高德納的警語#
電腦科學家高德納(Donald Knuth)的名言,是本章的根基:
「程式設計師浪費了大量時間擔心程式中無關緊要部分的速度,這些對效率的執著反而在除錯與維護階段帶來嚴重副作用。我們應該在 97% 的時間裡忘掉小幅效率:過早最佳化是萬惡之源(premature optimization is the root of all evil)。」
高德納沒有反對所有最佳化——只反對過早的最佳化。何時最佳化、最佳化什麼,比是否最佳化更重要。
過早最佳化的六種樣貌#
最佳化的本質是用複雜度換效能。複雜度越高,bug 越多、維護越貴。在還沒掌握「真實使用情境、真實瓶頸」之前下手,往往得不償失。
1. 函式優化(Optimizing Code Functions)#
看到一個函式就忍不住要調校演算法。花了好幾小時研究,結果這函式整個專案只跑幾次。
2. 功能優化(Optimizing Features)#
明明一個 MVP 即可(例如把文字轉摩斯碼)卻硬要加文字轉語音、光訊號接收等功能,使用者根本不用。為不必要的功能優化,是雙重浪費。
3. 規劃過度(Optimizing Planning)#
陷在規劃裡無法跨出第一步。雖然規劃能避坑,但沒上線就拿不到真實回饋——你會永遠困在象牙塔裡。
4. 擴展性過早(Optimizing Scalability)#
預期百萬使用者就先設計分散式架構。事實是:
- 分散式系統複雜度高,可能花你好幾個月
- 多數專案根本長不到那規模
- 分散式反而降低擴展性(通訊與一致性開銷)
在你還沒有第一個使用者之前,不要為一百萬使用者擴展。
5. 測試過度(Optimizing Test Design)#
TDD 狂熱者堅持 100% 覆蓋率,連實驗性程式都要先寫測試。但有些函式(例如處理使用者自由輸入)唯一有意義的測試就是真人。為這類函式硬寫單元測試是浪費。
6. 物件導向過度建模(Optimizing OO World Building)#
寫個小遊戲就建立 Porsche → Car → Vehicle 多層繼承。每個 Porsche 都是 Car、每個 Car 都是 Vehicle——邏輯沒錯,但繼承堆疊讓未來的人讀不懂。先用最簡單的模型,需要才擴。
真實案例:Alice 的撲克記帳#
Alice、Bob、Carl 每週五打牌,需要記帳。Alice 寫了個小程式:
transactions = []
balances = {}
def transfer(sender, receiver, amount):
transactions.append((sender, receiver, amount))
balances[sender] = balances.get(sender, 0) - amount
balances[receiver] = balances.get(receiver, 0) + amount
def max_transaction():
return max(transactions, key=lambda x: x[2])Alice 的「優化」#
她發現 max_transaction() 每次呼叫都要遍歷整個 list,於是改成增量維護:
max_transaction = ('X', 'Y', float('-Inf'))
def transfer(sender, receiver, amount):
...
if amount > max_transaction[2]:
max_transaction = (sender, receiver, amount)數學上看似很美:1000 筆交易呼叫 1000 次 max,從 1,000,000 次比對降到 1,000 次。
但這是過早最佳化#
- 場景只有三個朋友、一晚數十筆交易,原版瞬間就跑完。
- 朋友們不會注意到差別。
- 但 Alice 接下來會被誘惑加入
min_transaction、avg_transaction、median_transaction、alice_max_transaction⋯⋯ 每多一個都增加 bug 機會。 - 萬一漏更新某個變數,可能讓 Alice 帳戶錯誤——朋友還可能懷疑她故意作弊。
