figure 4.3: 淺模組(A)與深模組(B)對比
淺模組:function 與 logic 差不多大。極端例子:
fun addTwoNumbers(a: Int, b: Int) = a + b介面沒封裝任何複雜度,跟直接讀實作沒差別
深模組:用簡潔介面封裝大量複雜實作,呼叫端能在更高的語意層級推理系統
「深模組」也有極限。兩個都很深的模組若分別實作了同一個業務規則,當規則變動時兩處都要改——任一處沒同步就會引發不一致。模組化從來不容易。
模組化、複雜度與耦合#
模組化和複雜度都源自「知識在系統中如何分布」。
模組化從兩個方向控制複雜度:
- 消除意外性複雜度:避免設計不良造成的複雜
- 管理本質性複雜度:把不可消除的領域複雜性封裝在合適的模組內,避免它向系統其他部分蔓延
模組就是知識邊界。 模組的三個屬性對應三種知識:
- Function:明確對外暴露的知識
- Logic:藏在模組內的知識
- Context:模組對所處環境的知識
有效模組的設計目標:最大化封裝的知識,只暴露其他元件絕對需要的最小知識。
模組化 vs 複雜度:Big Ball of Mud#
模組化的反面是 Foote 與 Yoder (1997) 提出的「Big Ball of Mud」:
結構雜亂、四處蔓延、用膠帶與鐵線勉強拼湊的義大利麵程式碼叢林。資訊在系統中遠端元件之間任意共享,到了重要資訊都成全域或重複的程度。整體結構從未被良好定義過——若曾有過,也已被侵蝕到無法辨認。
可以把這個反模式翻譯成「無效抽象」的問題。無效抽象有兩種失敗:
- 包含過多細節:暴露不必要的資訊,造成意外性認知負擔,也讓抽象失去通用性
- 遺漏關鍵資訊:「leaking abstraction」——使用者必須了解底層實作才能正確使用,也是認知負擔的來源
封裝是雙面刃。封太多會讓模組難以使用,封太少又會讓底層細節滲出。
模組化也會「過頭」#
越是想「什麼變動都能容納」,系統越會變得難以使用。模組化沒有意義到讓 blog engine 變印表機驅動程式的程度。
設計模組時要避開兩個極端:
- 過於僵化 → 改不動
- 過於彈性 → 用不了
模組化應該聚焦在「合理的變動」。
預測「未來合理的變動」並不是精確的科學,而是基於當下的領域知識所做的押注(assumption is a bet against the future)。盡可能蒐集資訊、做出有根據的押注,是身為設計者的功課。
耦合在模組化中的角色#
模組化不能透過孤立檢視單一模組來評估,必須看模組之間的關係。Alan Kay 提醒過:物件導向真正的核心是 messaging,不是 classes。設計時別只盯著盒子,連線跟箭頭一樣重要。
耦合定義了「哪些知識會在元件之間流動」。不同的耦合方式會共享不同類型與不同數量的知識——有些把系統推向複雜,有些把系統推向模組化。
內聚(Cohesion):耦合的另一面#
內聚與耦合一同在 Yourdon & Constantine 的 Structured Design 中被提出:
- 內聚:模組內部元素「屬於彼此」的程度,反映模組責任的相關度
- 高內聚 = 單一明確的目的 → 容易理解、維護、強健
不少工程師把內聚稱為「good coupling」。本書也採取這個觀點:內聚本質上是耦合的另一種視角。Part II 會深入剖析耦合在系統中的多維展現,最終把這些洞見整合成引導模組化設計的框架。
重點整理#
設計模組時可以這樣自問:
- 我能在不揭露 logic 的情況下說清楚這個模組的 function 嗎?
- 這個模組的 context 是被明確說明,還是建立在容易遺忘的隱性假設上?
- 我有沒有為了「萬用」而讓模組變得難以使用?
- 模組之間「該共享」與「不該共享」的知識,分別是什麼?
下一部分會深入「耦合的維度」——強度(strength)、空間(space)、時間(time),逐步累積足夠的工具來實踐平衡耦合。