為什麼乾淨的程式碼很重要#
**乾淨的程式碼(clean code)**就是「容易讀、容易理解、容易修改」的程式碼。它精簡,但不為了精簡犧牲可讀性。
「簡單」與「乾淨」是兩個概念:簡單關注的是避免複雜度;乾淨進一步處理不可避免的複雜度——透過註解、命名、規範來管理它。
讀寫比 10:1#
馬丁(Robert C. Martin)在《Clean Code》指出:寫程式時花在讀舊程式碼的時間,是寫新程式的 10 倍以上。 因此「讓程式碼好讀,就是讓它好寫」。
越寫越慢的曲線#
每加一行程式碼,可能會:
- 影響先前已寫的所有行(效能、相依性)
- 引入 bug(機率為 c),找它要遍歷整個專案
- 為了向後相容而要再寫更多行
所以「寫一行的成本」會隨專案大小超線性增長。骯髒程式短期較快,長期則被乾淨程式逆轉——重點在於「未來的你」與「同事的你」能不能接手。
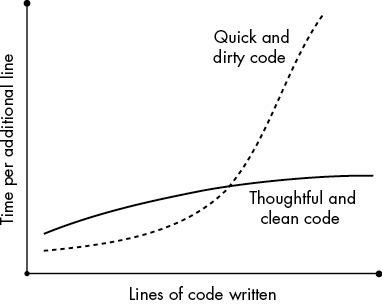
Figure 4-1: 乾淨程式碼提升程式庫的可擴展性與可維護性。
1962 年 NASA 發射前往金星的火箭時,原始碼少了一個連字號(hyphen)就觸發自毀指令,損失超過 1800 萬美元當時值。乾淨程式不只是美學問題,是避免災難的必要條件。
17 條原則#
作者將其攻讀博士期間「分散式圖處理系統」的痛苦經驗收斂成下列 17 條原則。改善程式碼的整體過程稱為重構(refactoring)——它必須是排定的開發流程一環,而非偶爾的興起。
原則 1:先看大局(Think About the Big Picture)#
退一步思考軟體架構,問自己:
- 模組能不能合併?檔案能不能拆?
- 大塊單體(monolithic)程式碼難讀;切太碎也難追蹤——存在一個倒 U 型最佳點。
- 能不能抽成函式庫?能不能改用既有函式庫?
- 能不能加快取避免重算?
- 能不能換更直接的演算法?
- 是不是有早期過早最佳化該移除?
- 換一個更適合此問題的程式語言?
原則 2:站在巨人的肩上(Stand on the Shoulders of Giants)#
不要重造輪子。一行 import 就能取用數百萬程式設計師調校過的函式庫——更快、bug 更少、更短。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)自己刻 KMeans 要好幾小時、50 多行,且容易出錯。
原則 3:寫給人看,不是寫給機器看#
「任何笨蛋都能寫出電腦看得懂的程式;好的程式設計師寫出人看得懂的程式。」——Martin Fowler
對比兩段語意相同的程式:
# 不好的命名
xxx = 10000
yyy = 0.1
zzz = 10
for iii in range(zzz):
print(xxx * (1 + yyy)**iii)# 有意義的命名
investments = 10000
yearly_return = 0.1
years = 10
for year in range(years):
print(investments * (1 + yearly_return)**year)原則 4:取對名字(Use the Right Names)#
- 描述性:用
usd_to_eur(amount)而非f(x)。 - 不模糊:
dollar_to_euro不夠精確(美元?加幣?澳幣?),用usd_to_eur。 - 可發音:
cstmr_lst雖簡短卻讀不出來,customer_list多幾個字母值得。 - 用具名常數,避免魔術數字(magic numbers):把
0.9提升為CONVERSION_RATE = 0.9。
原則 5:遵循標準、保持一致#
每個語言都有風格規範。Python 是 PEP 8 ↗:4 空格縮排、命名規則、行長限制等。
用 linter / IDE 自動指出違規,比硬讀風格指南有效得多——例如 Python 的
black、PyCharm 內建檢查器。
原則 6:使用註解#
程式語言有時無法直接表達意圖(例如正則表達式),這時註解就是救星:
# Find all words starting with character 'f'.
f_words = re.findall(r'\bf\w+\b', text)註解的其他用途:
- 為一段邏輯提供概觀(如
# Process next order、# Ship order & confirm customer) - 警告潛在後果——「執行此函式會送出一艘 $1,569,420 的遊艇!」
原則 7:避免不必要的註解#
Google 的招募官指出某位學生「註解太多」是扣分。冗餘註解是 code smell。
- 別寫行內的廢話註解(命名好就不需要)
- 別解釋顯而易見的事(
for year in range(years)不需要# Go over each year) - 不要把舊程式註解掉——直接刪除,版本控制會記住
- 若語言支援 docstring,優先用文件字串而非註解
原則 8:最小驚奇原則(Principle of Least Surprise)#
系統元件的行為應該符合使用者預期。Google 一打開游標就在搜尋框裡。命名也是:使用者輸入欄就叫 user_input,別叫 var_x。
原則 9:不要重複自己(Don’t Repeat Yourself, DRY)#
# WET:we enjoy typing
miles = 100
kilometers = miles * 1.60934
distance = 20 * 1.60934# DRY
def miles_to_km(miles):
return miles * 1.60934未來想調整精度,DRY 版本只改一處;意圖也清楚——miles_to_km(20) 比 20 * 1.60934 直白得多。
原則 10:單一責任原則(Single Responsibility Principle)#
「責任」就是「修改的理由」。每個類別、每個函式應該只有一個修改的理由。
電子書範例違反此原則:Book 類別同時負責「資料模型」與「列印到裝置」——兩個修改理由共用一個類別。修正後:
Book:只管書本資料Printer:只管把書印到裝置上
資料建模與資料呈現解耦,維護更容易。
原則 11:測試(Test)#
測試驅動開發(test-driven development, TDD)是現代開發的核心。常見類型:
- 單元測試(unit test):每個函式的輸入/輸出對應
- 使用者驗收測試(user acceptance test):在受控環境讓目標使用者試用
- 冒煙測試(smoke test):交給測試團隊前的粗略檢驗
- 效能測試(performance test):例如 Netflix 上線新功能前必驗載入時間
- 可擴展性測試(scalability test):1000 req/min vs. 2 req/min 的差異
別過度測試(over-engineer,見原則 14):測試「Netflix 能否處理 1000 億串流裝置」毫無意義——地球上只有 70 億人。
原則 12:小即是美(Small Is Beautiful)#
把功能切成小函式,每個只做一件事。新手或懶惰中手最容易寫出上帝物件(God object)——一個大塊塞滿所有功能。
寫多個小函式時,每行成本接近線性增長;單體巨塊則指數增長。
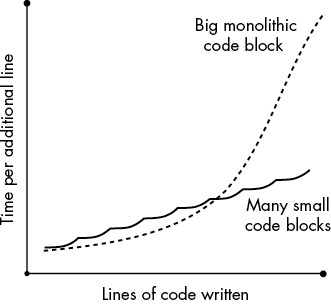
Figure 4-2: 單體大塊程式碼成本指數增長,多個小函式則接近線性。
原則 13:迪米特法則(The Law of Demeter)#
「只跟你的朋友說話。」——避免方法鏈(method chaining)
a.b().c()。
衝咖啡的例子:Person 不該透過 coffee_cup.get_creator_machine().get_price() 直接跟 Coffee_Machine 對話。改為讓 Coffee_Cup.get_cost_per_cup(cups) 內部去問機器,Person 只跟 Coffee_Cup 互動。
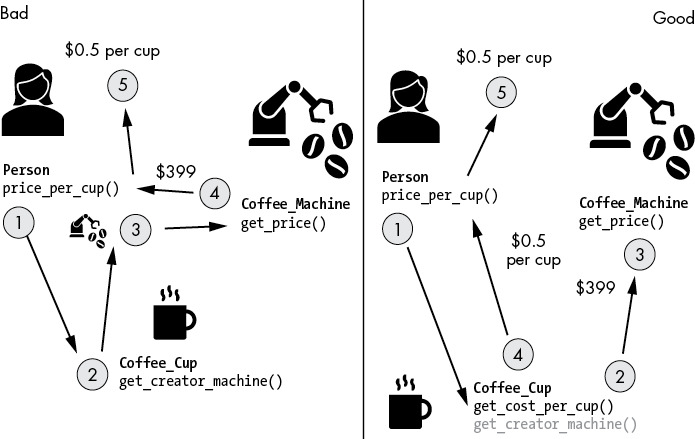
Figure 4-3: 迪米特法則——只跟朋友說話,最小化依賴。
數學上:n 個物件、每個只跟 k 個朋友互動,相依數為 k·n(線性);不限制則為超線性,雙倍物件可能四倍依賴。迪米特法則讓應用優雅地擴展。
原則 14:你不會用到(You Ain’t Gonna Need It, YAGNI)#
只在 100% 確定需要時才寫。今天的需求,今天寫;未來真的需要再加。
最簡潔的程式就是一個空檔案。從這裡開始,問自己「真的需要嗎?」。
過度工程化(overengineering)是隱形殺手。作者就曾為了把 KMeans 性能再榨幾個百分點,花 80% 時間換 20% 改善——而且其實根本不需要那 20%。先用最簡單的方法建立基準,再評估真正值得的優化。
原則 15:不要太多層縮排#
巢狀越深越難讀。透過提早 return / 條件合併等方式攤平:
# Before:多層巢狀
def if_confusion(x, y):
if x>y:
if x-5>0:
...
if y==y+y:
return "A"# After:扁平
def if_confusion(x, y):
if x>y and x>5 and y==0: return "A"
if x>y and x>5: return "B"
...
return "H"即便有些重複條件,扁平版本仍遠比深巢狀好讀。
原則 16:使用度量#
終極(非正式)指標:WTFs per minute——讀者每分鐘罵髒話的次數。
實務上可用 NPath complexity、圈複雜度(cyclomatic complexity)。JetBrains 等 IDE 有外掛即時計算。重點不在挑哪個指標,而在於警覺地剔除複雜度。
原則 17:童子軍法則與重構#
「離開營地時要比來時更乾淨。」(Boy Scout Rule)
- 每經手一段程式,順手清理。
- 不是過度最佳化(原則 14),而是降低複雜度——回報遠超投入。
- 重構的方法之一:向同事解釋你的程式碼。常常解釋到一半就會發現多餘的設計。
- 若內向,就跟橡皮鴨講——這就是著名的橡皮鴨除錯法(rubber duck debugging)。
結論#
乾淨程式碼降低複雜度、提升生產力與可維護性。記住三個核心:
- 善用函式庫降低 clutter
- 取好名字、遵守規範減少未來閱讀者的摩擦
- 單一責任、最小依賴、避免方法鏈讓系統能優雅擴展
寫乾淨程式的關鍵心法:寫給人看,不是寫給機器看(code for humans, not machines)。
下一章將進入另一個核心議題——過早最佳化是萬惡之源。