如果哪天賭場真的找上門,那時候再優化也來得及。避免過早最佳化,才能把彈藥留到真正需要的時候。
六個效能調校原則#
原則 1:先測量,再改善(Measure First, Improve Second)#
沒測量就無法改善。
- 寫最直接、易讀的版本,這是 baseline
- 文件化測量結果(試算表)
- 替代方案能否打敗 baseline?打敗了它就成為新 baseline
- 沒打敗就丟掉
原則 2:帕雷托是王(Pareto Is King)#
效能瓶頸通常符合 80/20 分布。CPU 使用率往往集中在少數程序——關掉 Cortana 與 Search,CPU 負載立刻大降。
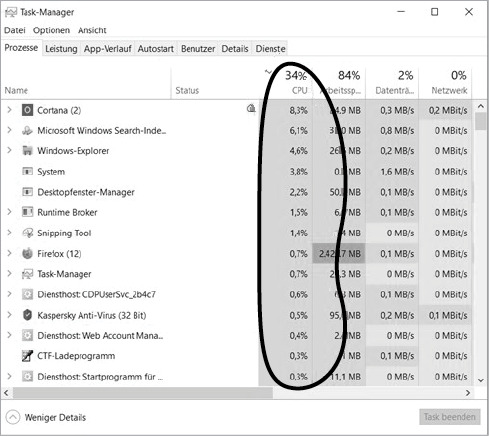
Figure 5-1: Windows 上不同應用對 CPU 的需求嚴重不均。
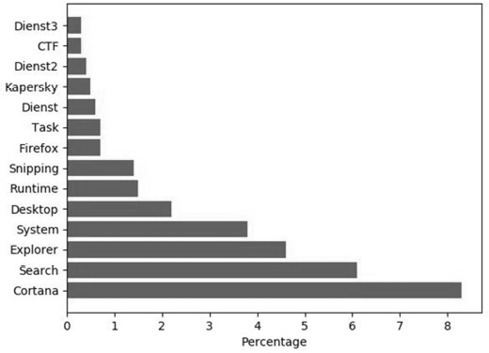
Figure 5-2: 各應用 CPU 使用率呈現典型的帕雷托分布。
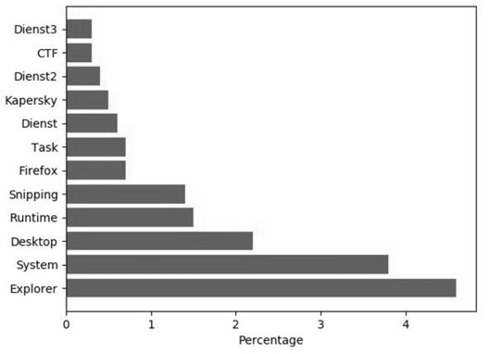
Figure 5-3: 關掉兩個最吃資源的應用後,新分布仍是帕雷托——瓶頸是分形的。
效能優化是**分形(fractal)**的:移除一個瓶頸後,下一個瓶頸冒出來。但每次先打最大的,CP 值最高。
原則 3:演算法優化最有效#
問自己:
- 有沒有更好的既有演算法(書、論文、Wikipedia)?
- 能不能調整現有演算法以適應你的特定問題?
- 資料結構能不能換?
- 用
set取代list做成員測試 - 用
dict取代 tuple 集合
- 用
例如金融應用中 calculate_ROI() 是瓶頸,可換用「最大利潤演算法(maximum profit algorithm)」大幅加速。
原則 4:快取萬歲(All Hail the Cache)#
有重複計算就快取。Fibonacci 是經典示範:
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)fib(n-1) 與 fib(n-2) 都會重算 fib(n-3)。加上快取:
cache = {}
def fib(n):
if n in cache:
return cache[n]
if n < 2:
return n
cache[n] = fib(n-1) + fib(n-2)
return cache[n]作者實測前 40 個 Fibonacci 數加速近 2000 倍。
兩種快取策略:
- 離線預計算(offline):例如 web app 預先填滿快取,使用者請求時直接回傳。地圖服務的最短路徑就常用這招。
- 線上動態(online):例如 Bitcoin 地址餘額查詢,第一次計算後存入快取,下次直接讀。
快取需要替換策略(cache replacement policy):FIFO、LRU 都是常見選擇。FIFO 是不錯的起點。
原則 5:少即是多(Less Is More)#
問題太難解就簡化問題。Google 不真的找出每個查詢的「最佳答案」——它用啟發式(heuristics,如 PageRank)找出夠好的網頁。
簡化方式:
- 整個瓶頸功能直接砍掉
- 換成更簡單的版本
- 砍掉 1 個昂貴功能,換 10 個便宜功能(80/20)
- 機會成本:放棄一個重要功能,去做更重要的功能
若 1% 使用者使用某功能、卻有 100% 感受到延遲——這就是該砍的時候。
原則 6:知道何時停(Know When to Stop)#
每次優化得到的邊際效益會遞減。問自己:
- 使用者真正需要多快?
- 他們感受得到目前版本與優化版本的差別嗎?
- 有人在抱怨慢嗎?
若沒人感受到差別,就停。
結論#
過早最佳化的判準很簡單:「這次優化帶來的價值,是否大於它消耗的開發資源?」
- 能為千人省下時間或金錢 → 不算過早
- 對使用者或程式設計師生活毫無感知差異 → 過早
實作策略:
- 先寫乾淨、可讀的程式,不要管效能
- 用測量工具找出瓶頸
- 用真實使用者回饋判斷哪些值得優化
- 達到使用者可接受的閾值就停
下一章將進入程式設計師最強的盟友——心流(Flow)。